Zariadenie, typy a schémy pripojovacích stmievačiek žiaroviek
Pri prevádzke štandardného spínača môžete dosiahnuť maximálny jas žiaroviek. Ale existujú situácie ...
Teraz existuje veľa informačných algoritmov kompresie. Väčšina z nich je všeobecne známa, ale existujú niektoré veľmi účinné, ale napriek tomu málo známe algoritmy. Tento článok hovorí o aritmetickej metóde kódovania, ktorá je najlepšia z entropie, ale napriek tomu veľmi málo ľudí vie o ňom.
Predtým, ako hovoríme o aritmetickom kódovaní, musím povedať niekoľko slov o Huffmanovom algoritme. Táto metóda je účinná, ak je frekvencia výskytu znakov úmerná 1/2 n (kde n je kladné celé číslo). Toto vyhlásenie sa stane zrejmé, ak si spomínam, že Huffmanove kódy pre každú znakovú jednotku vždy pozostávajú z celého počtu bitov. Zvážte situáciu, kedy je frekvencia výskytu symbolu 0,2, potom optimálny kód pre kódovanie tohto symbolu by mal byť -log 2 (0,2) = 2,3 bitov. Je zrejmé, že kód predpony Huffman nemôže mať takú dĺžku, t.j. to nakoniec vedie k zhoršeniu kompresie dát.
Aritmetické kódovanie je určené na vyriešenie tohto problému. Základnou myšlienkou je priradiť kódy nie jednotlivým znakom, ale ich sekvenciám.
Najskôr zvážte myšlienku algoritmu, potom zvážte malý praktický príklad.
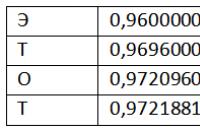
Rovnako ako u všetkých entropických algoritmov, máme informácie o frekvencii používania každého znaku abecedy. Táto informácia je zdrojom príslušnej metódy. Teraz predstavujeme koncept pracovného segmentu. Pracovník sa nazýva polo-interval * (hi-1-li-1); );
Veľká zvislá lišta na obrázku vyššie označuje ľubovoľné číslo, ktoré leží v intervale získanom počas prevádzky. Pre postupnosť "KOV.", Pozostávajúca zo 4 znakov, pre takéto číslo môžete mať 0,341. Toto číslo postačuje na obnovenie pôvodného reťazca, ak je známa pôvodná tabuľka rozsahu a dĺžka reťazca.
Zvážte fungovanie algoritmu obnovy reťazca. Každý ďalší interval je vnorený v predchádzajúcom. To znamená, že ak je číslo 0,341, prvý znak v reťazci môže byť len "K", pretože iba jeho rozsah zahŕňa toto číslo. Interval sa považuje za rozsah "K" - * (hi-1 - li-1); hi = hi-1 + b * (hi-l-li-1); ak ((li<= value) && (value < hi)) break; }; DataFile.WriteSymbol(cj); };
Kde hodnota je číslo (zlomok) čítané z prúdu a c sú nerozbalené znaky zapísané do výstupného toku. Keď používate abecedu s 256 znakmi, vnútorná slučka beží dostatočne dlho, ale môže sa zrýchliť. Všimnite si, že od ![]() (pozri vyššie uvedenú tabuľku rozsahov), potom je pre a sekvencia pre prísne zvyšuje s j. tj počet operácií vo vnútornom cykle sa môže znížiť na polovicu, pretože stačí skontrolovať len jeden intervalový limit. Taktiež, ak máme niekoľko symbolov, zoradíme ich v poradí klesajúcich pravdepodobností, znižujeme počet opakovaní cyklov a tým urýchľujeme prácu dekompresora. Najskôr sa skontrolujú znaky s najvyššou pravdepodobnosťou, napríklad v našom príklade, s najväčšou pravdepodobnosťou ukončíme cyklus už na druhom symbole šiestich. Ak je počet znakov veľký, existujú iné účinné metódy na zrýchlenie vyhľadávania znakov (napríklad binárne vyhľadávanie).
(pozri vyššie uvedenú tabuľku rozsahov), potom je pre a sekvencia pre prísne zvyšuje s j. tj počet operácií vo vnútornom cykle sa môže znížiť na polovicu, pretože stačí skontrolovať len jeden intervalový limit. Taktiež, ak máme niekoľko symbolov, zoradíme ich v poradí klesajúcich pravdepodobností, znižujeme počet opakovaní cyklov a tým urýchľujeme prácu dekompresora. Najskôr sa skontrolujú znaky s najvyššou pravdepodobnosťou, napríklad v našom príklade, s najväčšou pravdepodobnosťou ukončíme cyklus už na druhom symbole šiestich. Ak je počet znakov veľký, existujú iné účinné metódy na zrýchlenie vyhľadávania znakov (napríklad binárne vyhľadávanie).
Hoci uvedený algoritmus je plne funkčný, bude pracovať pomaly v porovnaní s algoritmom pracujúcim s binárnymi frakciami. Binárna frakcia je uvedená ako. Preto počas kompresie musíme do frakcie pridať ďalšie znaky, až výsledné číslo spadne do intervalu zodpovedajúceho kódovanému reťazcu. Výsledné číslo úplne nastaví kódovaný reťazec podobným dekódovacím algoritmom. Graficky je algoritmus algoritmu znázornený na obrázku 1.4.
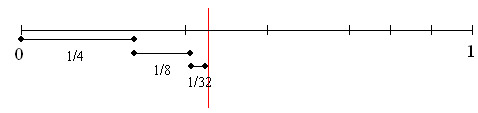
cvičenie: Obnovte zdrojový kód z kódovaného reťazca na 2 bity, ktorý sa rovná "11" (číslo ![]() ), ak viete, že dĺžka textu je 10 znakov.
), ak viete, že dĺžka textu je 10 znakov.
Zaujímavým znakom aritmetického kódovania je schopnosť výrazne komprimovať jednotlivca

Pri prevádzke štandardného spínača môžete dosiahnuť maximálny jas žiaroviek. Ale existujú situácie ...

Prúdové transformátory sa používajú na meranie prúdov v obvodoch napájania striedavého prúdu. Používajú sa ako v reťaziach, aby ...

Najlepšie polarizované slnečné okuliare sú k dispozícii v rôznych formách a funkciách, so všetkými úspechmi vysokej ...
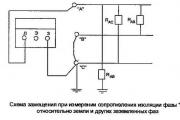
Pri uvedení kábla do prevádzky, počas a po opravárenských prácach s problémami so zapojením - vo všetkých týchto prípadoch ...

Existuje veľa situácií, kedy bude užitočné vedieť, ako merať odpor pomocou multimetra a existuje nejaký rozdiel, ako ...
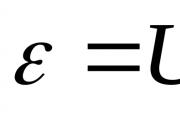
Zriadenie vzdelania "KOMUNIKÁCIA VYSOKÉHO ŠTÁTU KOMUNIKÁCIE" STANOVENIE ELEKTRÓZNEJ SILY METÓDY BEŽNÉHO ZDROJA ...

Otvorte obvod vo vinutí fáz statora. Ak sú obe fázy rozbité, generátor nebude vôbec fungovať. Ak ...
Vladimir Malafeev Certifikovaný obchodný tréner. Vie, ako veľmi ťažko pochopiť každého.
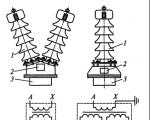
V závislosti od účelu je možné použiť napäťové transformátory s rôznymi schémami pripojenia ...

Každý vie, že sa skôr alebo neskôr zrútia autá. Ale niekedy motorista čelí takému problému ako ...
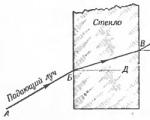
Lúč svetla, ktorý sa pohybuje z jedného transparentného média do druhého, mení smer, alebo, ako sa hovorí, ...

Výkon asynchrónneho motora sa nazýva závislosť účinnosti η, ...
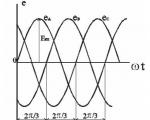
Federálna agentúra pre vzdelávanie GOU VPO "Štátna technická univerzita ...
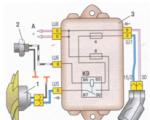
Dnes s takým rýchlym vývojom technológií je veľmi dôležité vedieť, ako čítať elektrické obvody automobilov. A nie ...
Teraz existuje veľa informačných algoritmov kompresie. Väčšina z nich je všeobecne známa, ale existujú ...
Kladenie káblov vo výkopoch Typy pokladania: geodetické služby Montáž elektrických zariadení a sietí ...