फ्लोरोसेंट लैंप 36 डब्ल्यू
आज फ्लोरोसेंट लैंप के बिना बड़े ट्रेडिंग, शैक्षिक, कार्यालय और गोदाम परिसर की कल्पना करना मुश्किल है ...
"साइन सिस्टम सूचना कोडिंग" - स्वाद। बाइनरी साइन सिस्टम। ज्ञान के रूप में प्रस्तुत जानकारी के गुण क्या होने चाहिए? पाठ को बुलाओ। मीडिया द्वारा प्रदान की गई जानकारी के गुण क्या होने चाहिए? संदेशों के रूप में प्रदान की गई जानकारी के गुण क्या होने चाहिए? पाठ का विषय। दोहराव।
न्यूरॉन्स की संख्या बल्कि गैर-समान थी, कुछ न्यूरॉन्स के लिए लौकिक कोडित जानकारी नगण्य है, जबकि अन्य के लिए यह पल्स गणना में निहित लगभग बराबर थी। वास्तव में, इस एकल बिट में दालों की संख्या में प्रतिक्रिया के सभी 320 एमएस में उपलब्ध अधिकांश जानकारी शामिल है, लेकिन अस्थायी रूप से कोडित जानकारी, इस विंडो के अंदर और शेष उत्तर दोनों में, सांख्यिकीय रूप से महत्वपूर्ण है। हम इस समय विंडो को ट्रांसमिशन दर में परिवर्तित करते हैं, इसे खिड़की की चौड़ाई में विभाजित करते हुए, हम अधिकतम आवृत्तियों को प्रति सेकंड 30 बिट तक प्राप्त करते हैं।
"वैज्ञानिक और तकनीकी जानकारी" - अंतर्राष्ट्रीय मानकीकरण और प्रमाणन "इंटरस्टैंडर्ट" के क्षेत्र में परामर्श और नवाचार फर्म - http://www.interstandard.ru/। राज्य की वैज्ञानिक प्रणाली और तकनीकी जानकारी (GSNTI)। अंग्रेजी में 10 विषयगत श्रृंखलाओं पर निबंधों के संग्रह हैं। INION RAS प्रकाशित: विश्लेषणात्मक रिपोर्ट
पहली बार प्रस्तुत की गई प्रतिक्रिया के साथ जानकारी के लिए गणना का प्रदर्शन करके, पहली चोटी पर केंद्रित खिड़की में दालों की गिनती करके, और दूसरी बार दो चोटियों के लिए उन्मुख खिड़कियों की एक जोड़ी में काउंटरों द्वारा, आप यह निर्धारित कर सकते हैं कि दूसरी चोटी नई जानकारी या बस संदेश imo दोहराया। चियरे और उनके सहयोगियों ने इन तंत्रिका संदेशों की सामग्री की समस्या पर ध्यान केंद्रित किया। इन लेखकों ने गणना की जो हमने वाल्श सेट में उत्तेजनाओं के सबसेट के लिए वर्णित की। विभिन्न सेटों की स्थानिक विशेषताओं के साथ सूचना प्रसारित करने की एक विधि, वे स्थानिक विशेषताओं का एक व्यवस्थित विवरण दे सकते हैं जिसके द्वारा ये न्यूरॉन्स जानकारी संचारित करते हैं।
"संख्या और कोडिंग सूचना" - मोर्स कोड। कंप्यूटर कीबोर्ड टेबल ग्राफ। ग्राफिक। - चित्र या आइकन के साथ। आदेश 1 2. एक व्यक्ति की स्मृति और मानवता की स्मृति भी है। प्रारंभिक चरण। Dsbhyl। पाठ। (बंदोबस्त संहिता के संकेत के साथ)। चित्रा। Ubvmychb। कोई व्यक्ति जानकारी कैसे संग्रहीत करता है?
निम्न सेट निम्नानुसार चुने गए थे। वाल्श प्रोत्साहन के पूर्ण सेट में, एक पर विचार करें जिसमें चार आसन्न वर्ग शामिल हैं, साथ ही उल्टे संवाददाताओं, एक जिसमें एक विशेषता लंबाई पैमाने पर दोनों दिशाओं में संरचनात्मक स्थानिक विशेषताएं हैं।
यदि तंत्रिका संबंधी प्रतिक्रियाओं का पता लगाया जाता है, तो इस सेट पर सार्थक जानकारी प्राप्त करने के लिए, आप इस पैमाने पर एक फीचर डिटेक्टर के रूप में न्यूरॉन के बारे में सोच सकते हैं। एक विशेष न्यूरॉन के पास वाल्श स्थान से सटे नमूनों के अलग-अलग जवाब देने के लिए पर्याप्त रिज़ॉल्यूशन नहीं हो सकता है। हालांकि, यह तब हो सकता है जब पैटर्न का सबसेट जिसके लिए पहले गियर की गणना की गई थी, और अधिक विभेदित चरणों में स्थानिक विशेषताएं हैं, इसलिए चियारा और सहयोगियों ने उत्तेजना सेटों के लिए समान गणना की, जिसके लिए वॉल्श सूचकांकों का अंतर भी क्षैतिज या ऊर्ध्वाधर 2 या 3 था। दिशा या दोनों में।
"ऑडियो जानकारी एन्कोडिंग" - विषय पर मूल शब्द "बाइनरी ऑडियो एन्कोडिंग।" साउंड कार्ड शोर के स्तर के कुछ मूल्य। पा (पैस्कल्स) में मापा जाता है। एम्पलीट्यूड की विस्तृत श्रृंखला के कारण, लॉगरिदमिक डेसिबल स्केल (dB) का अधिक सामान्यतः उपयोग किया जाता है: Hz में मापा जाता है। 1 हर्ट्ज = 1 दोलन / सेकंड। एक व्यक्ति को लगता है कि 16 हर्ट्ज से 20 किलोहर्ट्ज़ तक की सीमा है।
स्तरीय वक्र पाए गए थे जो विषम थे और विभिन्न प्रकार की संरचनाओं को दर्शाते थे। डिटेक्टर विशेषताओं के संदर्भ में व्याख्या की जाती है, एक नियम के रूप में, ये कोशिकाएं सीढ़ी के विभिन्न सन्निकटन के साथ विभिन्न स्थानिक विशेषताओं को दिखाती हैं। देखी गई सबसे सामान्य प्रकार की संरचनाएं लकीरें और पठार थीं, जो वाल्श अंतरिक्ष में दिशा के साथ लम्बी होती हैं। तुलना के लिए, रिज के लिए लंबवत विस्थापन के सापेक्ष प्रेषित सूचना की संवेदनशीलता, रूबेल और विसल के अनुसार जो बताती है, उसके अनुसार, ये न्यूरॉन्स देखने के क्षेत्र में वस्तुओं के उन्मुखीकरण के बारे में चयनात्मक होते हैं। दूसरी ओर, रिज की रिश्तेदार "मिठास" इंगित करती है "इस दिशा में स्थानिक मॉडुलन के प्रति असंवेदनशीलता।"
"कोडिंग सूचना" - मोर्स कोड। सभी वर्णों की संहिता की लंबाई समान और पाँच के बराबर है। एन्क्रिप्शन को विज्ञान द्वारा नियंत्रित किया जाता है जिसे क्रिप्टोग्राफी कहा जाता है। डिकोडिंग - बाइनरी कोड से डेटा को एक ऐसे रूप में परिवर्तित करना जो मनुष्यों के लिए समझ में आता है। संदेश "सूचना विज्ञान" को मोर्स कोड का उपयोग करके एनकोड करें। अरबी दशमलव संख्या प्रणाली की वर्णमाला का उपयोग करते हुए, हम "35" लिखते हैं।
हमारे द्वारा वर्णित कई परिणामों में, यह स्पष्ट है कि अभ्यावेदन में, जिसमें उत्तरों से जानकारी को फ़िल्टर्ड किया गया था, और इसमें जो शामिल थे, सिद्धांत रूप में, सभी जानकारी, अधिक जानकारी प्रदान की गई थी। यह ऐसा नहीं होगा यदि उत्तर चुप थे, लेकिन शोर की उपस्थिति में, क्रॉस-चेकिंग प्रक्रिया वास्तव में प्रतिक्रिया के घटकों को नष्ट कर देगी जिसके लिए संकेत शोर पर हावी है। इसलिए, हम यह नहीं कह सकते हैं कि इन घटकों में सूचना का प्रसारण नहीं है; हम केवल यह कह सकते हैं कि हमारे पास यह निर्धारित करने के लिए पर्याप्त डेटा नहीं है कि क्या है।
सूचना के भंडारण और संचारण के तकनीकी साधनों के आगमन के साथ, नए विचारों और कोडिंग तकनीकों का उदय हुआ। दूरी पर सूचना प्रसारित करने का पहला तकनीकी साधन टेलीग्राफ था, जिसका आविष्कार 1837 में अमेरिकन सैमुअल मोर्स ने किया था। एक टेलीग्राफ संदेश एक तार से दूसरे टेलीग्राफ तंत्र के लिए एक विद्युत तार से प्रेषित विद्युत संकेतों का एक क्रम है। इन तकनीकी परिस्थितियों ने एस मोर्स को केवल दो प्रकार के संकेतों का उपयोग करने के विचार के लिए प्रेरित किया - लघु और लंबी - टेलीग्राफ लाइनों के माध्यम से प्रेषित संदेश को सांकेतिक शब्दों में बदलना।
Kjерr और सह-लेखकों ने समस्या का एक अध्ययन किया, जो कई न्यूरॉन्स तक सीमित था, जिसके लिए उनके पास सबसे बड़ी संख्या में परीक्षण थे, उन्होंने अपने डेटा के सबसिस्टम पर गणना का प्रदर्शन किया। छोटे सबसेट के लिए, शोर से संकेत निकालना मुश्किल है, और प्रेषित जानकारी इसलिए कम है। प्रतिक्रिया के मुख्य घटक से निकाली गई जानकारी डेटा सेट के आकार के लिए एक सीमा तक पहुंचती है, जो लगभग 10 दोहराए जाने वाले उत्तेजना परीक्षणों से अधिक होती है, लेकिन 5 घटकों के साथ 32 दोहराव उत्तेजना परीक्षणों के साथ भी संतृप्ति दिखाई नहीं देती है।
सैमुअल फिनाले ब्रीज मोर्स (1791-1872), यूएसए
इस एन्कोडिंग विधि को मोर्स कोड कहा जाता है। इसमें, वर्णमाला के प्रत्येक अक्षर को छोटे संकेतों (डॉट्स) और लंबे संकेतों (डैश) के अनुक्रम द्वारा एन्कोड किया गया है। पत्रों को एक-दूसरे से अलग कर दिया जाता है - संकेतों की कमी।
सबसे प्रसिद्ध टेलीग्राफ संदेश संकट संकेत "एसओएस" है ( एस एवेन्यू हेउर एसouls - हमारी आत्माओं को बचाओ)। अंग्रेजी वर्णमाला के लिए लागू मोर्स कोड में यह कैसा दिखता है:
एक अधिक व्यवस्थित विश्लेषण हाल ही में गोलमबोल और कर्मचारियों द्वारा कृत्रिम, लेकिन यथार्थवादी आंकड़ों पर किया गया था। उपयोग किए जाने वाले पल्स अनुक्रम पार्श्व जीनियस कोर के लिए मापा गया अंतरिक्ष-समय पुनर्नवीनीकरण क्षेत्रों के आधार पर एक टेम्पलेट से प्राप्त किए गए थे। मनमाने ढंग से बड़े डेटा के सेट को उत्पन्न करना और 0, 01 बिट्स की सटीकता के साथ तीसरे मुख्य घटक के लिए प्रतिक्रिया के मुख्य घटकों के लिए संचरित सूचनाओं की गणना करना, 106 परीक्षणों के अंतराल के साथ एक साधारण विभाजन का उपयोग करना था।
गणना नेटवर्क के उपयोग के आधार पर, साथ ही वास्तविक डेटा के लिए, और परिणाम की तुलना "लगभग" सटीक रूप से की जाती है। परिणामों से पता चला कि तंत्रिका नेटवर्क आधारित गणना का उपयोग करके प्रेषित अच्छी जानकारी का मूल्यांकन करने के लिए आवश्यक उत्तेजना परीक्षणों की संख्या लगभग प्रोत्साहन के सेट के आकार के बराबर है। जब विधि गलत है, तो यह अनिवार्य रूप से जानकारी के कम आंकने से जुड़ा हुआ है। यह क्रॉस-वैलिडेशन रणनीति की रूढ़िवादी प्रकृति के कारण है: यह रणनीति सुनिश्चित करती है कि शोर को एक व्यवस्थित संरचना के साथ नहीं बदला जा सकता है। अधिक जटिल कक्षाओं में विभाजित करने की प्रक्रिया का उपयोग करके, समान रूप से भरे हुए वर्गों का उपयोग करके और एक परिमित नमूना आकार के लिए इसी सुधार का उपयोग करके प्राप्त किया जाता है।
–––
तीन बिंदु (अक्षर S), तीन डैश (अक्षर O), तीन बिंदु (अक्षर S)। दो ठहराव पत्रों को एक दूसरे से अलग करते हैं।
आंकड़ा रूसी वर्णमाला के संबंध में मोर्स कोड दिखाता है। कोई विशेष विराम चिह्न नहीं थे। वे शब्दों के साथ लिखे गए थे: "बिंदु" - बिंदु, "zpt" - अल्पविराम, आदि।
मोर्स कोड की विशेषता विशेषता है विभिन्न अक्षरों का चर लंबाई कोडइसलिए मोर्स कोड कहा जाता है गैर-समान कोड। पाठ में अधिक बार दिखाई देने वाले पत्रों में दुर्लभ अक्षरों की तुलना में एक छोटा कोड होता है। उदाहरण के लिए, "ई" अक्षर का कोड एक बिंदु है, और एक ठोस वर्ण के कोड में छह वर्ण होते हैं। यह पूरे संदेश की लंबाई को कम करने के लिए किया जाता है। लेकिन अक्षर कोड की चर लंबाई के कारण, पाठ में अक्षरों को एक दूसरे से अलग करने की समस्या है। इसलिए, अलगाव के लिए एक ठहराव (पास) का उपयोग करना आवश्यक है। इसलिए, मोर्स टेलीग्राफ वर्णमाला तीन गुना है, क्योंकि यह तीन वर्णों का उपयोग करता है: डॉट, डैश, स्किप।
यह विधि डिकोडिंग का उपयोग नहीं करती है; यह समीकरण का अनुसरण करता है, बिना शर्त एंट्रॉपी की गणना और सशर्त उत्तर की प्रतिक्रिया और दूसरे को पहले से घटाता है। एकल न्यूरॉन्स पर माप केवल एक प्रणाली के अध्ययन की शुरुआत है, जो आखिरकार, इंटरेक्शन इकाइयों के अरबों का एक नेटवर्क है। इस क्षेत्र में, हम आसन्न दो कोशिकाओं को परिभाषित करते हैं, जो एक ही इलेक्ट्रोड द्वारा पंजीकृत हैं; दो प्रकार की दालें अलग-अलग रूपों में अलग-अलग होती हैं, जिनमें मिलीसेकंड के नीचे एक समय स्केल होता है।
उपयोग किए गए उत्तेजना पैटर्न में वॉल्श सेट के अलावा कुछ समान बार-उन्मुख वाले शामिल थे। गुणात्मक शब्दों में, तीन प्रकार के कोड हैं जो हम न्यूरॉन्स की एक जोड़ी में देख सकते हैं। पहला एक निरर्थक कोड है जिसमें दो न्यूरॉन्स एक ही संदेश भेजते हैं; केवल उनके शोर अलग हैं। यह एक ऐसा कोड है जिसकी आप स्वाभाविक रूप से उम्मीद करेंगे यदि आप परिकल्पना के साथ शुरू करते हैं कि न्यूरॉन्स आंतरिक शोर के संपर्क में हैं, सिग्नल मल्टीप्लेक्सिंग का उपयोग शोर को दूर करने के लिए किया जाता है, और दूसरी संभावना एक स्वतंत्र कोड है यदि दो न्यूरॉन्स काफी अलग संदेश भेजते हैं।

यूनिफ़ॉर्म टेलीग्राफ कोड यह 19 वीं शताब्दी के अंत में फ्रांसीसी जीन-मौरिस बोडो द्वारा आविष्कार किया गया था। यह केवल दो अलग-अलग प्रकार के संकेतों का उपयोग करता था। इससे कोई फर्क नहीं पड़ता कि आप उन्हें कैसे कहते हैं: डॉट और डैश, प्लस और माइनस, शून्य और एक। ये दो अलग-अलग विद्युत संकेत हैं। सभी पात्रों के कोड की लंबाई समान है।और पाँच के बराबर है। इस मामले में, अक्षरों को एक दूसरे से अलग करने की कोई समस्या नहीं है: प्रत्येक पांच संकेतों में से एक पाठ का संकेत है। इसलिए, एक पास की जरूरत नहीं है।
आंतरिक शोर कम होने पर प्रभावी प्रदर्शन के सिद्धांत से हम यही उम्मीद करते हैं। अंत में, दो न्यूरॉन्स एक संदेश प्रेषित कर सकते हैं जो उनमें से किसी से अलग से नहीं निकाले जा सकते हैं, अर्थात्, एक अन्य कोड को सूचना सिद्धांत के दृष्टिकोण से वर्णित किया जा सकता है, प्रत्येक न्यूरॉन द्वारा प्रेषित जानकारी को अलग से लेना, और न्यूरॉन्स द्वारा प्रेषित जानकारी। एक साथ दो। नेटवर्क डिकोडिंग के लिए, जिसका हमने वर्णन किया है, इसका मतलब है कि गणना नेटवर्क के उपयोग के लिए की गई है, जहां कुछ इनपुट न्यूरॉन की प्रतिक्रिया का प्रतिनिधित्व करते हैं, जबकि अन्य इनपुट दूसरे की प्रतिक्रिया का प्रतिनिधित्व करते हैं।

जीन-मौरिस एमिल बोडो (1845-1903), फ्रांस
प्रौद्योगिकी के इतिहास में बोडो कोड पहली विधि है। बाइनरी कोडिंग सूचना। इस विचार के लिए धन्यवाद, एक प्रत्यक्ष-मुद्रण टेलीग्राफ बनाना संभव था, जिसमें टाइपराइटर की उपस्थिति थी। एक विशिष्ट पत्र के साथ एक कुंजी दबाने से एक संबंधित पांच-पल्स सिग्नल उत्पन्न होता है, जो संचार लाइन के माध्यम से प्रेषित होता है। इस सिग्नल के प्रभाव में प्राप्त करने वाला उपकरण एक ही पत्र को एक पेपर टेप पर प्रिंट करता है।
बेशक, मध्यवर्ती मामले संभव हैं। मुख्य परिणाम यह है कि कोड स्वतंत्र कोड के लिए एक अच्छा सन्निकटन है। मतलब सेल जनसंख्या अनुपात। दूसरे शब्दों में, कुल संयुक्त जानकारी का 20% हिस्सा है। दृश्य प्रणाली के अन्य हिस्सों, साथ ही साथ अन्य जानवरों में अध्ययन, कम से कम गुणात्मक रूप से इस परिकल्पना से सहमत हैं कि स्वतंत्रता का यह स्तर प्रांतस्था की विशेषता है। इन परिणामों से संकेत मिलता है कि अल्पकालिक न्यूरॉन्स अत्यधिक शोर का स्रोत नहीं हैं, और इसलिए, सिस्टम एक विस्तृत बैंड का उपयोग करता है, जो उनमें से कई की उपस्थिति से प्रदान किया जाता है।
आधुनिक कंप्यूटर भी यूनिफॉर्म कोडिंग का उपयोग करते हैं। बाइनरी कोड (देखें) पाठ एन्कोडिंग सिस्टम 2).
कोडिंग की जानकारी का विषय स्कूल में कंप्यूटर विज्ञान के अध्ययन के सभी चरणों में पाठ्यक्रम में प्रस्तुत किया जा सकता है।
प्रचारक पाठ्यक्रम में, छात्रों को अक्सर ऐसे कार्यों की पेशकश की जाती है जो डेटा के कंप्यूटर कोडिंग से संबंधित नहीं होते हैं और एक अर्थ में, एक गेम रूप होते हैं। उदाहरण के लिए, मोर्स कोड कोड तालिका के आधार पर, आप दोनों कोडिंग कार्य (मोर्स कोड का उपयोग करके रूसी पाठ को सांकेतिक शब्दों में बदलना) और डिकोडिंग (मोर्स कोड के साथ डिकोड किए गए पाठ को डिक्रिप्ट कर सकते हैं) की पेशकश कर सकते हैं।
सबसे सरल जानवरों का अध्ययन करना, जैसे कि न्यूरॉन्स के समान स्तर में होना, अधिक पूर्ण विवरण और अधिक न्यूरॉन्स के लिए व्यवस्थित विशेष कोडिंग उदाहरणों के लिए एक अवसर प्रदान कर सकता है। इन लेखकों ने पाया कि हवा की दिशा के कोण के आधार पर तंत्रिका अतिसंवेदनशील क्षेत्रों की स्थिति और आयाम इस जानकारी के प्रसारण को अधिकतम करने के लिए लगभग इष्टतम हैं। इसके अलावा, अन्य संदर्भों में, निरर्थक या संयुक्त कोड का उपयोग करने के सूचक परिणाम दिए गए हैं। मोटर कोर्टेक्स में, यह सर्वविदित है कि दिशात्मक न्यूरॉन्स की विकिरण आवृत्तियों का भारित सटीकता सटीकता के साथ आंदोलन की भविष्यवाणी करता है, अर्थात, दालों की संख्या के आधार पर कोडिंग।
इस तरह के कार्यों को निष्पादित करना एनक्रिप्ट के काम के रूप में व्याख्या की जा सकती है, जो विभिन्न प्रकार की सरल एन्क्रिप्शन कुंजी पेश करता है। उदाहरण के लिए, अल्फ़ान्यूमेरिक, वर्णमाला में इसके क्रम संख्या के प्रत्येक अक्षर को प्रतिस्थापित करता है। इसके अलावा, पाठ को पूरी तरह से एन्कोड करने के लिए, विराम चिह्न और अन्य प्रतीकों को वर्णमाला में दर्ज किया जाना चाहिए। छात्रों को लोअरकेस और लोअरकेस अक्षरों के बीच अंतर करने का तरीका सोचने के लिए आमंत्रित करें।
दृश्य प्रणाली में कोर्टेक्स 1 टी में मुखौटा की सुविधाओं के ऐसे कोडिंग का प्रमाण है। संयुक्त कोडिंग का एक उदाहरण न्यूरॉन्स की थरथरानवाला प्रतिक्रियाओं का सिंक्रनाइज़ेशन है, जब उनके अतिसंवेदनशील क्षेत्र दृश्य के क्षेत्र में एक ही वस्तु के भीतर स्थित होते हैं। इन प्रयोगों में ऑब्जेक्ट ऐसे क्षेत्र हैं जिनमें गति पैटर्न होते हैं जो साइनसोइड रूप से संशोधित होते हैं। यदि उन्हें अभिविन्यास, स्थानिक आवृत्ति, और गति की गति में उचित रूप से ठीक किया जाता है, तो ये पैटर्न दृश्य कॉर्टिकल कोशिकाओं से मजबूत कंपन संबंधी प्रतिक्रियाओं का कारण बन सकते हैं, और इन प्रतिक्रियाओं के चरण उत्तेजना के मॉड्यूलेशन द्वारा तय नहीं किए जाते हैं।
ऐसे कार्यों को करते समय, छात्रों को इस तथ्य पर ध्यान देना चाहिए कि एक अलग चरित्र आवश्यक है - एक स्थान, क्योंकि कोड है असमतल: कुछ अक्षरों को एक अंक के साथ एन्क्रिप्ट किया जाता है, कुछ - दो के साथ।
कोड में अक्षरों को अलग किए बिना कैसे करें, इसके बारे में सोचने के लिए छात्रों को आमंत्रित करें। इन प्रतिबिंबों को एक समान कोड का विचार करना चाहिए, जिसमें प्रत्येक वर्ण दो दशमलव अंकों द्वारा एन्कोड किया गया है: ए - 01, बी / 02, आदि।
यह पाया गया कि विभिन्न न्यूरॉन्स के दोलनों के चरण समान होते हैं यदि उनके लक्षित क्षेत्र एक ही वस्तु में आते हैं, लेकिन वे विभिन्न वस्तुओं पर नहीं गिरते हैं। किसी भी सेल की प्रतिक्रिया केवल ऑब्जेक्ट के प्रकार को एन्कोड करती है। यह ऑब्जेक्ट के आकार, आकार और किनारों के बारे में कुछ भी सांकेतिक शब्दों में बदलना नहीं करता है। आप कल्पना कर सकते हैं कि अन्य कोशिकाएं हैं जो ऐसा करती हैं, लेकिन कॉम्बिनेटरियल कार्य बहुत बड़ा है: सभी विभिन्न आकृतियों और स्थितियों के लिए न्यूरॉन्स होना चाहिए, लेकिन यह न्यूरॉन इस प्रकार की पहचान नहीं था। ऐसा लगता है कि वस्तुओं में दृश्य दृश्य का विभाजन इस तरह से एन्कोड किया गया है कि दोलन चरण तय हो गया है।
एन्कोडिंग और एन्क्रिप्टिंग जानकारी के लिए कार्यों का चयन कई स्कूल पाठ्यपुस्तकों में उपलब्ध है।
बुनियादी स्कूल के लिए बुनियादी सूचना विज्ञान पाठ्यक्रम में, कोडिंग का विषय काफी हद तक विभिन्न प्रकार के डेटा के कंप्यूटर में प्रतिनिधित्व के विषय से जुड़ा हुआ है: संख्या, ग्रंथ, चित्र, ध्वनि (देखें) सूचना प्रौद्योगिकी” 2).
आपको नहीं पता कि यह कोडिंग तंत्र कितना सामान्य है। रिचमंड और ऑप्टीकन जैसे स्थिर "भड़क" उत्तेजनाओं के प्रयोगों में, हमने बताया कि कोई दोलन नहीं देखा गया था; शायद इस मामले में यह विशेष तंत्र अनुपलब्ध है। यहां तक कि ऐसे मामलों में जहां दोलन होते हैं, हम नहीं जानते कि क्या वे कोडिंग तंत्र के लिए महत्वपूर्ण हैं या केवल एक माध्यमिक कारक हैं।
हाल ही में एक बंदर के श्रवण प्रांतस्था में दोलनों की अनुपस्थिति में सिंक्रनाइज़ेशन का मामला देखा गया है। यह पाया गया कि विभिन्न न्यूरॉन्स के उत्सर्जन में तुल्यकालन की डिग्री एक उत्तेजना की उपस्थिति का संकेत देती है, तब भी जब उनकी विकिरण आवृत्तियां किसी भी जानकारी को प्रसारित नहीं करती हैं। प्रभाव एक जोड़ी न्यूरॉन्स के लिए कमजोर है, लेकिन यह बड़ी आबादी के सिंक्रनाइज़ेशन की डिग्री से सार्थक जानकारी प्राप्त कर सकता है। इसलिए, सिस्टम दालों की संख्या के आधार पर कोडिंग का उपयोग करता है, लेकिन न्यूरॉन्स में जोड़ा गया चर विकिरण आवृत्ति के बजाय नाड़ी सहसंबंध की डिग्री है।
ऊपरी ग्रेड में, सामान्य शिक्षा या वैकल्पिक पाठ्यक्रम की सामग्री कोडिंग के सिद्धांत से अधिक पूरी तरह से संबोधित हो सकती है, सूचना सिद्धांत के ढांचे में सी। शैनन द्वारा विकसित की गई है। यहां कई दिलचस्प समस्याएं हैं, जिनमें से समझ में छात्रों के गणितीय और प्रोग्रामर प्रशिक्षण के एक बढ़े हुए स्तर की आवश्यकता है। ये किफायती कोडिंग, सार्वभौमिक कोडिंग एल्गोरिथ्म, त्रुटि सुधार कोडिंग की समस्याएं हैं। विस्तार से, इनमें से कई सवालों का खुलासा पाठ्यपुस्तक "सूचना के गणितीय नींव" में किया गया है।
प्रसंस्करण जानकारी
सूचना संसाधन -सूचना की सामग्री या प्रस्तुति को व्यवस्थित रूप से बदलने की प्रक्रिया.
सूचना प्रसंस्करण कुछ विषय या वस्तु (उदाहरण के लिए, एक व्यक्ति या एक स्वचालित उपकरण) द्वारा कुछ नियमों के अनुसार किया जाता है। उसे बुला लेंगे सूचना प्रसंस्करण के निष्पादक.
बाहरी वातावरण के साथ बातचीत करने वाला, इससे प्राप्त होता है इनपुट जानकारीउस पर कार्रवाई की जा रही है। प्रसंस्करण का परिणाम है आउटपुट जानकारीबाहरी वातावरण में संचारित। इस प्रकार, बाहरी वातावरण इनपुट जानकारी के स्रोत और आउटपुट सूचना के उपभोक्ता के रूप में कार्य करता है।
कलाकार को ज्ञात कुछ नियमों के अनुसार सूचना प्रसंस्करण होता है। प्रसंस्करण नियम, जो व्यक्तिगत प्रसंस्करण चरणों के अनुक्रम का वर्णन करते हैं, को सूचना प्रसंस्करण एल्गोरिदम कहा जाता है।
प्रोसेसिंग एजेंट के पास एक प्रोसेसिंग ब्लॉक होना चाहिए, जिसे हम प्रोसेसर कहेंगे, और मेमोरी ब्लॉक, जिसमें संसाधित जानकारी और प्रसंस्करण नियम (एल्गोरिथम) दोनों संग्रहीत हैं। ऊपर दिए गए सभी आंकड़े में योजनाबद्ध रूप से दिखाए गए हैं।
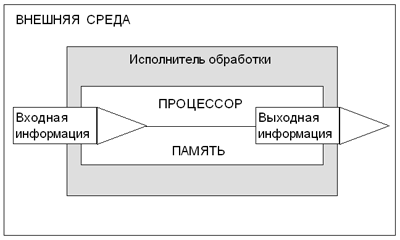
सूचना प्रसंस्करण योजना
एक उदाहरण है।एक छात्र, एक पाठ में एक समस्या को हल करने, सूचना प्रसंस्करण करता है। उसके लिए बाहरी वातावरण सबक की स्थिति है। इनपुट जानकारी - समस्या की स्थिति, जो पाठ का नेतृत्व करने वाले शिक्षक द्वारा बताई गई है। छात्र समस्या की स्थिति को याद करता है। संस्मरण की सुविधा के लिए, वह एक नोटबुक में नोट्स का उपयोग कर सकता है - बाहरी मेमोरी। शिक्षक के स्पष्टीकरण से, उन्होंने समस्या को हल करने का तरीका सीखा (याद किया)। एक प्रोसेसर एक छात्र की सोच का उपकरण है, जिसका उपयोग करके किसी समस्या को हल करने के लिए, यह एक उत्तर - आउटपुट जानकारी प्राप्त करता है।
आकृति में प्रस्तुत योजना एक सामान्य सूचना प्रसंस्करण योजना है, चाहे कोई भी हो (या क्या) प्रसंस्करण का निष्पादनकर्ता है: एक जीवित जीव या एक तकनीकी प्रणाली। यह कंप्यूटर में तकनीकी साधनों द्वारा कार्यान्वित योजना है। इसलिए, हम कह सकते हैं कि कंप्यूटर एक "लाइव" सूचना प्रसंस्करण प्रणाली का एक तकनीकी मॉडल है। इसमें प्रसंस्करण प्रणाली के सभी मुख्य घटक शामिल हैं: प्रोसेसर, मेमोरी, इनपुट डिवाइस, आउटपुट डिवाइस (देखें) कंप्यूटर उपकरण " 2).
प्रतीकात्मक रूप में प्रस्तुत इनपुट जानकारी (संकेत, अक्षर, संख्या, संकेत), कहलाता है इनपुट डेटा। कलाकार द्वारा प्रसंस्करण के परिणामस्वरूप, आउटपुट डेटा। इनपुट और आउटपुट डेटा मूल्यों का एक सेट हो सकता है - व्यक्तिगत डेटा तत्व। यदि प्रसंस्करण गणितीय गणना में है, तो इनपुट और आउटपुट डेटा संख्याओं के सेट हैं। निम्नलिखित आंकड़ा एक्स: {एक्स1, एक्स2, …, xn) इनपुट डेटा के एक सेट को दर्शाता है, और Y: {y1, y2, …, ym) - आउटपुट डेटा का सेट:

डाटा प्रोसेसिंग सर्किट
प्रसंस्करण सेट को बदलना है एक्स सेट में Y:
पी(एक्स) Y
यहां पी कलाकार द्वारा उपयोग किए जाने वाले प्रसंस्करण नियमों को इंगित करता है। यदि सूचना प्रसंस्करण करने वाला व्यक्ति एक व्यक्ति है, तो प्रसंस्करण नियम जिसके लिए वह कार्य करता है, वह हमेशा औपचारिक और अस्पष्ट नहीं होता है। एक व्यक्ति अक्सर रचनात्मक रूप से कार्य करता है, औपचारिक रूप से नहीं। यहां तक कि एक ही गणित की समस्याओं को वह विभिन्न तरीकों से हल कर सकता है। एक पत्रकार, वैज्ञानिक, अनुवादक और अन्य विशेषज्ञों का काम एक रचनात्मक कार्य है जिसमें जानकारी होती है कि वे औपचारिक नियमों का पालन नहीं करते हैं।
सूचना प्रसंस्करण चरणों के अनुक्रम को निर्धारित करने वाले औपचारिक नियमों को नामित करने के लिए, कंप्यूटर विज्ञान एक एल्गोरिथ्म की अवधारणा का उपयोग करता है (देखें) एल्गोरिथम ” 2)। गणित में एक एल्गोरिथ्म की अवधारणा दो प्राकृतिक संख्याओं के सबसे बड़े सामान्य भाजक (GCD) की गणना के लिए एक प्रसिद्ध विधि से जुड़ी है, जिसे यूक्लिडियन एल्गोरिदम कहा जाता है। मौखिक रूप में, इसे इस प्रकार वर्णित किया जा सकता है:
1. यदि दो संख्याएं एक-दूसरे के बराबर हैं, तो उनका समग्र अर्थ जीसीडी के लिए लिया जाना चाहिए, अन्यथा चरण 2 पर जाएं।
2. यदि संख्याएँ भिन्न हैं, तो उनमें से बड़े को संख्याओं के बड़े और छोटे के अंतर से बदल दिया जाता है। चरण 1 पर लौटें।
यहाँ इनपुट डेटा दो प्राकृतिक संख्याएँ हैं - एक्स1 और एक्स2. परिणाम Y - उनकी सबसे बड़ी आम भाजक। नियम ( पी) एक यूक्लिडियन एल्गोरिथ्म है:
यूक्लिडियन एल्गोरिथ्म ( एक्स1, एक्स2) Y
इस तरह के एक औपचारिक एल्गोरिथ्म एक आधुनिक कंप्यूटर के लिए प्रोग्राम करना आसान है। कंप्यूटर डाटा प्रोसेसिंग का एक सार्वभौमिक प्रदर्शनकर्ता है। एक औपचारिक प्रसंस्करण एल्गोरिथ्म को कंप्यूटर की मेमोरी में स्थित प्रोग्राम के रूप में दर्शाया जाता है। कंप्यूटर प्रसंस्करण नियमों के लिए ( पी) एक कार्यक्रम है।
"सूचना प्रसंस्करण" विषय की व्याख्या करते हुए, प्रसंस्करण की मिसालें देना आवश्यक है, दोनों नई जानकारी प्राप्त करने से संबंधित हैं और सूचना के प्रस्तुतीकरण के रूप में परिवर्तन से संबंधित हैं।
पहले प्रकार की प्रोसेसिंग: नई जानकारी, ज्ञान की नई सामग्री प्राप्त करने से जुड़ी प्रक्रिया। इस प्रकार के प्रसंस्करण में गणितीय समस्याओं का समाधान शामिल है। इस प्रकार की सूचना प्रसंस्करण में तार्किक तर्क को लागू करके विभिन्न समस्याओं को हल करना शामिल है। उदाहरण के लिए, एक अन्वेषक कुछ सबूतों के अनुसार एक अपराधी पाता है; एक व्यक्ति, परिस्थितियों का विश्लेषण करते हुए, अपने आगे के कार्यों के बारे में निर्णय लेता है; वैज्ञानिक प्राचीन पांडुलिपियों, आदि के रहस्य को उजागर करता है।
दूसरे प्रकार की प्रोसेसिंग: फॉर्म को बदलने से जुड़ी प्रक्रिया, लेकिन सामग्री को बदलने से नहीं। इस प्रकार की सूचना प्रसंस्करण में शामिल है, उदाहरण के लिए, एक भाषा से दूसरी भाषा में पाठ का अनुवाद: रूप बदलता है, लेकिन सामग्री को संरक्षित किया जाना चाहिए। सूचना विज्ञान के लिए एक महत्वपूर्ण प्रकार का प्रसंस्करण कोडिंग है। कोडिंग - यह है अपने भंडारण, पारेषण, प्रसंस्करण के लिए सुविधाजनक रूप में सूचना का रूपांतरण (देखें) कोडिंग” 2).
संरचना डेटा को दूसरे प्रकार के प्रसंस्करण के लिए भी जिम्मेदार ठहराया जा सकता है। संरचना एक विशिष्ट आदेश, सूचना भंडार में एक निश्चित संगठन की शुरूआत के साथ जुड़ा हुआ है। वर्णानुक्रम में डेटा की व्यवस्था, कुछ वर्गीकरण मानदंडों के अनुसार समूहीकरण, एक तालिका या ग्राफ़ प्रतिनिधित्व का उपयोग करके संरचना के सभी उदाहरण हैं।
एक विशेष प्रकार की सूचना प्रसंस्करण है खोज. खोज कार्य आमतौर पर निम्नानुसार तैयार किया जाता है: सूचना का कुछ भंडार है - जानकारी सरणी (टेलीफोन डायरेक्टरी, डिक्शनरी, ट्रेन शेड्यूल इत्यादि), इसमें आवश्यक जानकारी को निश्चित रूप से संतुष्ट करना आवश्यक है खोज शब्द(संगठन का फोन, अंग्रेजी में शब्द का अनुवाद, ट्रेन का प्रस्थान समय)। खोज एल्गोरिदम जानकारी के व्यवस्थित होने के तरीके पर निर्भर करता है। यदि जानकारी संरचित है, तो खोज तेज है, इसे अनुकूलित किया जा सकता है (देखें) खोज डेटा " 2).
प्रचारक सूचना विज्ञान पाठ्यक्रम में, "ब्लैक बॉक्स" की समस्याएं लोकप्रिय हैं। प्रसंस्करण एजेंट को "ब्लैक बॉक्स" माना जाता है, अर्थात प्रणाली, आंतरिक संगठन और तंत्र जिसके बारे में हम नहीं जानते। कार्य डेटा प्रोसेसिंग नियम (पी) का अनुमान लगाना है जो कि निष्पादक लागू करता है।
उदाहरण 1
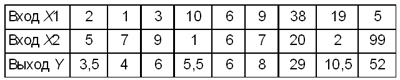
प्रसंस्करण एजेंट इनपुट मूल्यों के औसत मूल्य की गणना करता है: Y = (एक्स1 +एक्स2)/2
उदाहरण 2
प्रवेश द्वार पर - रूसी शब्द, बाहर निकलने पर - स्वरों की संख्या।
सूचना प्रसंस्करण के मुद्दों का सबसे गहरा असर तब होता है जब मात्रा और प्रोग्रामिंग (प्राथमिक और उच्च विद्यालय में) के साथ काम करने के एल्गोरिदम का अध्ययन किया जाता है। इस मामले में सूचना प्रसंस्करण का निष्पादन कंप्यूटर है, और सभी प्रसंस्करण क्षमताओं को प्रोग्रामिंग भाषा में शामिल किया गया है। प्रोग्रामिंग वहाँ है आउटपुट डेटा प्राप्त करने के लिए इनपुट डेटा को संसाधित करने के लिए नियमों का वर्णन.
छात्रों को दो प्रकार के कार्य करने चाहिए:
प्रत्यक्ष कार्य: समस्या को हल करने के लिए एक एल्गोरिथ्म (प्रोग्राम) बनाएं;
उलटा समस्या: एल्गोरिथम को देखते हुए, आप एल्गोरिथ्म को ट्रेस करके इसके निष्पादन के परिणाम को निर्धारित करना चाहते हैं।
उलटे समस्या को हल करते समय, छात्र खुद को एक प्रोसेसिंग कॉन्ट्रैक्टर की स्थिति में रखता है, स्टेप बाई स्टेप एल्गोरिदम का प्रदर्शन करता है। प्रत्येक चरण में निष्पादन के परिणाम ट्रेस टेबल में परिलक्षित होने चाहिए।
सूचना हस्तांतरण

आज फ्लोरोसेंट लैंप के बिना बड़े ट्रेडिंग, शैक्षिक, कार्यालय और गोदाम परिसर की कल्पना करना मुश्किल है ...

कॉन्टेक्ट लेंस जिसमें दृष्टि को ठीक करने का उद्देश्य है, को अकल्पनीय ऑप्टिकल माना जा सकता है ...

वोल्टेज ट्रांसफार्मर को मापने। क) सामान्य जानकारी और वायरिंग आरेख वोल्टेज ट्रांसफार्मर के लिए डिज़ाइन किया गया है ...

पाठ का स्थान: ग्रेड 9 - अध्ययन किए गए खंड का पाठ 3। पाठ का विषय: द्विआधारी संख्या प्रणाली में अंकगणितीय संचालन। देखें ...
4.15.1। समर्थन के तत्वों के प्रतिस्थापन पर काम करता है, समर्थन का समापन और ओवरहेड लाइनों के तारों को प्रवाह चार्ट के अनुसार किया जाना चाहिए या ...

विद्युत ऊर्जा का मीटर "बुध - 201" वर्तमान में हमारे देश में सबसे लोकप्रिय उपकरण है ...

कोड टेबल book 13 एक दिलचस्प कहानी का हवाला हां "आई। पेरेलमैन" ने अपनी पुस्तक "मनोरंजक अंकगणित" में दिया। में ...
सभी को नमस्कार! आज मैं आपको बताऊंगा कि तालिका के अनुसार एक्सेल में आरेख का निर्माण कैसे करें। हां, हमारे साथ फिर से उत्कृष्टता प्राप्त करें ...

मानक स्विच का संचालन करते समय, आप केवल लैंप की अधिकतम चमक प्राप्त कर सकते हैं। लेकिन वहाँ हैं ...

एसी पावर सर्किट में धाराओं को मापने के लिए वर्तमान ट्रांसफार्मर का उपयोग किया जाता है। वे के रूप में लागू कर रहे हैं ...

सबसे अच्छा ध्रुवीकृत धूप का चश्मा विभिन्न रूपों और कार्यों में उपलब्ध हैं, उच्च की सभी उपलब्धियों के साथ ...
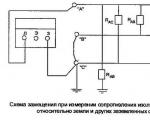
तारों के साथ समस्याओं के मामले में, मरम्मत कार्य के दौरान और बाद में केबल चालू करते समय - इन सभी में ...

ऐसी कई परिस्थितियां हैं जहां यह जानना उपयोगी होगा कि मल्टीमीटर के साथ प्रतिरोध को कैसे मापें और क्या अंतर है ...
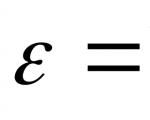
शैक्षिक स्थापना "संचार के संगोष्ठी संगोष्ठी" मौजूदा स्रोत के इलेक्ट्रो-बढ़ते बिजली की ...
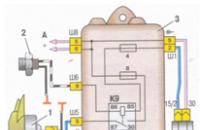
आज, प्रौद्योगिकी के इतनी तेजी से विकास के साथ, यह जानना बहुत महत्वपूर्ण है कि कार इलेक्ट्रिकल सर्किट कैसे पढ़ें। और नहीं ...

एक घर बनाने और अपने क्षेत्र के उपकरण के मामले में, कई मुद्दे महत्वपूर्ण हैं। सहित से दूरी ...