वर्तमान और वोल्टेज के लिए बिजली की गणना
जैसा कि आप जानते हैं, विद्युत वोल्टेज का अपना उपाय होना चाहिए, जो प्रारंभ में उस मूल्य से मेल खाता है जो ...
पाठ के व्यक्तिगत पात्रों पर किए गए मुख्य ऑपरेशन - वर्णों की तुलना।
वर्णों की तुलना करते समय, सबसे महत्वपूर्ण पहलू प्रत्येक चरित्र के लिए कोड की विशिष्टता और इस कोड की लंबाई हैं, और एन्कोडिंग सिद्धांत की पसंद लगभग अप्रासंगिक है।
विभिन्न रूपांतरण तालिकाओं का उपयोग कर ग्रंथों के कोडिंग के लिए। यह महत्वपूर्ण है कि उसी तालिका का उपयोग एन्कोडिंग और एक ही पाठ को डीकोड करते समय किया जाता है।
इसलिए, पहले चरण में, 8-बिट कोड का विस्तार करीब है। ऐसी कई असाइनमेंट हैं जो विशिष्ट भाषाओं की आवश्यकताओं के अनुरूप हैं। फिर, अटूट स्थान और मुलायम हाइफ़न सहित कई चेक अंक हैं। चूंकि प्रत्येक चरित्र को आमतौर पर एक बाइट की बजाय तीन बाइट्स की आवश्यकता होती है, यूनिकोड वर्ण कलात्मक रूप से एन्कोड किए जाते हैं।
नीचे हम इस कोडिंग को समझाने के लिए खुद को सीमित करते हैं। इस मामले में, 1, 2, और 3-बाइट मान होते हैं। आम तौर पर, यह 4 बाइट भी संभव है। इस प्रकार, पश्चिमी भाषा में लिखे गए ग्रंथों को वास्तविक कोडिंग के बावजूद बड़े पैमाने पर पढ़ा जा सकता है। इसके अलावा, अंतरिक्ष को बचाने के लिए सबसे आम अक्षर एन्कोड किए गए हैं।
ट्रांसकोडिंग तालिका एक सारणी है जिसमें किसी भी तरह से एन्कोडेड वर्णों की ऑर्डर की गई सूची होती है, जिसके अनुसार चरित्र को इसके बाइनरी कोड में परिवर्तित किया जाता है और इसके विपरीत।
सबसे लोकप्रिय रूपांतरण सारणी: डीकेओआई -8, एएससीआईआईआई, सीपी 1251, यूनिकोड।
ऐतिहासिक रूप से, 8 बिट्स या 1 बाइट को एन्कोडिंग वर्णों के लिए कोड लंबाई के रूप में चुना गया था। इसलिए, अक्सर कंप्यूटर में संग्रहीत टेक्स्ट का एक वर्ण स्मृति के एक बाइट से मेल खाता है।
यदि अग्रणी बिट 1 है, तो यह एक मल्टीबाइट कोड है। निम्नलिखित उदाहरणों में दिखाए गए अनुसार, ग्यारह प्रासंगिक बाइट दो बाइट्स द्वारा वितरित किए जाते हैं। डबल-बाइट कोड के उदाहरण नीचे दिखाए गए दूसरे और तीसरे कोड तालिकाओं में देखे जा सकते हैं। कई अन्य कोडों का आविष्कार किया गया है, जैसे एमिल बोडो।
टेलीफ़ोन लाइनों ने टेलीप्रिंटर्स के विकास में योगदान दिया, जो डिवाइस बोडो कोड में अक्षरों को एन्कोड और डीकोड कर सकते थे। पात्रों को 5 बिट्स में एन्कोड किया गया था, इसलिए केवल 32 वर्ण थे। यह आपको 7 तक वर्णों को एन्कोड करने की अनुमति देता है और 8 बिट तक चलता है, इसलिए इसमें 256 संभावित वर्ण हैं।
8 बिट्स की कोड लंबाई के साथ 0 और 1 के विभिन्न संयोजन 28 = 256 हो सकते हैं, इसलिए एक रूपांतरण तालिका की सहायता से आप 256 से अधिक वर्णों को एन्कोड नहीं कर सकते हैं। 2 बाइट्स (16 बिट्स) की कोड लंबाई के साथ, 65,536 वर्ण एन्कोड किए जा सकते हैं।
वर्तमान में, अधिकांश उपयोगकर्ता टेक्स्ट जानकारी को संसाधित करने के लिए कंप्यूटर का उपयोग करते हैं, जिसमें प्रतीकों होते हैं: अक्षर, संख्याएं, विराम चिह्न, इत्यादि।
0 से 31 के कोड वर्ण नहीं हैं। उन्हें नियंत्रण वर्ण कहा जाता है क्योंकि वे उन्हें कुछ क्रियाएं करने की अनुमति देते हैं, जैसे लाइन ब्रेक और ऑडियो के लिए कैरिज रिटर्न। कोड 65 से 9 0 अपरकेस अक्षरों का प्रतिनिधित्व करते हैं। कोड 97 से 122 लोअरकेस अक्षर हैं।
इस कोड के लिए, 0 से 255 के मान अपरकेस और लोअरकेस अक्षरों, संख्याओं, विराम चिह्नों और अन्य प्रतीकों हैं। इसे वर्णमाला और अल्फान्यूमेरिक सिस्टम के सरलीकरण के रूप में सारांशित किया जा सकता है। ये प्रविष्टि और निकास कोड हमें उन सूचनाओं या डेटा का अनुवाद करने की अनुमति देते हैं जिन्हें हम डिवाइस या कंप्यूटर का उपयोग किसी अन्य प्रकार की समझ में समझते हैं कि एक मशीन समझ और प्रक्रिया कर सकती है। इस कोड के साथ बाइनरी को दशमलव में परिवर्तित करना बहुत आसान है।
परंपरागत रूप से, एक वर्ण को एन्कोड करने के लिए 1 बाइट के बराबर जानकारी की मात्रा का उपयोग करें, यानी मैं = 1 बाइट = 8 बिट्स। एक सूत्र का उपयोग करना जो संभावित घटनाओं की संख्या को जोड़ता है और सूचना की मात्रा I, हम गणना कर सकते हैं कि कितने अलग वर्ण एन्कोड किए जा सकते हैं (यह मानते हुए कि पात्र संभावित घटनाएं हैं):
जानकारी के आदान-प्रदान के लिए मानक संयुक्त राज्य कोड। यह व्यापक कोड सेट आपको विदेशी भाषा प्रतीकों और विभिन्न ग्राफिक प्रतीकों को जोड़ने की अनुमति देता है। खैर, इन अल्फान्यूमेरिक कंप्यूटर सिस्टम की कमी अभी भी है, अगर आपको संदेह या विचार हैं, तो एक टिप्पणी लिखें।
एन्कोडिंग करते समय, जब संख्याओं, अक्षरों या शब्दों को वर्णों के एक निश्चित समूह द्वारा दर्शाया जाता है, तो वे कहते हैं कि एक संख्या, अक्षर या शब्द एन्कोड किया गया है। पात्रों के समूह को कोड कहा जाता है। डिजिटल डेटा का प्रतिनिधित्व, संग्रहीत और बाइनरी बिट्स के समूह के रूप में प्रेषित किया जाता है। इस समूह को बाइनरी कोड भी कहा जाता है। बाइनरी कोड को एक संख्या के साथ-साथ अल्फान्यूमेरिक अक्षर द्वारा दर्शाया जाता है।
के = 2 आई = 28 = 256,
यानी, आप पाठ की जानकारी का प्रतिनिधित्व करने के लिए 256 वर्णों की क्षमता वाले वर्णमाला का उपयोग कर सकते हैं।
कोडिंग का सार यह है कि प्रत्येक प्रतीक को 00000000 से 11111111 या संबंधित दशमलव कोड 0 से 255 तक बाइनरी कोड असाइन किया जाता है।
यह याद रखना चाहिए कि वर्तमान में पांच अलग-अलग कोड तालिकाओं (केओआई - 8, सीपी 1251, सीपी 866, मैक, आईएसओ) रूसी अक्षरों को एन्कोड करने के लिए उपयोग किए जाते हैं, और एक तालिका के साथ एन्कोड किए गए ग्रंथों को किसी अन्य एन्कोडिंग में सही ढंग से प्रदर्शित नहीं किया जाएगा। इसे संयुक्त वर्ण एन्कोडिंग तालिका के टुकड़े के रूप में देखा जा सकता है।
यदि हम बाइनरी कोड का उपयोग करते हैं तो बाइनरी कोड डिजिटल सर्किट का विश्लेषण और डिज़ाइन करते हैं।
टेबल कोड असीमित कोड कोडित दशमलव बाइनरी कोड अल्फान्यूमेरिक कोड त्रुटि कोड त्रुटि कोड। टैब्यूलर बाइनरी कोड बाइनरी कोड हैं जो स्थितित्मक वजन के सिद्धांत का पालन करते हैं। प्रत्येक संख्या स्थिति एक विशिष्ट वजन का प्रतिनिधित्व करता है।
विभिन्न द्विआधारी प्रतीकों को एक ही बाइनरी कोड में असाइन किया जाता है।
बाइनरी कोड दशमलव कोड KOI8 CP1251 CP866 मैक आईएसओ
11000010 1 9 4 बीवी - - टी
हालांकि, ज्यादातर मामलों में, पाठ दस्तावेजों का रूपांतरण उपयोगकर्ता की देखभाल करता है, और विशेष कार्यक्रम - कन्वर्टर्स, जो एप्लिकेशन में बनाए जाते हैं।
1 99 7 से, माइक्रोसॉफ्ट विंडोज और ऑफिस के नवीनतम संस्करण नए यूनिकोड एन्कोडिंग का समर्थन करते हैं, जो प्रत्येक चरित्र को 2 बाइट्स निर्दिष्ट करता है, और इसलिए, 256 अक्षरों को एन्कोड करना संभव नहीं है, लेकिन 65536 विभिन्न वर्ण हैं।
इस प्रकार के बाइनरी कोड में, स्थिति वजन उन्हें असाइन नहीं किया जाता है। यह असीमित कोड है जो दशमलव संख्याओं को व्यक्त करने के लिए उपयोग किया जाता है। अतिरिक्त -3 कोड निम्नानुसार प्राप्त किए जाते हैं। 
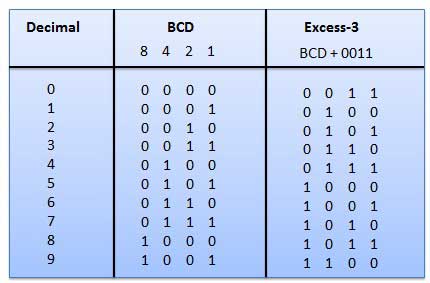
यह एक भारित कोड है, और ये अंकगणितीय कोड नहीं हैं। इसका मतलब है कि बिट स्थिति को निर्दिष्ट कोई विशिष्ट वजन नहीं है। इसमें एक बहुत ही विशेष विशेषता है जो चित्रा में दिखाए गए अनुसार प्रत्येक बार दशमलव बढ़ जाती है। चूंकि एक समय में केवल एक बिट परिवर्तन होता है, इसलिए ग्रे रंग कोड को दूरी इकाई कोड कहा जाता है।
संख्यात्मक वर्ण कोड निर्धारित करने के लिए, आप या तो कोड तालिका का उपयोग कर सकते हैं, या टेक्स्ट एडिटर वर्ड 6.0 / 95 में काम कर सकते हैं। ऐसा करने के लिए, मेनू आइटम "सम्मिलित करें" - "कैरेक्टर" चुनें, जिसके बाद स्क्रीन पर प्रतीक संवाद पैनल दिखाई देता है। चयनित फ़ॉन्ट के लिए एक प्रतीक तालिका संवाद बॉक्स में प्रकट होती है। इस तालिका के पात्रों को रेखा से व्यवस्थित किया गया है, अनुक्रमिक रूप से बाएं से दाएं, स्पेस कैरेक्टर (ऊपरी बाएं कोने) से शुरू होता है, और "I" अक्षर (निचला दायां कोने) के साथ समाप्त होता है।
धारावाहिक कोड अंकगणितीय ऑपरेशन के लिए उपयोग नहीं किया जा सकता है। 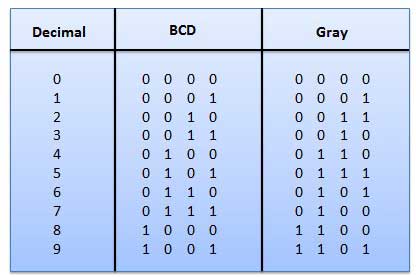
धुरी स्थिति एन्कोडर एक कोडवार्ड बनाता है जो धुरी की कोणीय स्थिति का प्रतिनिधित्व करता है। धुरी माप प्रणाली में ग्रे कोड का व्यापक रूप से उपयोग किया जाता है। । इस कोड में, प्रत्येक दशमलव अंक को 4 बिट्स की द्विआधारी संख्या द्वारा दर्शाया जाता है।
एक बाइनरी संख्या या बिट केवल दो वर्णों का प्रतिनिधित्व कर सकता है, क्योंकि इसमें केवल दो राज्य, 0 या 1 हैं। लेकिन यह दो कंप्यूटरों के बीच संचार के लिए पर्याप्त नहीं है, क्योंकि हमें संवाद करने के लिए और अधिक वर्णों की आवश्यकता नहीं है। इन वर्णों को अपरकेस और छोटे अक्षरों के साथ 26 अक्षरों का प्रतिनिधित्व करना चाहिए, 0 से 9 तक की संख्या, विराम चिह्न और अन्य वर्ण।
विंडोज (СР1251) में एन्कोड किए गए वर्ण के संख्यात्मक कोड को निर्धारित करने के लिए, इच्छित वर्ण का चयन करने के लिए माउस या कर्सर कुंजी का उपयोग करें, फिर कुंजी बटन पर क्लिक करें। उसके बाद, सेटिंग संवाद पैनल स्क्रीन पर दिखाई देता है, जिसमें निचले बाएं कोने में चयनित वर्ण का दशमलव संख्यात्मक कोड होता है।
"सूचना की मात्रा" की परिभाषा के तीन दृष्टिकोण
अल्फान्यूमेरिक कोड कोड हैं जो संख्याओं और वर्णमाला वर्णों का प्रतिनिधित्व करते हैं। असल में, ये कोड अन्य पात्रों को प्रतीक के रूप में भी प्रदर्शित करते हैं और जानकारी को स्थानांतरित करने के लिए आवश्यक विभिन्न निर्देशों का प्रतिनिधित्व करते हैं। अल्फान्यूमेरिक कोड, जिसमें वर्णमाला के कम से कम 10 संख्याएं और 26 अक्षर होना चाहिए, कुल 36 लेख। निम्नलिखित तीन अल्फान्यूमेरिक कोड डेटा का प्रतिनिधित्व करने के लिए व्यापक रूप से उपयोग किए जाते हैं।
विस्तृत कोडित दशमलव बाइनरी कोड। । डेटा स्थानांतरण के दौरान डेटा का पता लगाने और सही करने के लिए बाइनरी कोड विधियां हैं। डीकोडर्स सीखना शुरू करने से पहले, जो हमने पहले देखा था उससे बहुत समान है, आपको बाइनरी कोड के बारे में कुछ अवधारणाओं को याद रखना होगा।
A.P.Kolmogorov
1 कॉम्बिनेटोरियल दृष्टिकोण
परिवर्तनीय एक्स को एक्स के एक सीमित सेट से संबंधित मान लेने में सक्षम होना चाहिए, जिसमें एन तत्व होते हैं। ऐसा कहा जाता है कि एक चर के एंट्रॉपी है
परिवर्तनीय एक्स का एक निश्चित मान x = a निर्दिष्ट करके, हम जानकारी प्रदान करते हुए, इस एन्ट्रॉपी को "हटा दें"
यदि चर x1, x2, ..., xk स्वतंत्र रूप से उन सेटों से गुज़रने में सक्षम हैं जिनमें क्रमशः एन 1, एन 2, ..., एनके तत्व शामिल हैं, तो
ये द्विआधारी संख्याओं के अनुक्रम हैं जिन्हें किसी भी तरह से आदेश दिया जाता है। डिजिटल इलेक्ट्रॉनिक्स में, कई कोड हैं, ऐसी स्थितियां हैं जहां उनमें से एक का उपयोग दूसरे पर फायदे हैं। इसमें विभिन्न प्रकार की जानकारी को एन्कोड करने के लिए सात बिट्स शामिल हैं, जैसे संख्या, वर्ण पत्र, ट्रांसमिशन नियंत्रण सिग्नल इत्यादि।
एनकोडर्स और डिकोडर्स। आम तौर पर हमें एक कोड से दूसरे कोड में जाना होगा। इसे एक कोडर संयोजन सर्किट कहा जाता है जो आपको किसी ज्ञात कोड से अज्ञात तक जाने और एक सर्किट को डीकोड करने की अनुमति देता है जो विपरीत होता है। अब तक जो देखा गया है उसके विपरीत, इनपुट के लिए तर्क स्तर 0 को करना आम तौर पर आवश्यक होता है। इस प्रकार, एन्कोडर की सत्य तालिका दी जाएगी।
मुझे उपयोग की जाने वाली जानकारी की मात्रा को व्यक्त करने के लिए
द्विआधारी पात्र उदाहरण के लिए, के zeros और एक से युक्त विभिन्न "शब्दों" की संख्या और एक दो 2k (के + 1) है,
इसलिए, इस प्रकार के संदेश में जानकारी की मात्रा है
यानी शुद्ध बाइनरी सिस्टम में ऐसे शब्दों को "एन्कोड" करने के लिए आवश्यक है (हर जगह, f≈g का अर्थ है कि अंतर एफ-जी सीमित है, और एफ ~ जी, अनुपात एफ: जी एकता के लिए जाता है)
यह दशमलव बाइनरी एन्कोडर की रिवर्स प्रक्रिया करता है, यानी, यह बाइनरी संख्या से आउटपुट में से एक का चयन करता है। द्विआधारी-दशमलव descrambler की सच्ची तालिका उपरोक्त के विपरीत है। कार्नाट मानचित्र पर यह अप्रासंगिक स्थितियां होगी।
कर्णघ मानचित्रों का उपयोग करके सरलीकरण के बाद, निम्नलिखित अभिव्यक्तियां प्राप्त की जाती हैं; और सरलीकृत अभिव्यक्ति डीकोडर सर्किट से। बाइनरी दशमलव के साथ एक डिकोडर में देखी गई प्रक्रिया के समान कार्य करते हुए, आप किसी भी कोड से किसी अन्य कोड में जाने वाले डिकोडर्स का निर्माण कर सकते हैं।
7-तत्व डिस्प्ले आपको 0 से 9 तक दशमलव संख्याएं लिखने की अनुमति देता है और कुछ वर्ण, जो अक्षर या सिग्नल हो सकते हैं। नीचे दिया गया चित्र सामान्य प्रदर्शन इकाई को व्यावहारिक मैनुअल में सेगमेंट पहचान के सामान्य नामकरण के साथ दिखाता है।
शून्य और एक। सूचना सिद्धांत पेश करने में, वे आमतौर पर व्यापार के लिए इस तरह के एक संयोजन दृष्टिकोण पर लंबे समय तक नहीं रहते हैं। लेकिन ऐसा लगता है कि किसी भी प्रकार की किसी भी संभाव्य धारणा से इसकी तार्किक आजादी पर जोर देना आवश्यक है। उदाहरण के लिए, हम वर्णमाला में लिखे संदेशों को कोड करने के कार्य के साथ कब्जे में हैं, जिसमें अक्षरों को शामिल किया गया है, और यह ज्ञात है कि आवृत्तियों
एलईडी डिस्प्ले के दो मुख्य प्रकार हैं: - सामान्य कैथोड: सेगमेंट 1 से जलाए जाते हैं। सामान्य एनोड: सेगमेंट स्तर 0 के साथ जलाए जाते हैं। प्रत्येक नंबर पर, एल ई डी इनपुट की संख्या को स्वीकार करने के लिए डिज़ाइन किया जाना चाहिए। इस प्रोजेक्ट को पूरा करने के लिए, आपको प्रत्येक प्रतीक को उन खंडों में जांचने की आवश्यकता है जिन्हें जलाया जाना आवश्यक है, और बाइनरी कोड में संबंधित प्रविष्टि के अनुसार स्तर 1 असाइन करना होगा।
नीचे दिया गया चित्र रेखा, इसके इनपुट कोड और प्रत्येक सेगमेंट पर लागू स्तर दिखाता है। सरलीकरण में, हम कर्ण कार्नाट का उपयोग करेंगे। इस उदाहरण में, हम केवल आउटपुट वैरिएबल को सरल बना देंगे, क्योंकि अन्य एक ही सिद्धांत का पालन करते हैं। याद रखें कि प्रत्येक निकास के लिए कार्नाट का नक्शा बनाया जाना चाहिए।
लंबाई एन के संदेश में व्यक्तिगत अक्षरों की उपस्थिति असमानता को पूरा करती हैं
इसलिए, जब ऐसे संदेशों को प्रेषित करते हैं, तो यह लगभग एन बाइनरी वर्णों का उपयोग करने के लिए पर्याप्त है।
सार्वभौमिक कोडिंग विधि, जो एस अक्षरों के वर्णमाला में किसी भी पर्याप्त लंबे संदेश को प्रेषित करने की अनुमति देती है, एनएच बाइनरी वर्णों से ज्यादा नहीं, विशेष रूप से जटिल नहीं है, विशेष रूप से, पूरे संदेश के लिए आवृत्ति पीआर निर्धारित करने के साथ शुरू नहीं करना है। इसे समझने के लिए, यह ध्यान देने योग्य है: संदेश एस को तोड़कर एम सेगमेंट एस 1, एस 2, ..., एसएम, हमें असमानता मिलती है
यह ध्यान दिया जाना चाहिए कि इस योजना को अनुकूलित किया जा सकता है, क्योंकि सेगमेंट के अभिव्यक्तियों में कई सामान्य शर्तें हैं, जो कम बंदरगाहों के उपयोग की ओर ले जाती हैं। 7-तत्व डिस्प्ले अन्य पात्रों को भी रिकॉर्ड कर सकता है जिन्हें अक्सर अन्य कार्यों का प्रतिनिधित्व करने के साथ-साथ सॉफ़्टवेयर में कीवर्ड बनाने के लिए डिजिटल सिस्टम में उपयोग किया जाता है।
दूरसंचार और कंप्यूटर विज्ञान में, एक कोडित चरित्र सेट एक कोड है जो इस खेल के प्रत्येक चरित्र के लिए संख्यात्मक प्रतिनिधित्व के साथ वर्णमाला के चरित्र सेट को जोड़ता है। उदाहरण के लिए, मोर्स कोड पहले कोडित चरित्र सेटों में से एक है।
हालांकि, मैं यहां इस विशेष कार्य के विवरण में जाना नहीं चाहता हूं। मेरे लिए यह दिखाने के लिए केवल इतना महत्वपूर्ण है कि जानकारी की मात्रा को मापने के लिए पूरी तरह से संयोजी दृष्टिकोण से उत्पन्न गणितीय समस्याएं तुच्छता तक ही सीमित नहीं हैं।
यदि हम भाषण की "लचीलापन" के आकलन को ध्यान में रखते हैं - किसी दिए गए शब्दावली में भाषण जारी रखने और वाक्यांशों के निर्माण के लिए नियमों के नियमों के आकलन के संकेतक को "भाषण एन्ट्रॉपी" की अवधारणा के लिए पूरी तरह से संयोजी दृष्टिकोण होना काफी स्वाभाविक है। रूसी मुद्रित ग्रंथों की संख्या एन के बाइनरी लॉगेरिथम के लिए "एस। ओझेहेगोव द्वारा रूसी भाषा का शब्दकोश और" एन अक्षरों की संख्या "(रिक्त स्थान सहित) में व्यक्त की गई" व्याकरणिक शुद्धता "की आवश्यकता के लिए केवल अधीनस्थ शब्दों में शामिल शब्द, एम। रत्नेर और एन स्वेतलोवा को एक मूल्यांकन प्राप्त हुआ
हम सभी को एक बार एक अजीब ईमेल प्राप्त हुआ या इस तरह एक वेब पेज पढ़ा। यद्यपि यह कम और कम आम है, वाक्यांश कभी-कभी प्रकट होते हैं जिसमें कुछ पात्रों को दूसरों द्वारा प्रतिस्थापित किया जाता है जिनमें कुछ भी सामान्य नहीं होता है और जो पाठ की पढ़ने और समझ में हस्तक्षेप करता है। यह एक कोडिंग और डिकोडिंग समस्या है। पाठ लिखने वाला व्यक्ति इसे पढ़ने वाले व्यक्ति द्वारा उपयोग किए जाने वाले एक अलग मानक का उपयोग करता है!
सांस्कृतिक और आर्थिक आदान-प्रदान के वैश्वीकरण ने रेखांकित किया है कि यूरोपीय भाषाएं विशिष्ट वर्णमाला या यहां तक कि वर्णमाला के बिना कई अन्य भाषाओं के साथ मिलकर रहती हैं। इसलिए, दुनिया में इंटरनेट के व्यापक उपयोग के लिए बहुत अधिक प्रतीकों को ध्यान में रखना आवश्यक है। प्रत्येक चरित्र को एक नाम, नियामक स्थिति और एक संक्षिप्त विवरण दिया जाता है जो कंप्यूटर मंच या सॉफ़्टवेयर का उपयोग किए बिना समान होगा। गतिविधि - कोडिंग और इंटरनेट।
यह "अनुमान जारी रखने" के विभिन्न तरीकों का उपयोग करके प्राप्त "साहित्यिक ग्रंथों के एंट्रॉपी" के ऊपरी अनुमानों से काफी अधिक है। यह विसंगति काफी स्वाभाविक है, क्योंकि साहित्यिक ग्रंथ न केवल "व्याकरणिक शुद्धता" की आवश्यकता के अधीन हैं।
कुछ सामग्री सीमाओं के अधीन ग्रंथों के संयोजक एन्ट्रॉपी का आकलन करना अधिक कठिन होता है। उदाहरण के लिए, रूसी ग्रंथों के एन्ट्रॉपी का मूल्यांकन करने के लिए यह ब्याज का होगा, जिसे किसी दिए गए विदेशी भाषा पाठ के पर्याप्त सटीक अनुवाद के रूप में माना जा सकता है। केवल "अवशिष्ट एन्ट्रॉपी" की उपस्थिति कविता अनुवाद संभव बनाती है, जहां एक चुने हुए मीटर के बाद "एंट्रॉपी लागत" और गायन के चरित्र की सटीक गणना की जा सकती है। यह दिखाया जा सकता है कि "स्थानांतरण" इत्यादि की आवृत्ति पर कुछ प्राकृतिक प्रतिबंधों के साथ शास्त्रीय चार-पिच rhymed iambic, लगभग 0.4 के "अवशिष्ट एन्ट्रॉपी" द्वारा वर्णित मौखिक सामग्री के साथ इलाज की स्वतंत्रता की धारणा की आवश्यकता होती है (पाठ की लंबाई को मापने के ऊपर की सशर्त विधि के साथ रिक्त स्थान सहित पात्रों की संख्या ")। यदि हम खाते में ध्यान देते हैं, तो शैली की स्टाइलिस्ट सीमाएं शायद "पूर्ण" एन्ट्रॉपी के उपरोक्त मूल्यांकन को 1.9 से 1.1-1.2 से अधिक नहीं कर सकती हैं, तो स्थिति अनुवाद के मामले में दोनों उल्लेखनीय हो जाती है, और और मूल काव्य रचनात्मकता के मामले में।
एक इंटरनेट ब्राउज़र खोलें। आइए इसे बदल दें और मध्य यूरोप का चयन करें। छोटे, अप्रिय चरित्र दिखाई देते हैं। जैसे ही आप ड्राइव पैरामीटर बदलते हैं, एक असंगतता दिखाई देगी। एक वेब ब्राउज़र का उपयोग करना और "दृश्य", "स्रोत" पर जाकर, हमें निम्न मिलता है।
लाइटहाउस चलो समुद्र प्रकाश प्रकाश द्वारा उत्सर्जित प्रकाश का एक विशिष्ट उदाहरण मानते हैं: यह पहली अविभाज्य है, इसकी उत्पादन लागत उपयोगकर्ताओं की संख्या पर निर्भर नहीं है, गैर-प्रतिस्पर्धी संपत्ति है, इसे भी शामिल नहीं किया गया है, क्योंकि उपयोगकर्ता को उपयोग से बाहर करना असंभव है, भले ही उत्तरार्द्ध अपने वित्तपोषण में योगदान न दे।
उपयोगितावादी दिमागी पाठक मुझे इस उदाहरण के लिए माफ कर सकते हैं। औचित्य में, मुझे लगता है कि रचनात्मक मानव गतिविधि से संबंधित जानकारी की मात्रा का आकलन करने की व्यापक समस्या बहुत महत्वपूर्ण है।
आइए अब देखें कि पूरी तरह से संयोजी दृष्टिकोण हमें किस प्रकार परिवर्तनीय एक्स में निहित "जानकारी की मात्रा" का अनुमान लगाने के लिए अनुमति देता है। वेरिएबल्स एक्स और वाई के बीच कनेक्शन क्रमशः एक्स और वाई सेट करता है, इस तथ्य में निहित है कि सभी जोड़े x, y प्रत्यक्ष उत्पाद X.Y से संबंधित नहीं हैं "संभव"। संभावित जोड़े यू के सेट से, किसी भी एएक्स के लिए परिभाषित किया गया है, सेट हां उन वाई है जिसके लिए
समानता से सशर्त एंट्रॉपी को परिभाषित करना स्वाभाविक है
(जहां एन (वाईएक्स) सेट वाईएक्स में तत्वों की संख्या है), और y-formula के संबंध में x में जानकारी
उदाहरण के लिए, हमारे पास तालिका में दिखाए गए मामले में हमारे पास है
यह स्पष्ट है कि एच (वाई | एक्स) और मैं (एक्स: वाई) एक्स के कार्य हैं (जबकि वाई को उनके डिजाइन में "कनेक्टेड वेरिएबल" के रूप में शामिल किया गया है)।
पूरी तरह से संयोजी अवधारणा में, इसे आसानी से निर्दिष्ट सटीकता आवश्यकताओं के साथ ऑब्जेक्ट एक्स निर्दिष्ट करने के लिए आवश्यक जानकारी की मात्रा "के विचार को आसानी से पेश किया जाता है। (इस विषय पर मीट्रिक रिक्त स्थान में सेट के "ε-entropy" पर व्यापक साहित्य देखें।)
जाहिर है,
2 संभाव्य दृष्टिकोण
परिभाषाओं (5) और (6) के आधार पर सूचना सिद्धांत के आगे के विकास के अवसर छाया में बने रहे क्योंकि एक्स और वाई चर को एक निश्चित संयुक्त संभाव्यता वितरण के साथ "यादृच्छिक चर" के चरित्र देने से हमें अवधारणाओं और संबंधों की एक अधिक समृद्ध प्रणाली प्राप्त करने की अनुमति मिलती है। §1 में पेश की गई मात्राओं के समानांतर में, हमारे पास यहां है
फिर भी, एचडब्ल्यू (वाई | एक्स) और आईडब्ल्यू (एक्स: वाई) एक्स के कार्य हैं। असमानताएं हैं
इसी तरह के वितरण (एक्स और वाईएक्स पर) की समानता के साथ समानता में गुजरना। मात्रा IW (x: y) और I (x: y) एक निश्चित साइन असमानता से संबंधित नहीं हैं। §1 में,
लेकिन अंतर यह है कि गणितीय अपेक्षाओं को बनाना संभव है MHW (y | x), MIW (x: y), और
एक सममित तरीके से एक्स और वाई के बीच "कनेक्शन की मजबूती" को दर्शाता है।
हालांकि, यह एक विरोधाभास की संभाव्य अवधारणा में उभरने के लायक है: संयोजक दृष्टिकोण में I (x: y) का मान हमेशा गैर-नकारात्मक होता है, जैसा कि "जानकारी की मात्रा" की मूर्खतापूर्ण धारणा में प्राकृतिक है, IW (x: y) का मान नकारात्मक। "सूचना की मात्रा" का सही उपाय अब केवल औसत मूल्य IW (x, y) है।
संभाव्य दृष्टिकोण "द्रव्यमान" सूचना के संचार चैनलों के माध्यम से संचरण के सिद्धांत में प्राकृतिक है, जिसमें असंबद्ध या कमजोर अंतःस्थापित संदेशों की एक बड़ी संख्या शामिल है, कुछ संभाव्य पैटर्न के अधीन। ऐसे मामलों में, एक पर्याप्त लंबे समय तक श्रृंखला (जो पर्याप्त तेज़ "मिश्रण" की परिकल्पना के तहत सख्ती से उचित है) के भीतर संभावनाओं और आवृत्तियों का मिश्रण व्यावहारिक रूप से हानिरहित और लागू अनुसंधान में निहित है। एक व्यावहारिक रूप से विचार कर सकता है, उदाहरण के लिए, बधाई टेलीग्राम की धारा के "एन्ट्रॉपी" और समय-समय पर और निर्विवाद संचरण के लिए आवश्यक संचार चैनल की "क्षमता" का सवाल, इसकी संभाव्य व्याख्या में सही ढंग से सेट किया गया है और अनुभवजन्य आवृत्तियों द्वारा संभावित संभावनाओं के सामान्य प्रतिस्थापन के साथ। अगर यहां कुछ असंतोष है, तो यह गणितीय संभाव्यता सिद्धांत और वास्तविक "सामान्य रूप से यादृच्छिक घटनाओं के बीच संबंधों से संबंधित हमारी अवधारणाओं की एक निश्चित अस्पष्टता से जुड़ा हुआ है।
लेकिन "युद्ध और शांति" के पाठ में निहित "जानकारी की मात्रा" के बारे में बात करने के लिए वास्तविक अर्थ क्या है? क्या हम इस उपन्यास को "संभावित उपन्यासों" की कुलता में शामिल कर सकते हैं और यहां तक कि इस सेट में एक निश्चित संभाव्यता वितरण की उपस्थिति को भी पोस्ट कर सकते हैं? या "युद्ध और शांति" के व्यक्तिगत दृश्यों को "स्टोकास्टिक लिंक" के साथ यादृच्छिक क्रम बनाने के लिए माना जाना चाहिए, बल्कि कई पृष्ठों की दूरी पर जल्दी से लुप्त हो जाना चाहिए?
संक्षेप में, फैशनेबल अभिव्यक्ति "एक कोयल प्रजातियों के एक व्यक्ति को पुन: पेश करने के लिए आवश्यक आनुवांशिक जानकारी की मात्रा" कम अंधेरा नहीं है। फिर, स्वीकृत संभाव्य अवधारणा के भीतर, दो विकल्प संभव हैं। पहले संस्करण में, "संभावित प्रकारों" का कुल योग इस कुल 2 पर संभाव्यता वितरण के अज्ञात ठिकाने के साथ माना जाता है<100 бит!).).
दूसरे संस्करण में, फ़ॉर्म के विशिष्ट गुणों को कमजोर अंतःस्थापित यादृच्छिक चर के सेट के रूप में माना जाता है। दूसरे विकल्प के पक्ष में, कोई आपसी परिवर्तनशीलता के वास्तविक तंत्र के आधार पर विचारों का हवाला दे सकता है। लेकिन ये विचार भ्रमित हैं, अगर हम मानते हैं कि प्राकृतिक चयन के परिणामस्वरूप, प्रजातियों की निरंतर विशेषता विशेषताओं की एक प्रणाली उत्पन्न होती है।
3 एल्गोरिदमिक दृष्टिकोण
संक्षेप में, सबसे अर्थपूर्ण जानकारी "कुछ (x) और" कुछ के बारे में "(y) में जानकारी की मात्रा का विचार है। यह कोई संयोग नहीं है कि यह संभाव्य अवधारणा में था कि इसे निरंतर चर के मामले में सामान्यीकृत किया गया था जिसके लिए एंट्रॉपी अनंत है, लेकिन निश्चित रूप से मामलों की एक विस्तृत श्रृंखला में।
वास्तविक वस्तुओं का अध्ययन किया जाना बहुत जटिल है (असीमित?) कॉम्प्लेक्स, लेकिन दो वास्तव में मौजूदा वस्तुओं के बीच कनेक्शन उनके बारे में एक सरल, schematized वर्णन से समाप्त हो गए हैं। यदि एक भौगोलिक मानचित्र हमें पृथ्वी की सतह के एक वर्ग के बारे में महत्वपूर्ण जानकारी देता है, तो फिर भी कागज़ पर लागू कागज और पेंट के सूक्ष्म संरचना के पास पृथ्वी की सतह के चित्रित क्षेत्र के सूक्ष्म संरचना के साथ कुछ लेना देना नहीं है।
व्यावहारिक रूप से, हम अधिकतर व्यक्तिगत ऑब्जेक्ट एक्स के सापेक्ष एक व्यक्तिगत ऑब्जेक्ट एक्स में जानकारी की मात्रा में रुचि रखते हैं। हालांकि, यह पहले से ही स्पष्ट है कि जानकारी की मात्रा का एक व्यक्तिगत अनुमान केवल पर्याप्त मात्रा में जानकारी के मामलों में उचित सामग्री हो सकता है। उदाहरण के लिए, अनुक्रम 1 1 0 0 के संबंध में अंकों 0 1 1 0 के अनुक्रम में जानकारी की मात्रा के बारे में पूछने के लिए कोई अर्थ नहीं है। लेकिन यदि हम सांख्यिकीय अभ्यास में सामान्य मात्रा की यादृच्छिक संख्याओं की एक बहुत ही विशिष्ट तालिका लेते हैं और इसके प्रत्येक अंक के लिए अपनी वर्ग इकाइयों का अंक लिखते हैं
तो नई तालिका में लगभग शामिल होगा
मूल के बारे में जानकारी (एन - कॉलम में अंकों की संख्या)।
अभी जो कहा गया है उसके अनुसार, आईए (एक्स: वाई) के मूल्य की प्रस्तावित और परिभाषा कुछ अनिश्चितता बरकरार रखेगी। इस परिभाषा के विभिन्न समकक्ष रूपों से केवल IA1≈IA2 के अर्थ में समकक्ष मूल्यों का कारण बन जाएगा, यानी।
जहां निरंतर सीए 1 ए 2 सार्वभौमिक प्रोग्रामिंग विधियों ए 1 और ए 2 की परिभाषा के लिए अंतर्निहित दो विकल्पों पर निर्भर करता है।
हम "वस्तुओं के क्रमांकित क्षेत्र" पर विचार करेंगे, यानी। एक गणनीय सेट एक्स = (एक्स), जिसमें से प्रत्येक तत्व को "संख्या" एन (एक्स) के रूप में एक के साथ शुरू होने वाले शून्य और एक के एक सीमित अनुक्रम के रूप में असाइन किया जाता है। एल (एक्स) अनुक्रम एन (एक्स) की लंबाई से दर्शाएं। हम इसे मान लेंगे
1) वर्णित प्रकार के बाइनरी अनुक्रमों के एक्स और सेट डी के बीच पत्राचार एक-से-एक है;
2) डीएक्स, डी पर फंक्शन एन (एक्स) सामान्य रिकर्सिव है, और एक्सडी के लिए
जहां सी कुछ स्थिर है;
3) एक्स में एक्स और वाई के साथ, एक आदेशित जोड़ी (एक्स, वाई) है, इस जोड़ी की संख्या संख्या x और y की सामान्य पुनरावर्ती कार्य है और
जहां सीएक्स केवल एक्स पर निर्भर करता है।
इन सभी आवश्यकताओं में महत्वपूर्ण नहीं हैं, लेकिन वे प्रस्तुति की सुविधा प्रदान करते हैं। निर्माण का अंतिम परिणाम नए नंबरिंग एन "(एक्स) में संक्रमण के संबंध में आविष्कारशील है, जिसमें समान गुण हैं और आम तौर पर पुराने के माध्यम से बार-बार व्यक्त किया जाता है, और अधिक व्यापक प्रणाली एक्स में सिस्टम एक्स को शामिल करने के संबंध में (" यह मानते हुए कि संख्या संख्या "विस्तारित है मूल प्रणाली के तत्वों के लिए प्रणाली मूल संख्या n द्वारा अस्पष्ट है।) इन सभी परिवर्तनों के साथ, नई "कठिनाइयों" और जानकारी की मात्रा मूल के बराबर होती है ≈
किसी दिए गए x के लिए ऑब्जेक्ट वाई की "सापेक्ष जटिलता" x से y प्राप्त करने के लिए प्रोग्राम पी की न्यूनतम लंबाई एल (पी) है। इस प्रकार तैयार की गई परिभाषा "प्रोग्रामिंग विधि" पर निर्भर करती है। प्रोग्रामिंग विधि फंक्शन φ (पी, एक्स) = वाई से अधिक कुछ नहीं है, ऑब्जेक्ट वाई को प्रोग्राम पी और ऑब्जेक्ट एक्स को असाइन करना।
आधुनिक गणितीय तर्क में सार्वभौमिक रूप से मान्यता प्राप्त विचारों के अनुसार, कार्य φ को आंशिक रूप से रिकर्सिव माना जाना चाहिए। इस तरह के किसी भी समारोह के लिए, हम मानते हैं
इस मामले में, यूएक्स के मूल्यों के साथ यूएक्स के फ़ंक्शन υ = φ (u) को आंशिक रूप से रिकर्सिव कहा जाता है यदि यह आंशिक रूप से रिकर्सिव संख्या रूपांतरण फ़ंक्शन द्वारा उत्पन्न होता है
परिभाषा को समझने के लिए, यह ध्यान रखना महत्वपूर्ण है कि आंशिक रूप से पुनरावर्ती कार्य, आम तौर पर बोलते हुए, हर जगह परिभाषित नहीं होते हैं। किसी भी परिणाम के लिए ऑब्जेक्ट एक्स पर प्रोग्राम पी लागू करने या नहीं, यह जानने के लिए कोई नियमित प्रक्रिया नहीं है। इसलिए, फ़ंक्शन Kφ (y | x) को प्रभावी रूप से गणना योग्य (सामान्य रिकर्सिव) की आवश्यकता नहीं होती है, भले ही यह किसी भी एक्स और वाई के लिए निश्चित रूप से सीमित हो।
पाठ्यचर्या की जानकारी के बाइनरी एन्कोडिंग। विभिन्न सिरिलिक एन्कोडिंग
1 9 60 के दशक के अंत से, कंप्यूटरों की टेक्स्ट जानकारी को संसाधित करने के लिए तेजी से उपयोग किया जा रहा है, और अब दुनिया के अधिकांश व्यक्तिगत कंप्यूटर (और अधिकांश समय) टेक्स्ट प्रोसेसिंग में व्यस्त हैं।
पारंपरिक रूप से, एक वर्ण को एन्कोड करने के लिए, 1 बाइट के बराबर जानकारी की मात्रा का उपयोग किया जाता है, यानी 1 = बाइट = 8 बिट्स।
यदि हम पात्रों को संभावित घटनाओं के रूप में देखते हैं, तो हम गणना कर सकते हैं कि कितने अलग वर्ण एन्कोड किए जा सकते हैं:
रूसी और लैटिन वर्णमाला, संख्याओं, संकेतों, ग्राफिक प्रतीकों इत्यादि के ऊपरी और निचले केस अक्षरों सहित पाठ्यचर्या की जानकारी का प्रतिनिधित्व करने के लिए इस तरह के कई पात्र काफी पर्याप्त हैं।
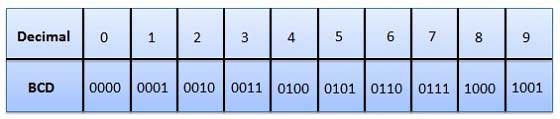
कोडिंग यह है कि प्रत्येक चरित्र को 0 से 255 या उसके संबंधित बाइनरी कोड से 00000000 से 11111111 तक एक अद्वितीय दशमलव कोड असाइन किया जाता है। इस प्रकार, एक व्यक्ति अपने कोड के अनुसार वर्णों के बीच अंतर करता है, और एक कंप्यूटर - उनके कोड के अनुसार।
जब आप कंप्यूटर में टेक्स्ट जानकारी दर्ज करते हैं, तो यह बाइनरी एन्कोडेड होता है, चरित्र की छवि को इसके बाइनरी कोड में परिवर्तित कर दिया जाता है। उपयोगकर्ता कीबोर्ड पर प्रतीक के साथ एक कुंजी दबाता है - और आठ विद्युत आवेगों (बाइनरी वर्ण कोड) का एक विशिष्ट अनुक्रम कंप्यूटर में प्रवेश करता है। चरित्र कोड कंप्यूटर की रैम में संग्रहीत होता है, जहां यह एक एकल सेल पर कब्जा करता है।
कंप्यूटर स्क्रीन पर एक चरित्र प्रदर्शित करने की प्रक्रिया में, एक रिवर्स प्रक्रिया निष्पादित की जाती है - डीकोडिंग, यानी, एक वर्ण कोड को उसकी छवि में परिवर्तित करना।
यह महत्वपूर्ण है कि प्रतीक के लिए एक विशिष्ट कोड का असाइनमेंट अनुबंध की बात है, जो कोड तालिका में तय किया गया है। पहले 33 कोड (0 से 32 तक) वर्णों को इंगित नहीं करते हैं, लेकिन संचालन (रेखा फ़ीड, एक स्थान का इनपुट इत्यादि)।
कोड 33 से 127 अंतरराष्ट्रीय हैं और लैटिन वर्णमाला, संख्याओं, अंकगणितीय परिचालनों और विराम चिह्नों के संकेतों के अनुरूप हैं।
128 से 255 के कोड राष्ट्रीय हैं, अर्थात, राष्ट्रीय एन्कोडिंग में विभिन्न प्रतीकों एक ही कोड से मेल खाते हैं। दुर्भाग्यवश, वर्तमान में रूसी अक्षरों (केओआई -8, सीपी 1251, सीपी 866, मई, आईएसओ) के लिए पांच अलग-अलग कोड टेबल हैं, इसलिए एक एन्कोडिंग में बनाए गए ग्रंथों को दूसरे में सही तरीके से प्रदर्शित नहीं किया जाएगा।
प्रत्येक एन्कोडिंग को अपनी कोड तालिका द्वारा परिभाषित किया जाता है। अलग-अलग एन्कोडिंग में एक ही बाइनरी कोड को अलग-अलग प्रतीकों को आवंटित किया जाता है।
हाल ही में, एक नया अंतरराष्ट्रीय मानक यूनिकोड दिखाई दिया है, जो एक बाइट आवंटित नहीं करता है, लेकिन प्रत्येक चरित्र के लिए दो, और इसलिए इसका उपयोग 256 अक्षरों को एन्कोड करने के लिए नहीं किया जा सकता है, लेकिन विभिन्न पात्रों को।

जैसा कि आप जानते हैं, विद्युत वोल्टेज का अपना उपाय होना चाहिए, जो प्रारंभ में उस मूल्य से मेल खाता है जो ...

कोयला पहला जीवाश्म ईंधन है जिसे मनुष्य ने उपयोग करना शुरू किया। वर्तमान में एक ऊर्जा वाहक के रूप में ...

थर्मल रिले विद्युत उपकरण हैं जिनके मुख्य उद्देश्य इंजन के खिलाफ अत्यधिक सुरक्षा के लिए है ...

कार्य योजना: कार्बन परमाणु का परिचय संरचना। प्रकृति में प्रसार। कार्बन उत्पादन। शारीरिक और रासायनिक ...
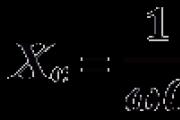
विद्युत मात्रा, जो विद्युत प्रवाह के प्रवाह को रोकने के लिए सामग्री की संपत्ति को दर्शाती है। में ...

एम्पेरे का कानून इलेक्ट्रिकल इंजीनियरिंग में सबसे महत्वपूर्ण और सबसे उपयोगी कानूनों में से एक है, जिसके बिना वैज्ञानिक और तकनीकी ...
परमाणु ऊर्जा संयंत्र की तकनीकी योजना रिएक्टर के प्रकार, शीतलक और मॉडरेटर के प्रकार, साथ ही कई अन्य पर निर्भर करती है ...
आमतौर पर, ऋणात्मक दशमलव संख्या स्वचालित रूप से विपरीत या परिवर्तित हो जाती है ...
सूचना विज्ञान और आईसीटी ग्रेड 8 कार्यपुस्तिका Bosova एलएल 2012 उत्तर, सूचना विज्ञान और आईसीटी ग्रेड 8 कार्यपुस्तिका ...

लाइट / बिजली मीटर और मीटरींग सितम्बर 1 Mosenergosbyt हर महीने डेटा हस्तांतरण की आवश्यकता है ...

जानकारी संग्रहीत करने और संचारित करने के तकनीकी साधनों के आगमन के साथ, नए विचार और कोडिंग तकनीक उभरी ....
सी (कार्बोनेम), आवधिक प्रणाली के समूह आईवीए (सी, सी, जीई, एसएन, पीबी) के गैर धातु रासायनिक तत्व ...

हाइड्रोकार्बन ईंधन, पर्यावरणीय गिरावट और कई अन्य कारणों का थकावट जल्द या बाद में ...
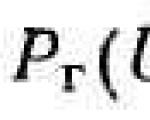
सबसे पहले, आइए विचाराधीन समस्याओं के लिए बुनियादी और सामान्य प्रश्न पर ध्यान दें: पता लगाएं कि क्या निर्भर करता है ...
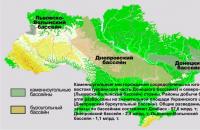
एंथ्रासाइट (ग्रीक। Ανθραξ - कोयले), ठोस, उच्च घनत्व, चमकीले कोयला 90% से अधिक कार्बन युक्त ...
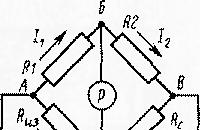
विद्युत उपकरण नियमित रूप से उन परीक्षणों के अधीन होते हैं जो अनुपालन की जांच के उद्देश्यों को आगे बढ़ाते हैं ...