वर्तमान और वोल्टेज के लिए बिजली की गणना
जैसा कि आप जानते हैं, विद्युत वोल्टेज का अपना उपाय होना चाहिए, जो प्रारंभ में उस मूल्य से मेल खाता है जो ...
जानकारी संग्रहीत करने और संचारित करने के तकनीकी साधनों के आगमन के साथ, नए विचार और कोडिंग तकनीक उभरी। दूरी पर जानकारी संचारित करने का पहला तकनीकी माध्यम टेलीग्राफ था, जिसने 1837 में अमेरिकी सैमुअल मोर्स द्वारा आविष्कार किया था। एक टेलीग्राफ संदेश वायर द्वारा एक टेलीग्राफ उपकरण से दूसरे टेलीग्राफ उपकरण तक प्रेषित विद्युत सिग्नल का एक अनुक्रम है। इन तकनीकी परिस्थितियों में एस मोर्स ने टेलीग्राफ लाइनों के माध्यम से प्रेषित एक संदेश को एन्कोड करने के लिए केवल दो प्रकार के सिग्नल - छोटे और लंबे - उपयोग करने के विचार के लिए नेतृत्व किया।
सीज़र साइफर के आविष्कार के बाद से यह क्रिप्टोलॉजी में सबसे बड़ी खोज है। राल्फ मर्कले, मार्टिन हेलमैन और व्हिटफील्ड डिफी। साथ में वे एक निश्चित प्रकार के गणितीय फ़ंक्शन पर विचार करते हैं: एक तरफा कार्य, यानी, कार्य जो उलटा नहीं होते हैं। याद रखें कि अधिकांश फ़ंक्शन उलटा हो सकते हैं, उन्हें एक दिशा में बनाया जा सकता है, और फिर रद्द कर दिया जाता है: यदि आप संख्या को दोगुना करते हैं, उदाहरण के लिए, आप आसानी से अपने जुड़वां से मूल संख्या पा सकते हैं। आइए अंकगणितीय मॉड्यूल पर जाएं, एक-तरफा कार्यों में समृद्ध एक डोमेन, एक ऐसा क्षेत्र जिसमें गणितज्ञ एक चक्र में व्यवस्थित संख्याओं का एक सीमित सेट मानते हैं, जैसे घड़ी में घड़ी।
इस एन्कोडिंग विधि को मोर्स कोड कहा जाता है। इसमें, वर्णमाला का प्रत्येक अक्षर लघु संकेतों (बिंदुओं) और लंबे सिग्नल (डैश) के अनुक्रम द्वारा एन्कोड किया जाता है। पत्र एक दूसरे से विराम से अलग होते हैं - सिग्नल की कमी।
सबसे प्रसिद्ध टेलीग्राफ संदेश संकट संकेत "एसओएस" है ( एस एवेन्यूहे उरएस ouls - हमारी आत्माओं को बचाओ)। यहां अंग्रेजी वर्णमाला पर लागू मोर्स कोड में ऐसा लगता है:
घड़ी के नीचे, जिसकी घड़ी मॉड्यूलो 12 है। इस घड़ी पर, 3 4 की गणना करने के लिए, हम 3 से शुरू होते हैं और 4 अंक स्थानांतरित करते हैं, जैसे सामान्य अंकगणित में। लेकिन 10 4 की गणना करने के लिए, हम वहां पहुंचने के लिए घड़ी की पूरी बारी लेते हैं। रोजमर्रा की जिंदगी में, हम अक्सर मॉड्यूलर अंकगणित का सहारा लेते हैं। इसलिए, अगर सुबह 9 बजे हम नियुक्ति करते हैं, जो आयोजित किया जाएगा। 6 घंटों के बाद हम कहते हैं कि यह बैठक 3 बजे और 3 बजे भी होगी।
मॉड्यूलर गणना को सरल बनाने के लिए, गणितज्ञ पहले पारंपरिक अंकगणित में गणना करते हैं, परिणाम मॉड्यूल को विभाजित करते हैं, और शेष विभाजन इस परिणाम का परिणाम है। मॉड्यूलो अंकगणित किए गए कार्यों को कभी-कभी एक-तरफा फ़ंक्शंस में परिवर्तित किया जाता है। यह सामान्य अंकगणित और मॉड्यूलो अंकगणितीय में एक साधारण कार्य की तुलना करके देखा जा सकता है।
–––
तीन अंक (अक्षर एस), तीन डैश (अक्षर ओ), तीन अंक (अक्षर एस)। दो विराम एक दूसरे से पत्र अलग करते हैं।
मोर्स कोड की विशेषता विशेषता है विभिन्न अक्षरों के परिवर्तनीय लंबाई कोडयही कारण है कि मोर्स कोड कहा जाता है गैर वर्दी कोड। पाठ में अधिक बार दिखाई देने वाले पत्र दुर्लभ अक्षरों की तुलना में एक छोटा कोड होता है। उदाहरण के लिए, "ई" अक्षर का कोड एक बिंदु है, और ठोस चरित्र के कोड में छह वर्ण होते हैं। यह पूरे संदेश की लंबाई को कम करने के लिए किया जाता है। लेकिन पत्र कोड की परिवर्तनीय लंबाई की वजह से, पाठ में एक दूसरे से अक्षरों को अलग करने की समस्या है। इसलिए, अलगाव के लिए एक विराम (पास) का उपयोग करना आवश्यक है। नतीजतन, मोर्स टेलीग्राफ वर्णमाला तीन गुना है, के बाद से यह तीन अक्षरों का उपयोग करता है: डॉट, डैश, छोड़ें।
यह बहुत कम स्पष्ट मॉड्यूलो अंकगणित है। उनका तर्क है कि एलिस और बॉब ईव के अवलोकन के बावजूद बैठक के बिना एक कुंजी पर सहमत हो सकते हैं। एलिस और बॉब अब 5 वें समारोह में सहमत हुए हैं। फिर वे समानांतर में काम करते हुए बैठक के बिना एक गुप्त कुंजी बनाने की प्रक्रिया शुरू कर सकते हैं। हेलमैन के फैसले से ऐलिस और बॉब ने सार्वजनिक बातचीत के दौरान एक रहस्य की बातचीत की अनुमति दी।
लेकिन अगर यह कुंजी विनिमय समाधान क्रिप्टोग्राफी के इतिहास में एक क्रांति है, तो यह अभी भी सही है। यदि ऐलिस बॉब को एन्क्रिप्टेड संदेश भेजना चाहता है, तो उसे फोन या ईमेल द्वारा बॉब के साथ बातचीत करने की ज़रूरत है। शायद इस समय सो रहे हैं, और ऐलिस को उसकी जागृति के लिए इंतजार करना है, जो ऑपरेशन को धीमा कर देता है।
वर्दी टेलीग्राफ कोड 1 9वीं शताब्दी के अंत में फ्रांसीसी जीन-मॉरीस बोडो ने इसका आविष्कार किया था। यह केवल दो अलग-अलग प्रकार के सिग्नल का इस्तेमाल करता था। इससे कोई फ़र्क नहीं पड़ता कि आप उन्हें कैसे कॉल करते हैं: डॉट और डैश, प्लस और माइनस, शून्य और एक। ये दो अलग-अलग विद्युत सिग्नल हैं। सभी पात्रों के कोड की लंबाई समान है। और पांच के बराबर है। इस मामले में, अक्षरों को एक-दूसरे से अलग करने की कोई समस्या नहीं है: पांच संकेतों में से प्रत्येक पाठ का संकेत है। इसलिए, एक पास की आवश्यकता नहीं है।
जबकि मार्टिन हेलमैन अपने मुख्य विनिमय समाधान का विकास कर रहे हैं, डिफी, एक अलग पथ के बाद, एक नए प्रकार के अंकों के बारे में सोच रहा है, जिसमें असममित कुंजी शामिल है। इसके विपरीत, एक विषम कुंजी प्रणाली में, प्रेषक द्वारा उपयोग की जाने वाली एन्क्रिप्शन कुंजी और संदेश प्राप्तकर्ता द्वारा उपयोग की जाने वाली डिक्रिप्शन कुंजी अलग-अलग होती है। यह अवधारणा क्रांतिकारी है, और ऐलिस अपनी मुख्य जोड़ी बना सकती है। एन्क्रिप्शन कुंजी और डिक्रिप्शन कुंजी, यह गुप्त डिक्रिप्शन कुंजी संग्रहीत करता है, जिसे यह अपनी निजी कुंजी कहता है, लेकिन यह अपनी एन्क्रिप्शन कुंजी संचारित कर सकता है ताकि हर कोई इसे एक्सेस कर सके।
जीन-मॉरिस एमिले बोडो (1845-1903), फ्रांस
बोडो कोड बाइनरी एन्कोडिंग जानकारी की तकनीक के इतिहास में पहला है। इस विचार के लिए धन्यवाद, टाइपराइटर की उपस्थिति होने पर प्रत्यक्ष प्रिंटिंग टेलीग्राफ बनाना संभव था। किसी निश्चित पत्र के साथ एक कुंजी दबाकर एक संबंधित पांच-पल्स सिग्नल उत्पन्न होता है, जो एक संचार रेखा के माध्यम से प्रसारित होता है। इस सिग्नल के प्रभाव में प्राप्त करने वाला उपकरण एक ही पत्र को पेपर टेप पर प्रिंट करता है।
यदि बॉब ऐलिस को एक संदेश भेजना चाहता है, तो वह एलिस की सार्वजनिक कुंजी का उपयोग अपने संदेश को एन्क्रिप्ट करने के लिए करेगा, जिसे वह ऐलिस भेजता है, और ऐलिस संदेश को डिक्रिप्ट करने के लिए अपनी निजी कुंजी का उपयोग करेगा। कोई भी ऐलिस को अपनी सार्वजनिक कुंजी का उपयोग करके एन्क्रिप्टेड संदेश भेज सकता है, और ऐलिस को केवल डिक्रिप्ट करने के लिए केवल एक गुप्त कुंजी की आवश्यकता होती है।
बॉब को अब इस संदेश के लिए एलिस के साथ अपना संदेश एन्क्रिप्ट करने की प्रतीक्षा करने की आवश्यकता नहीं है और इसके विपरीत। इसके विपरीत, ऐलिस और बॉब अपनी सार्वजनिक कुंजी प्रकाशित करने के लिए स्वतंत्र हैं, क्योंकि इन्हें संदेशों को डिक्रिप्ट करने के लिए उपयोग नहीं किया जाता है। किसी संदेश के प्राप्तकर्ता को डिक्रिप्ट करने के लिए, केवल उसकी निजी कुंजी की आवश्यकता होती है, जैसा कि नाम का तात्पर्य है, उसे अकेले ही जाना जाता है। दरअसल, ऐलिस एक सार्वजनिक कुंजी बनाने में सक्षम होना चाहिए, जो एक ऐसा कार्य है जो उन्हें भेजे गए संदेशों के प्रेषकों को एन्क्रिप्ट करने की अनुमति देता है, और एक गुप्त गुप्त कुंजी जो उन्हें अकेले, उन्हें डिक्रिप्ट करने की अनुमति देती है।
आधुनिक कंप्यूटरों में, ग्रंथों को एन्कोड करने के लिए वर्दी बाइनरी कोड का भी उपयोग किया जाता है।
कोडिंग जानकारी का विषय विद्यालय में कंप्यूटर विज्ञान के अध्ययन के सभी चरणों में पाठ्यक्रम में प्रस्तुत किया जा सकता है।
प्रोपेडियटिक कोर्स में, छात्रों को अक्सर ऐसे कार्यों की पेशकश की जाती है जो डेटा के कंप्यूटर कोडिंग से संबंधित नहीं हैं और एक अर्थ में, एक गेम फॉर्म हैं। उदाहरण के लिए, मोर्स कोड कोड तालिका के आधार पर, आप दोनों कोडिंग कार्यों (मोर्स कोड का उपयोग करके रूसी पाठ को एन्कोड करें) और डीकोडिंग (मोर्स कोड के साथ एन्कोड किए गए टेक्स्ट को डिक्रिप्ट) की पेशकश कर सकते हैं।
यह फ़ंक्शन एक-तरफा होना चाहिए लेकिन कुछ स्थितियों के तहत ऐलिस द्वारा उलटा होना चाहिए। ये दो चाबियां एक-दूसरे से नहीं ली जा सकती हैं। लेकिन निर्णय का इंतजार है। मुख्य वितरण की समस्या पर काबू पाने, एक विषम आंकड़ा सैद्धांतिक बना हुआ है। समस्या को हल करना अन्य स्रोतों से आता है। तीनों ने शुरुआत में यह साबित करने के लिए डिफी के शोध पर ध्यान केंद्रित किया कि सार्वजनिक कुंजी क्रिप्टोसिस्टम विकसित करना असंभव था। वे नहीं पता कि यह प्रणाली वास्तव में संभव है।
असममित एन्क्रिप्शन संरक्षित है। बॉब परिणाम देता है और सुरक्षित रूप से ऐलिस को भेज सकता है क्योंकि संदेश एक तरफा, गैरकानूनी तृतीय-पक्ष फ़ंक्शन के साथ एन्क्रिप्ट किया गया था। उसे संबोधित संदेशों को पढ़ने के लिए, ऐलिस के पास एक तत्व होना चाहिए जो उसे एक-तरफा फ़ंक्शन रद्द करने की अनुमति दे। संदेशों को डिक्रिप्ट करने के लिए केवल ऐलिस में यह जानकारी है। जब तक गुप्त कुंजी गुप्त बनी रहती है, तब तक सार्वजनिक कुंजी को स्ट्रीम किया जा सकता है, जिससे आप सुरक्षा के समझौता किए बिना अनिश्चित अवधि के लिए एक ही कुंजी जोड़ी का उपयोग कर सकते हैं।
ऐसे कार्यों को निष्पादित करने के लिए एन्क्रिप्टर के काम के रूप में व्याख्या की जा सकती है, जो विभिन्न सरल एन्क्रिप्शन कुंजी प्रदान करता है। उदाहरण के लिए, अल्फान्यूमेरिक, वर्णमाला में अपने सीरियल नंबर के प्रत्येक अक्षर को प्रतिस्थापित करता है। इसके अलावा, पाठ को पूरी तरह से एन्कोड करने के लिए, विराम चिह्न और अन्य प्रतीकों को वर्णमाला में दर्ज किया जाना चाहिए। छात्रों को लोअरकेस और लोअरकेस अक्षरों के बीच अंतर करने के तरीके के बारे में सोचने के लिए आमंत्रित करें।
तब बॉब संदेश को अपनी निजी कुंजी से डिक्रिप्ट कर सकता है। दरअसल, आज एल्गोरिदम कारक के सवाल को हल करने के लिए पर्याप्त तेज़ नहीं है। वह वेब पर होने वाले सबसे सुरक्षित लेन-देन के पीछे है। लगभग 40 वर्षों तक, इस नंबर को तोड़ने के सभी प्रयास विफल हो गए हैं। जासूसी के इतिहास में कई बार, कोडिंग सिस्टम, जिसे अपने उपयोगकर्ताओं द्वारा अचूक माना जाता है, वास्तव में अपने दुश्मनों के रहस्य से अवशोषित किया गया था।
मानववादी कंप्यूटर अभिव्यक्ति का आविष्कार शुरुआती नब्बे के दशक में किया गया था, जो कानूनी जानकारी और चिकित्सा सूचना विज्ञान के आवेदन के क्षेत्रों के समान ही अन्य भाषाओं में पहले से ही लोकुला पर आधारित है। यह विभिन्न मानवतावादी विषयों में कंप्यूटर विज्ञान को लागू करने के तरीकों और विधियों को संदर्भित करता है, जो सामान्य सांस्कृतिक पृष्ठभूमि और कुछ आवश्यक संपर्क बिंदुओं को ध्यान में रखते हुए मुख्य रूप से एकता विशेषताओं में पहचाना जा सकता है, जिन्हें डेटा के रूप में प्रस्तुत किया जाता है जिसे स्वचालित प्रसंस्करण का विषय बनने के लिए पहचाना और वर्णित किया जाना चाहिए, अनुसंधान विधियों के रूप में, और उभरती काम करने वाली परिकल्पनाओं को स्पष्ट और औपचारिक बनाने की आवश्यकता है।
ऐसे कार्यों को करने पर, छात्रों को इस तथ्य पर ध्यान देना चाहिए कि एक अलग चरित्र आवश्यक है - एक स्थान, क्योंकि कोड है असमतल: कुछ अक्षरों को एक अंक के साथ एन्क्रिप्ट किया जाता है, कुछ - दो के साथ।
छात्रों को कोड में अक्षरों को अलग किए बिना कैसे करना है, इस बारे में सोचने के लिए आमंत्रित करें। इन प्रतिबिंबों को एक समान कोड के विचार का कारण बनना चाहिए जिसमें प्रत्येक चरित्र को दो दशमलव अंकों से एन्कोड किया गया है: ए - 01, बी - 02, आदि।
मानविकी में कंप्यूटर विज्ञान के उपयोग में अनुभव के वर्षों ने दर्शाया है कि किसी विशेष शोध क्षेत्र में एक नियम के रूप में उपयोग किए जाने वाले तरीकों और विधियों के प्रभाव के परिणामस्वरूप अन्य या उससे कम संबंधित प्रभावों और परिणामों को अंतःविषय दृष्टि से प्रेरित किया जाता है। इसलिए, व्यापक रूप से साझा क्षेत्रों का अस्तित्व पर विचार करें जो कई मानववादी अनुप्रयोगों जैसे कि पाठ विश्लेषण, डेटाबेस और कंप्यूटर छवि प्रसंस्करण के संगठन के चौराहे को बनाते हैं।
इसके अलावा, ऐसे क्षेत्र हैं जो सभी मानववादी अनुसंधान के लिए बहुत महत्वपूर्ण हैं: अभिलेखीय दस्तावेज़ों का प्रबंधन और पुस्तकालयों और ग्रंथसूची संसाधनों का स्वचालन। मानव विज्ञान अध्ययन में स्वचालित गणना के लिए कंप्यूटर विज्ञान का परिचय, या अधिक सटीक रूप से, 1 9 40 के दशक के अंत तक पता लगाया जा सकता है, हालांकि द्वितीय विश्व युद्ध के आखिरी वर्षों में, क्रिप्टोग्राफिक संदेशों को संकलित करने और शुरुआती प्राथमिक कंप्यूटरों से अनुवाद करने के लिए भाषाई डेटा के प्रसंस्करण को स्वचालित करने के प्रयास किए गए थे।
एन्कोडिंग और एन्क्रिप्टिंग जानकारी के लिए कार्यों का चयन कई स्कूल पाठ्यपुस्तकों में उपलब्ध है।
बुनियादी विद्यालय के लिए बुनियादी सूचना विज्ञान पाठ्यक्रम में, कोडिंग का विषय काफी हद तक विभिन्न प्रकार के डेटा के कंप्यूटर में प्रतिनिधित्व के विषय से जुड़ा हुआ है: संख्याएं, ग्रंथ, छवियां, ध्वनि।
ऊपरी ग्रेड में, सामान्य शिक्षा या वैकल्पिक पाठ्यक्रम की सामग्री सूचना सिद्धांत के ढांचे में सी शैनन द्वारा विकसित कोडिंग के सिद्धांत से संबंधित मुद्दों को पूरी तरह से संबोधित किया जा सकता है। यहां कई रोचक समस्याएं हैं, जिनकी समझ छात्रों के गणितीय और प्रोग्रामर प्रशिक्षण के बढ़ते स्तर की आवश्यकता है। ये आर्थिक कोडिंग, सार्वभौमिक कोडिंग एल्गोरिदम, त्रुटि सुधार कोडिंग की समस्याएं हैं। विस्तार से, इनमें से कई प्रश्न पाठ्यपुस्तक "सूचना विज्ञान के गणितीय आधार" में प्रकट किए गए हैं।
कंप्यूटर विज्ञान के बारे में सही ढंग से बोलने में सक्षम होने के लिए, साठ के दशक का इंतजार करना आवश्यक है, जब फ्रांस में शब्द बनाया गया था और तेजी से अंतरराष्ट्रीय स्तर पर फैल गया था न केवल तकनीकी नवाचारों को संदर्भित करने के लिए रखा गया था, जो डिजिटल कंप्यूटरों को गतिविधि और अनुसंधान के सभी क्षेत्रों के लिए उपयोग करने की इजाजत देता था, लेकिन सबसे पहले, सैद्धांतिक ज्ञान की जटिलता जो मशीनों के संचालन के लिए पूर्व शर्त बनाती है, और लगातार लागू पद्धतियों के विकास को सुनिश्चित करती है।
कंप्यूटिंग की उत्पत्ति में मुख्य भूमिका गणित, तर्क से, संचार और सूचना के विज्ञान से, और विशेष रूप से, भाषाविज्ञान से किया गया था। कंप्यूटर विज्ञान और मानविकी जैसे दो दूर-दूर के क्षेत्रों की बैठक के कारण होने वाले प्रभावों पर विचार करना दिलचस्प है। "बहस मशीनों" की भूमिका में विचार किए गए सूचना विज्ञान कंप्यूटर प्रौद्योगिकियों के दृष्टिकोण से अधिक है, इसकी तार्किक और दार्शनिक जड़ों पर पुनर्विचार करने का अवसर लेता है और भाषाओं के सिद्धांत के विकास में निर्णायक योगदान प्राप्त करता है; शक्तिशाली और सटीक तार्किक और तकनीकी उपकरणों का उपयोग करने वाले मानववादी विषयों को प्रोत्साहन और प्रोत्साहन मिलता है ताकि उनके शोध और विश्लेषण विधियां सुसंगत और औपचारिक हों।
संख्या प्रणाली - यह संख्याओं का उपयोग करने और संख्याओं में हेरफेर करने के लिए संबंधित नियमों का प्रतिनिधित्व करने का एक तरीका है।। पहले से मौजूद विभिन्न संख्या प्रणालियों और जो हमारे समय में उपयोग किए जाते हैं उन्हें विभाजित किया जा सकता है nonpositional और अवस्था का. संख्याओं को लिखते समय वर्णित वर्णकहा जाता है संख्या में
इस बातचीत से, नए शोध उपकरण बनाए जाते हैं, जो बदले में, स्वायत्त परिणामों को संसाधित करने के लिए नए ज्ञान और स्रोत परिणामों की पहचान करने में सक्षम होते हैं और साथ ही साथ मूल के दो अलग-अलग क्षेत्रों में योगदान देते हैं। उदाहरण के लिए, शब्दावली, सामग्री, वाक्यविन्यास और पाठ की शैली का विश्लेषण करने या स्वचालित अनुवाद के लिए नियमों को औपचारिक बनाना; मानववादी अनुसंधान, अनुवाद की सहायक प्रणाली या ध्वनि और भाषण के स्वचालित संश्लेषण के विभिन्न क्षेत्रों में विशेषज्ञ प्रणालियों के कार्यान्वयन के लिए यह एक अनिवार्य आवश्यकता है।
गैर-संख्यात्मक संख्या प्रणाली अंक का मूल्य संख्या में स्थिति से स्वतंत्र है.
एक गैर-संख्यात्मक संख्या प्रणाली का एक उदाहरण रोमन प्रणाली (रोमन अंक) है। रोमन प्रणाली में, लैटिन अक्षरों को संख्याओं के रूप में उपयोग किया जाता है।
उदाहरण 1 संख्या CCXXXII में दो सौ, तीन दर्जन और दो इकाइयां होती हैं और दो सौ तीस बराबर होती हैं।
कम्प्यूटेशनल भाषाविज्ञान दो क्षेत्रों के मूल कौशल के अभिसरण का मुद्दा है, लेकिन इसी तरह की घटनाएं भी शैक्षणिक, इतिहास और पुरातत्व जैसे क्षेत्रों में देखी जाती हैं, जो कि "मूल विकास" की विशेषताओं का प्रदर्शन करने वाली नई मल्टीमीडिया क्षमता को समझने में अधिक सक्षम हो सकती है।
ट्यूरिंग वॉन न्यूमैन ने यह विश्वास जीता कि इस कंप्यूटर को न केवल "कंप्यूटर" के रूप में माना जाना चाहिए, बल्कि एक ऐसी मशीन के रूप में जिसे विज्ञान के सभी क्षेत्रों में मानविकी और सामाजिक विज्ञान समेत अनुसंधान विधियों और अनुसंधान गतिविधियों में पुनर्विचार करना होगा। । प्राचीन काल में गणित और खगोल विज्ञान के इतिहास में एक विशेषज्ञ नियोगेबॉयर का उपयोग सूर्य से, चंद्रमा और नग्न आंखों के साथ मनाए गए ग्रहों से जुड़े इफेमेरिस को स्वचालित रूप से संकलित करने के लिए किया जाता था।
रोमन संख्याओं में, संख्याएं अवरोही क्रम में बाएं से दाएं लिखी जाती हैं। इस मामले में, उनके मूल्य जोड़ते हैं। यदि बाईं ओर एक छोटा अंक लिखा गया है और दाईं ओर एक बड़ा अंक है, तो उनके मान घटाए जाते हैं।
उदाहरण 2
छठी = 5 + 1 = 6; चतुर्थ = 5 - 1 = 4।
उदाहरण 3
MCMXCVIII = 1000 + (-100 + 1000) +
+ (–10 + 100) + 5 + 1 + 1 + 1 = 1998.
स्थितित्मक संख्या प्रणाली रिकॉर्ड संख्या में अंकों द्वारा निर्दिष्ट मूल्य इसकी स्थिति पर निर्भर करता है। इस्तेमाल किए गए अंकों की संख्या को स्थितित्मक संख्या प्रणाली का आधार कहा जाता है।
इन संख्यात्मक सारणी, जिनमें पूर्व निर्धारित अंतराल पर सितारों के निर्देशांक होते हैं और एक-दूसरे के बराबर होते हैं, का उपयोग खगोलीय अभिलेखों के लिए किया जा सकता है और इसके परिणामस्वरूप, 600 ईस्वी की ऐतिहासिक घटनाएं यह ध्यान रखना दिलचस्प है कि, आवेदन के मूल और असामान्य पहलू को ध्यान में रखते हुए, वॉन न्यूमैन कर्मचारियों को इलेक्ट्रॉनिक कंप्यूटर प्रोजेक्ट के लेनदारों को प्रमाणित करने की आवश्यकता है, जो एक वास्तविक संयुक्त उद्यम है, मानदंड जो इस एप्लिकेशन की पसंद को उचित ठहराते हैं: कम्प्यूटेशनल ऑपरेशंस की संख्या जो कंप्यूटर के बिना पूरी तरह से अटूट है; अत्यधिक सटीक गणनाओं के साथ प्रयोग करने में रुचि, परिणामों की गैर वाणिज्यिक प्रकृति और निरंतर वैज्ञानिक मूल्य का प्रतिनिधित्व करेंगे।
आधुनिक गणित में उपयोग की जाने वाली संख्या प्रणाली है स्थिति दशमलव प्रणाली। इसका आधार दस है, क्योंकि दस अंकों का उपयोग कर किसी भी संख्या रिकॉर्ड करें:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
किसी भी बहु-अंक संख्या के उदाहरण से इस प्रणाली की स्थितित्मक प्रकृति को समझना आसान है। उदाहरण के लिए, 333 नंबर में, पहले तीन का मतलब तीन सौ, दूसरा - तीन दर्जन, तीसरा - तीन इकाइयां।
आधार के साथ एक स्थितित्मक प्रणाली में संख्या रिकॉर्ड करने के लिए n होना चाहिए वर्णमाला के n अंक। आमतौर पर इसके लिए n < 10 используют n पहला अरबी अंक, और n \u003e 10 से दस अरबी अंकों में अक्षर जोड़ें। यहां कई प्रणालियों के अक्षरों के उदाहरण दिए गए हैं:
यदि आप उस सिस्टम का आधार निर्दिष्ट करना चाहते हैं जिस पर संख्या संबंधित है, तो इसे इस नंबर पर एक सबस्क्रिप्ट द्वारा जिम्मेदार ठहराया जाता है। उदाहरण के लिए:
101101 2, 3671 8, 3 बी 8 एफ 16।
आधार के साथ संख्या प्रणाली में क्ष (क्ष- संख्यात्मक प्रणाली) अंकों की इकाइयां संख्या की लगातार डिग्री होती हैं क्ष. क्ष किसी भी श्रेणी की इकाइयां अगली श्रेणी की इकाई बनाती हैं। संख्या में लिखने के लिए क्ष- न्यूनतम संख्या प्रणाली की आवश्यकता है क्ष विभिन्न वर्ण (अंक) संख्या 0, 1, ... का प्रतिनिधित्व करते हैं, क्ष - 1. रिकॉर्ड संख्या क्ष में क्ष- नोटेशन 10 है।
विस्तारित संख्या रिकॉर्ड
चलो अक - बेस के साथ सिस्टम में संख्या क्ष, एआई - रिकॉर्ड संख्या में मौजूद इस संख्या प्रणाली के अंक एक, n + 1 - किसी संख्या के पूर्णांक भाग के अंकों की संख्या मीटर - संख्या के आंशिक भाग के अंकों की संख्या:
दशमलव संख्या को अन्य संख्या प्रणालियों में कनवर्ट करना
पूर्ण अनुवाद
नियम: उसके लिए किसी भिन्न आधार के साथ एक पूर्णांक दशमलव संख्या को एक संख्या प्रणाली में परिवर्तित करने के लिए, आपको आवश्यकता है:
1) दशमलव संख्या प्रणाली में नई संख्या प्रणाली के आधार को व्यक्त करने और दशमलव अंकगणितीय के नियमों के अनुसार सभी अनुवर्ती कार्रवाइयों का उत्पादन करने के लिए;
2) नए नंबर सिस्टम के आधार पर दिए गए नंबर और परिणामी आंशिक उद्धरणों के विभाजन को लगातार निष्पादित करने तक, जब तक कि हम अधूरे भाग्यशाली नहीं होते, एक छोटा विभाजक;
3) परिणामस्वरूप अवशेष लाएं, जो नई संख्या प्रणाली में संख्या के अंक हैं, नई संख्या प्रणाली के वर्णमाला के अनुरूप;
4) अंतिम संख्या के साथ शुरू करने, इसे रिकॉर्ड करने, नई संख्या प्रणाली में एक संख्या बनाते हैं।
उदाहरण 1 संख्या 37 10 बाइनरी में कनवर्ट करें।
रिकॉर्ड संख्याओं में संख्याओं को इंगित करने के लिए प्रतीकों का उपयोग करें: एक 5 एक 4 एक 3 एक 2 एक 1 एक 0

यहां से: 37 10 = l00l0l 2
उदाहरण 2 दशमलव संख्या 315 को ऑक्टल और हेक्साडेसिमल में कनवर्ट करें:

यह निम्नानुसार है: 315 10 = 473 8 = 13 बी 16। याद रखें कि 11 10 = बी 16।
अब हम नियम बनाते हैं: एक दशमलव अंश को किसी अन्य आधार के साथ एक संख्या प्रणाली में बदलने के लिए, आपको आवश्यकता है:
1) नए सिस्टम के आधार पर दिए गए संख्या और कार्यों के परिणामस्वरूप आंशिक हिस्सों को लगातार गुणा करें जब तक कि उत्पाद का आंशिक हिस्सा शून्य न हो या नई संख्या प्रणाली में संख्या प्रतिनिधित्व की आवश्यक सटीकता प्राप्त हो;
2) नए संख्या प्रणाली के वर्णमाला के अनुसार, नए संख्या प्रणाली में संख्या के अंक हैं जो कार्यों के प्राप्त पूर्णांक भागों को लाने के लिए;
3) पहले उत्पाद के पूर्णांक भाग से शुरू होने वाले नए नंबर सिस्टम में संख्या का आंशिक भाग बनाने के लिए।
उदाहरण 3 0.1875 का दशमलव अंश बाइनरी, ऑक्टल और हेक्साडेसिमल सिस्टम में कनवर्ट करें।

यहां बाएं कॉलम में संख्याओं का पूर्णांक हिस्सा है, और दाईं ओर - fractional।
यहां से: 0.1875 10 = 0.0011 2 = 0.14 8 = 0.3 16
मिश्रित संख्याओं का अनुवादपूर्णांक और fractional भागों युक्त, दो चरणों में किया जाता है। मूल संख्या के पूर्णांक और fractional भागों को संबंधित एल्गोरिदम द्वारा अलग से अनुवादित किया जाता है। नई संख्या प्रणाली में संख्या के अंतिम रिकॉर्ड में, पूर्णांक भाग को fractional अल्पविराम (बिंदु) से अलग किया जाता है।
जानकारी संग्रहीत करने और संचारित करने के तकनीकी साधनों के आगमन के साथ, नए विचार और कोडिंग तकनीक उभरी। दूरी पर जानकारी संचारित करने का पहला तकनीकी माध्यम टेलीग्राफ था, जिसने 1837 में अमेरिकी सैमुअल मोर्स द्वारा आविष्कार किया था। एक टेलीग्राफ संदेश वायर द्वारा एक टेलीग्राफ उपकरण से दूसरे टेलीग्राफ उपकरण तक प्रेषित विद्युत सिग्नल का एक अनुक्रम है। इन तकनीकी परिस्थितियों में एस मोर्स ने टेलीग्राफ लाइनों के माध्यम से प्रेषित एक संदेश को एन्कोड करने के लिए केवल दो प्रकार के सिग्नल - छोटे और लंबे - उपयोग करने के विचार के लिए नेतृत्व किया।
सैमुअल फिनले ब्रीज़ मोर्स (17 9 1-1872), यूएसए
इस एन्कोडिंग विधि को मोर्स कोड कहा जाता है। इसमें, वर्णमाला का प्रत्येक अक्षर लघु संकेतों (बिंदुओं) और लंबे सिग्नल (डैश) के अनुक्रम द्वारा एन्कोड किया जाता है। पत्र एक दूसरे से विराम से अलग होते हैं - सिग्नल की कमी।
सबसे प्रसिद्ध टेलीग्राफ संदेश संकट संकेत "एसओएस" है ( एस एवेन्यू हेउर एसouls - हमारी आत्माओं को बचाओ)। यहां अंग्रेजी वर्णमाला पर लागू मोर्स कोड में ऐसा लगता है:
–––
तीन अंक (अक्षर एस), तीन डैश (अक्षर ओ), तीन अंक (अक्षर एस)। दो विराम एक दूसरे से पत्र अलग करते हैं।
यह आंकड़ा रूसी वर्णमाला पर लागू मोर्स कोड दिखाता है। कोई विशेष विराम चिह्न नहीं थे। वे शब्दों के साथ लिखे गए थे: "बिंदु" - बिंदु, "रोकें" - अल्पविराम, इत्यादि।
मोर्स कोड की विशेषता विशेषता है विभिन्न अक्षरों के परिवर्तनीय लंबाई कोडयही कारण है कि मोर्स कोड कहा जाता है गैर वर्दी कोड। पाठ में अधिक बार दिखाई देने वाले पत्र दुर्लभ अक्षरों की तुलना में एक छोटा कोड होता है। उदाहरण के लिए, "ई" अक्षर का कोड एक बिंदु है, और ठोस चरित्र के कोड में छह वर्ण होते हैं। यह पूरे संदेश की लंबाई को कम करने के लिए किया जाता है। लेकिन पत्र कोड की परिवर्तनीय लंबाई की वजह से, पाठ में एक दूसरे से अक्षरों को अलग करने की समस्या है। इसलिए, अलगाव के लिए एक विराम (पास) का उपयोग करना आवश्यक है। नतीजतन, मोर्स टेलीग्राफ वर्णमाला तीन गुना है, के बाद से यह तीन अक्षरों का उपयोग करता है: डॉट, डैश, छोड़ें।

वर्दी टेलीग्राफ कोड 1 9वीं शताब्दी के अंत में फ्रांसीसी जीन-मॉरीस बोडो ने इसका आविष्कार किया था। यह केवल दो अलग-अलग प्रकार के सिग्नल का इस्तेमाल करता था। इससे कोई फ़र्क नहीं पड़ता कि आप उन्हें कैसे कॉल करते हैं: डॉट और डैश, प्लस और माइनस, शून्य और एक। ये दो अलग-अलग विद्युत सिग्नल हैं। सभी पात्रों के कोड की लंबाई समान है।और पांच के बराबर है। इस मामले में, अक्षरों को एक-दूसरे से अलग करने की कोई समस्या नहीं है: पांच संकेतों में से प्रत्येक पाठ का संकेत है। इसलिए, एक पास की आवश्यकता नहीं है।

जीन-मॉरिस एमिले बोडो (1845-1903), फ्रांस
बोडो कोड बाइनरी एन्कोडिंग जानकारी की तकनीक के इतिहास में पहला है। इस विचार के लिए धन्यवाद, टाइपराइटर की उपस्थिति होने पर प्रत्यक्ष प्रिंटिंग टेलीग्राफ बनाना संभव था। किसी निश्चित पत्र के साथ एक कुंजी दबाकर एक संबंधित पांच-पल्स सिग्नल उत्पन्न होता है, जो एक संचार रेखा के माध्यम से प्रसारित होता है। इस सिग्नल के प्रभाव में प्राप्त करने वाला उपकरण एक ही पत्र को पेपर टेप पर प्रिंट करता है।
आधुनिक कंप्यूटरों में, ग्रंथों को एन्कोड करने के लिए एक समान बाइनरी कोड का भी उपयोग किया जाता है (देखें " टेक्स्ट एन्कोडिंग सिस्टम 2).
कोडिंग जानकारी का विषय विद्यालय में कंप्यूटर विज्ञान के अध्ययन के सभी चरणों में पाठ्यक्रम में प्रस्तुत किया जा सकता है।
प्रोपेडियटिक कोर्स में, छात्रों को अक्सर ऐसे कार्यों की पेशकश की जाती है जो डेटा के कंप्यूटर कोडिंग से संबंधित नहीं हैं और एक अर्थ में, एक गेम फॉर्म हैं। उदाहरण के लिए, मोर्स कोड कोड तालिका के आधार पर, आप दोनों कोडिंग कार्यों (मोर्स कोड का उपयोग करके रूसी पाठ को एन्कोड करें) और डीकोडिंग (मोर्स कोड के साथ एन्कोड किए गए टेक्स्ट को डिक्रिप्ट) की पेशकश कर सकते हैं।
ऐसे कार्यों को निष्पादित करने के लिए एन्क्रिप्टर के काम के रूप में व्याख्या की जा सकती है, जो विभिन्न सरल एन्क्रिप्शन कुंजी प्रदान करता है। उदाहरण के लिए, अल्फान्यूमेरिक, वर्णमाला में अपने सीरियल नंबर के प्रत्येक अक्षर को प्रतिस्थापित करता है। इसके अलावा, पाठ को पूरी तरह से एन्कोड करने के लिए, विराम चिह्न और अन्य प्रतीकों को वर्णमाला में दर्ज किया जाना चाहिए। छात्रों को लोअरकेस और लोअरकेस अक्षरों के बीच अंतर करने के तरीके के बारे में सोचने के लिए आमंत्रित करें।
ऐसे कार्यों को करने पर, छात्रों को इस तथ्य पर ध्यान देना चाहिए कि एक अलग चरित्र आवश्यक है - एक स्थान, क्योंकि कोड है असमतल: कुछ अक्षरों को एक अंक के साथ एन्क्रिप्ट किया जाता है, कुछ - दो के साथ।
छात्रों को कोड में अक्षरों को अलग किए बिना कैसे करना है, इस बारे में सोचने के लिए आमंत्रित करें। इन प्रतिबिंबों को एक समान कोड के विचार का कारण बनना चाहिए जिसमें प्रत्येक चरित्र को दो दशमलव अंकों से एन्कोड किया गया है: ए - 01, बी - 02, आदि।
एन्कोडिंग और एन्क्रिप्टिंग जानकारी के लिए कार्यों का चयन कई स्कूल पाठ्यपुस्तकों में उपलब्ध है।
बुनियादी विद्यालय के लिए बुनियादी सूचना विज्ञान पाठ्यक्रम में, कोडिंग का विषय विभिन्न प्रकार के डेटा के कंप्यूटर में प्रतिनिधित्व के विषय से अधिक जुड़ा हुआ है: संख्याएं, ग्रंथ, छवियां, ध्वनि (देखें " सूचना प्रौद्योगिकी” 2).
ऊपरी ग्रेड में, सामान्य शिक्षा या वैकल्पिक पाठ्यक्रम की सामग्री सूचना सिद्धांत के ढांचे में सी शैनन द्वारा विकसित कोडिंग के सिद्धांत से संबंधित मुद्दों को पूरी तरह से संबोधित किया जा सकता है। यहां कई रोचक समस्याएं हैं, जिनकी समझ छात्रों के गणितीय और प्रोग्रामर प्रशिक्षण के बढ़ते स्तर की आवश्यकता है। ये आर्थिक कोडिंग, सार्वभौमिक कोडिंग एल्गोरिदम, त्रुटि सुधार कोडिंग की समस्याएं हैं। विस्तार से, इनमें से कई प्रश्न पाठ्यपुस्तक "सूचना विज्ञान के गणितीय आधार" में प्रकट किए गए हैं।
प्रसंस्करण की जानकारी
सूचना प्रसंस्करण -सूचना की सामग्री या प्रस्तुति को व्यवस्थित रूप से बदलने की प्रक्रिया.
सूचना प्रसंस्करण कुछ विषय या वस्तु (उदाहरण के लिए, एक व्यक्ति या एक स्वचालित डिवाइस) द्वारा कुछ नियमों के अनुसार किया जाता है। उसे बुलाओगे सूचना प्रसंस्करण के निष्पादक.
बाहरी पर्यावरण के साथ बातचीत करने वाले कलाकार प्रसंस्करण, इससे प्राप्त होता है इनपुट जानकारीसंसाधित किया जा रहा है। प्रसंस्करण का परिणाम है आउटपुट जानकारीबाहरी पर्यावरण के लिए प्रेषित। इस प्रकार, बाहरी वातावरण इनपुट जानकारी के स्रोत और आउटपुट जानकारी के उपभोक्ता के रूप में कार्य करता है।
सूचना प्रसंस्करण कलाकार को ज्ञात कुछ नियमों के अनुसार होता है। प्रसंस्करण नियम, जो व्यक्तिगत प्रसंस्करण चरणों के अनुक्रम के वर्णन हैं, को सूचना प्रसंस्करण एल्गोरिदम कहा जाता है।
प्रसंस्करण एजेंट के पास एक प्रसंस्करण ब्लॉक होना चाहिए, जिसे हम एक प्रोसेसर और एक मेमोरी ब्लॉक कहते हैं, जिसमें संसाधित जानकारी और प्रसंस्करण नियम (एल्गोरिदम) दोनों संग्रहीत किए जाते हैं। उपरोक्त सभी आंकड़ों में schematically दिखाया गया है।
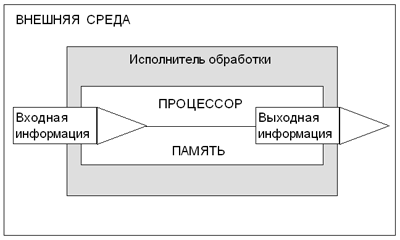
सूचना प्रसंस्करण योजना
एक उदाहरणएक छात्र, एक सबक में एक समस्या को हल करने, सूचना प्रसंस्करण करता है। उनके लिए बाहरी वातावरण सबक की स्थिति है। इनपुट जानकारी - समस्या की स्थिति, जिसे शिक्षक द्वारा पाठ की ओर अग्रसर किया जाता है। छात्र समस्या की स्थिति को याद करता है। याद रखने की सुविधा के लिए, वह एक नोटबुक - बाहरी स्मृति में नोट्स का उपयोग कर सकते हैं। शिक्षक के स्पष्टीकरण से, उन्होंने समस्या को हल करने के तरीके को याद किया (याद किया)। एक प्रोसेसर एक छात्र का सोच उपकरण है, जिसका उपयोग किसी समस्या को हल करने के लिए किया जाता है, इसे एक उत्तर - आउटपुट जानकारी प्राप्त होती है।
इस आंकड़े में प्रस्तुत योजना एक सामान्य सूचना प्रसंस्करण योजना है, भले ही प्रसंस्करण के निष्पादक कौन (या क्या): जीवित जीव या तकनीकी प्रणाली। यह कंप्यूटर में तकनीकी साधनों द्वारा लागू की गई योजना है। इसलिए, हम कह सकते हैं कि कंप्यूटर "लाइव" सूचना प्रसंस्करण प्रणाली का एक तकनीकी मॉडल है। इसमें प्रसंस्करण प्रणाली के सभी मुख्य घटक शामिल हैं: प्रोसेसर, मेमोरी, इनपुट डिवाइस, आउटपुट डिवाइस (देखें " कंप्यूटर डिवाइस " 2).
प्रतीकात्मक रूप में प्रस्तुत इनपुट जानकारी (संकेत, पत्र, संख्या, संकेत), कहा जाता है इनपुट डेटा। कलाकार द्वारा प्रसंस्करण के परिणामस्वरूप, आउटपुट डेटा। इनपुट और आउटपुट डेटा मूल्यों का एक सेट हो सकता है - व्यक्तिगत डेटा तत्व। यदि प्रसंस्करण गणितीय गणना में है, तो इनपुट और आउटपुट डेटा संख्याओं के सेट हैं। निम्नलिखित आंकड़ा एक्स: {एक्स1, एक्स2, …, xn) इनपुट डेटा का एक सेट इंगित करता है, और Y: {y1, y2, …, ym) - आउटपुट डेटा का सेट:

डेटा प्रोसेसिंग सर्किट
प्रसंस्करण सेट को बदलने के लिए है एक्स सेट में Y:
पी(एक्स) Y
यहां पी कलाकार द्वारा प्रयुक्त प्रसंस्करण नियमों को इंगित करता है। यदि सूचना प्रसंस्करण करने वाला व्यक्ति एक व्यक्ति है, तो प्रसंस्करण नियम जिसके लिए वह कार्य करता है वह हमेशा औपचारिक और स्पष्ट नहीं होता है। एक व्यक्ति औपचारिक रूप से रचनात्मक रूप से काम करता है। यहां तक कि वही गणित की समस्याएं भी वह विभिन्न तरीकों से हल कर सकती हैं। एक पत्रकार, वैज्ञानिक, अनुवादक और अन्य विशेषज्ञों का काम सूचना के साथ एक रचनात्मक काम है कि वे औपचारिक नियमों का पालन नहीं करते हैं।
औपचारिक नियमों को नामित करने के लिए जो सूचना प्रसंस्करण चरणों के अनुक्रम को निर्धारित करते हैं, कंप्यूटर विज्ञान एक एल्गोरिदम की अवधारणा का उपयोग करता है (देखें " एल्गोरिदम " 2)। गणित में एक एल्गोरिदम की अवधारणा दो प्राकृतिक संख्याओं के सबसे महान आम विभाजक (जीसीडी) की गणना के लिए एक प्रसिद्ध विधि से जुड़ी है, जिसे यूक्लिडियन एल्गोरिदम कहा जाता है। मौखिक रूप में, इसे इस प्रकार वर्णित किया जा सकता है:
1. यदि दो संख्याएं एक-दूसरे के बराबर होती हैं, तो उनका समग्र अर्थ जीसीडी के लिए लिया जाना चाहिए, अन्यथा चरण 2 पर जाएं।
2. यदि संख्याएं अलग हैं, तो उनमें से अधिक संख्याओं के बड़े और छोटे के अंतर से प्रतिस्थापित किया जाता है। चरण 1 पर लौटें।
यहां इनपुट डेटा दो प्राकृतिक संख्याएं हैं - एक्स1 और एक्स2. परिणाम Y - उनका सबसे बड़ा आम विभाजक। नियम ( पी) एक यूक्लिडियन एल्गोरिदम है:
यूक्लिडियन एल्गोरिदम ( एक्स1, एक्स2) Y
इस तरह के औपचारिक एल्गोरिदम आधुनिक कंप्यूटर के लिए प्रोग्राम करना आसान है। कंप्यूटर डेटा प्रसंस्करण का एक सार्वभौमिक कलाकार है। औपचारिक प्रसंस्करण एल्गोरिदम को कंप्यूटर की स्मृति में स्थित एक प्रोग्राम के रूप में दर्शाया जाता है। कंप्यूटर प्रसंस्करण नियमों के लिए ( पी) एक कार्यक्रम है।
"सूचना प्रसंस्करण" विषय को समझाते हुए, नई जानकारी प्राप्त होने और सूचना की प्रस्तुति के रूप में परिवर्तन से संबंधित दोनों प्रसंस्करण के उदाहरण देना आवश्यक है।
प्रसंस्करण के पहले प्रकार: नई जानकारी, ज्ञान की नई सामग्री प्राप्त करने से जुड़े प्रसंस्करण। इस प्रकार की प्रसंस्करण में गणितीय समस्याओं को हल करना शामिल है। इस प्रकार की सूचना प्रसंस्करण में तर्कसंगत तर्क लागू करके विभिन्न समस्याओं को हल करना शामिल है। उदाहरण के लिए, एक जांचकर्ता को कुछ सबूतों के अनुसार आपराधिक लगता है; एक व्यक्ति, परिस्थितियों का विश्लेषण, उसके आगे के कार्यों पर फैसला करता है; वैज्ञानिक प्राचीन पांडुलिपियों, आदि के रहस्य को उजागर करता है।
दूसरी प्रकार की प्रसंस्करण: प्रपत्र को बदलने के साथ जुड़े प्रसंस्करण, लेकिन सामग्री को नहीं बदल रहा है। इस प्रकार की सूचना प्रसंस्करण में, उदाहरण के लिए, एक भाषा से दूसरे भाषा में पाठ का अनुवाद शामिल है: फ़ॉर्म बदलता है, लेकिन सामग्री को संरक्षित किया जाना चाहिए। सूचना विज्ञान के लिए एक महत्वपूर्ण प्रकार की प्रसंस्करण कोडिंग है। कोडिंग - यह है जानकारी का परिवर्तन प्रतीकात्मक रूप में इसके भंडारण, संचरण, प्रसंस्करण के लिए सुविधाजनक है (देखें " कोडिंग” 2).
संरचना डेटा को दूसरी प्रकार की प्रसंस्करण के लिए भी जिम्मेदार ठहराया जा सकता है। संरचना एक विशिष्ट आदेश, सूचना भंडार में एक निश्चित संगठन के परिचय के साथ जुड़ा हुआ है। वर्णमाला क्रम में डेटा की व्यवस्था, तालिका या ग्राफ प्रतिनिधित्व का उपयोग करके कुछ वर्गीकरण मानदंडों के अनुसार समूहबद्ध करना संरचना के सभी उदाहरण हैं।
एक विशेष प्रकार की सूचना प्रसंस्करण है खोज. खोज कार्य आमतौर पर निम्नानुसार तैयार किया जाता है: जानकारी के कुछ भंडार हैं - सूचना सरणी (टेलीफोन निर्देशिका, शब्दकोश, ट्रेन अनुसूची, आदि), इसमें कुछ निश्चित संतुष्ट आवश्यक जानकारी प्राप्त करने की आवश्यकता है खोज शब्द(संगठन का फोन, अंग्रेजी में शब्द का अनुवाद, ट्रेन का प्रस्थान समय)। खोज एल्गोरिदम जानकारी के व्यवस्थित तरीके पर निर्भर करता है। यदि जानकारी संरचित है, तो खोज तेज है, इसे अनुकूलित किया जा सकता है (देखें " डेटा खोजें " 2).
प्रोपेड्यूटिक सूचना विज्ञान पाठ्यक्रम में, "ब्लैक बॉक्स" की समस्याएं लोकप्रिय हैं। प्रसंस्करण एजेंट को "ब्लैक बॉक्स" के रूप में माना जाता है, यानी। प्रणाली, आंतरिक संगठन और तंत्र जिसकी हम नहीं जानते हैं। कार्य डेटा प्रोसेसिंग नियम (पी) का अनुमान लगाने के लिए है जो निष्पादक लागू करता है।
उदाहरण 1
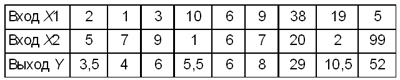
प्रसंस्करण एजेंट इनपुट मानों के औसत मान की गणना करता है: Y = (एक्स1 +एक्स2)/2
उदाहरण 2
प्रवेश द्वार पर - रूसी में शब्द, बाहर निकलने पर - स्वरों की संख्या।
सूचना प्रसंस्करण के मुद्दों का सबसे गहन मास्टरिंग मात्रा और प्रोग्रामिंग (प्राथमिक और उच्च विद्यालय में) के साथ काम करने के एल्गोरिदम का अध्ययन करते समय होता है। इस मामले में सूचना प्रसंस्करण के निष्पादक कंप्यूटर है, और सभी प्रसंस्करण क्षमताओं को प्रोग्रामिंग भाषा में शामिल किया गया है। प्रोग्रामिंग वहाँ है आउटपुट डेटा प्राप्त करने के लिए इनपुट डेटा को प्रोसेस करने के नियमों का विवरण.
छात्रों को दो प्रकार के कार्यों की पेशकश की जानी चाहिए:
प्रत्यक्ष कार्य: समस्या को हल करने के लिए एक एल्गोरिदम (प्रोग्राम) बनाने के लिए;
उलटा समस्या: एल्गोरिदम दिया गया है, आप एल्गोरिदम का पता लगाकर इसके निष्पादन का परिणाम निर्धारित करना चाहते हैं।
उलटी समस्या को हल करते समय, छात्र खुद को एक प्रसंस्करण ठेकेदार की स्थिति में डालता है, चरण-दर-चरण एल्गोरिदम प्रदर्शन करता है। प्रत्येक चरण में निष्पादन के परिणाम ट्रेस तालिका में परिलक्षित होना चाहिए।
सूचना हस्तांतरण

जैसा कि आप जानते हैं, विद्युत वोल्टेज का अपना उपाय होना चाहिए, जो प्रारंभ में उस मूल्य से मेल खाता है जो ...

कोयला पहला जीवाश्म ईंधन है जिसे मनुष्य ने उपयोग करना शुरू किया। वर्तमान में एक ऊर्जा वाहक के रूप में ...

थर्मल रिले विद्युत उपकरण हैं जिनके मुख्य उद्देश्य इंजन के खिलाफ अत्यधिक सुरक्षा के लिए है ...

कार्य योजना: कार्बन परमाणु का परिचय संरचना। प्रकृति में प्रसार। कार्बन उत्पादन। शारीरिक और रासायनिक ...
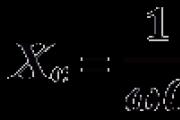
विद्युत मात्रा, जो विद्युत प्रवाह के प्रवाह को रोकने के लिए सामग्री की संपत्ति को दर्शाती है। में ...

एम्पेरे का कानून इलेक्ट्रिकल इंजीनियरिंग में सबसे महत्वपूर्ण और सबसे उपयोगी कानूनों में से एक है, जिसके बिना वैज्ञानिक और तकनीकी ...
परमाणु ऊर्जा संयंत्र की तकनीकी योजना रिएक्टर के प्रकार, शीतलक और मॉडरेटर के प्रकार, साथ ही कई अन्य पर निर्भर करती है ...
आमतौर पर, ऋणात्मक दशमलव संख्या स्वचालित रूप से विपरीत या परिवर्तित हो जाती है ...
सूचना विज्ञान और आईसीटी ग्रेड 8 कार्यपुस्तिका Bosova एलएल 2012 उत्तर, सूचना विज्ञान और आईसीटी ग्रेड 8 कार्यपुस्तिका ...

लाइट / बिजली मीटर और मीटरींग सितम्बर 1 Mosenergosbyt हर महीने डेटा हस्तांतरण की आवश्यकता है ...

जानकारी संग्रहीत करने और संचारित करने के तकनीकी साधनों के आगमन के साथ, नए विचार और कोडिंग तकनीक उभरी ....
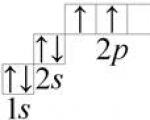
सी (कार्बोनेम), आवधिक प्रणाली के समूह आईवीए (सी, सी, जीई, एसएन, पीबी) के गैर धातु रासायनिक तत्व ...

हाइड्रोकार्बन ईंधन, पर्यावरणीय गिरावट और कई अन्य कारणों का थकावट जल्द या बाद में ...
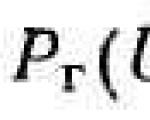
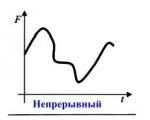
सबसे पहले, आइए विचाराधीन समस्याओं के लिए बुनियादी और सामान्य प्रश्न पर ध्यान दें: पता लगाएं कि क्या निर्भर करता है ...
एंथ्रासाइट (ग्रीक। Ανθραξ - कोयले), ठोस, उच्च घनत्व, चमकीले कोयला 90% से अधिक कार्बन युक्त ...
विद्युत उपकरण नियमित रूप से उन परीक्षणों के अधीन होते हैं जो अनुपालन की जांच के उद्देश्यों को आगे बढ़ाते हैं ...