मुड़ जोड़ी कनेक्टर्स
सबसे लोकप्रिय और मांग वाले कनेक्टर प्रकारों में से एक बीएनसी कनेक्टर है। यह विभिन्न वीडियो में प्रयोग किया जाता है और ...
अमूर्त
थीम: "कंप्यूटिंग में जानकारी एन्कोडिंग के आधुनिक तरीके"।
तैयार किया है
:
अवनेसन वेरोनिका
Arkadievna
समूह के छात्रA 6 "ए"
जाँच
:
टकाचेव सर्गेई
Nikolaevich
स्कोर ______________
सोची
2011-2012 शैक्षणिक वर्ष
सामग्री:
1. परिचय
2. कोडिंग की जानकारी का इतिहास
3. एन्कोडिंग जानकारी के तरीके
4. पाठ जानकारी एन्कोडिंग
5. कोडिंग ग्राफिक जानकारी
6. ध्वनि की जानकारी एन्कोडिंग
7. निष्कर्ष और निष्कर्ष
8. प्रयुक्त साहित्य की सूची
4. शोर उन्मुक्ति द्वारा:
सरल
(आदिम, पूर्ण) - सभी संभव कोड संयोजनों (अतिरेक के बिना) का उपयोग करके जानकारी स्थानांतरित करने के लिए;
सुधार
(विरोधी हस्तक्षेप) - संदेशों के प्रसारण के लिए, सभी नहीं बल्कि केवल (अनुमत) कोड संयोजनों का एक हिस्सा उपयोग किया जाता है।
5. उद्देश्य और अनुप्रयोग के आधार पर, निम्न प्रकार के कोडों को अलग करना सशर्त रूप से संभव है:
आंतरिक कोड -
यह है
उपकरणों के अंदर उपयोग किए गए कोड। ये मशीन कोड हैं, साथ ही साथ स्थितीय संख्या प्रणाली (बाइनरी, दशमलव, बाइनरी-दशमलव, ऑक्टल, हेक्साडेसिमल, आदि) के उपयोग के आधार पर कोड हैं। कंप्यूटर में सबसे आम कोड है बाइनरी कोडजो आपको केवल बाइनरी कोड में डेटा को संग्रहीत करने, प्रसंस्करण और संचारित करने के लिए एक हार्डवेयर डिवाइस को लागू करने की अनुमति देता है। यह उपकरणों की उच्च विश्वसनीयता और बाइनरी कोड में डेटा पर संचालन करने में आसानी प्रदान करता है। 4 के समूहों में संयुक्त बाइनरी डेटा, एक हेक्साडेसिमल कोड बनाते हैं, जो कंप्यूटर आर्किटेक्चर के साथ एक बाइट (8 बिट्स) के डेटा मल्टीपल के साथ काम करते हुए अच्छे समझौते में है।
डेटा एक्सचेंज कोड
और संचार चैनलों पर उनका प्रसारण
। पीसी में व्यापक रूप से एएससीआईआई कोड (सूचना मानक के लिए अमेरिकी मानक कोड) प्राप्त हुआ। ASCII एक 7-बिट अल्फ़ान्यूमेरिक कोड और अन्य वर्ण है। चूंकि कंप्यूटर बाइट्स के साथ काम करते हैं, 8 वें अंक का उपयोग सिंक्रनाइज़ या यहां तक कि जांच करने या कोड को विस्तारित करने के लिए किया जाता है। IBM कंप्यूटर विस्तारित बाइनरी कोडेड दशमलव इंटरचेंज कोड (EBCDIC) का उपयोग करता है।
संचार चैनलों का व्यापक रूप से टेलेटाइप कोड CCITT (टेलीफोनी और टेलीग्राफी पर अंतर्राष्ट्रीय सलाहकार समिति) और इसके संशोधनों (ITC, आदि) में उपयोग किया जाता है।
जब संचार रास्तों पर संचरण के लिए सूचनाओं को एन्कोडिंग करना, हार्डवेयर पथों के भीतर, कोड्स का उपयोग अधिकतम सूचना अंतरण दर सुनिश्चित करने के लिए किया जाता है, इसके संपीड़न और अतिरेक के उन्मूलन के कारण (उदाहरण के लिए: हफ़मैन और शैनन-फ़ानो कोड), और डेटा ट्रांसमिशन विश्वसनीयता कोड। प्रेषित संदेशों में अतिरेक की शुरुआत के कारण (उदाहरण के लिए: समूह कोड, हैमिंग, चक्रीय और उनकी किस्में)।
विशेष अनुप्रयोगों के लिए कोड
- ये डेटा ट्रांसमिशन और प्रोसेसिंग की विशेष समस्याओं को हल करने के लिए डिज़ाइन किए गए कोड हैं। ऐसे कोड के उदाहरण ग्रे चक्रीय कोड हैं, जो कोणीय और रैखिक विस्थापन के एडीसी में व्यापक रूप से उपयोग किया जाता है। उच्च गति और मजबूत एडीसी के निर्माण के लिए फाइबोनैचि कोड का उपयोग किया जाता है।
पाठ्यक्रम डेटा के आदान-प्रदान और संचार चैनलों पर इसे प्रसारित करने के लिए कोड पर केंद्रित है।
कोडिंग का उद्देश्य:
1) अधिकतम डेटा अंतरण दर को प्राप्त करके, डेटा स्थानांतरण की दक्षता में सुधार।
2) डेटा ट्रांसमिशन में शोर प्रतिरक्षा में सुधार।
इन लक्ष्यों के अनुसार, कोडिंग सिद्धांत दो मुख्य दिशाओं में विकसित होता है:
1. किफायती (कुशल, इष्टतम) कोडिंग का सिद्धांत
उन स्रोतों की तलाश कर रहा है जो संचार माध्यम बैंडविड्थ के साथ स्रोत अतिरेक और सर्वश्रेष्ठ मिलान डेटा अंतरण दर को समाप्त करके सूचना हस्तांतरण की दक्षता बढ़ाने के लिए बिना हस्तक्षेप के चैनलों की अनुमति देते हैं।
2. Noiseproof कोडिंग का सिद्धांत
हस्तक्षेप के साथ चैनलों में सूचना प्रसारण की विश्वसनीयता बढ़ाने वाले कोड की खोज में लगा हुआ है।
कोडिंग जानकारी का इतिहास:
कोड - सूचना की प्रस्तुति के लिए प्रतीकों का एक सेट।
एन्कोडिंग - कोड के रूप में जानकारी प्रस्तुत करने की प्रक्रिया (दूसरे के प्रतीकों द्वारा एक वर्णमाला के प्रतीकों का प्रतिनिधित्व; सूचना के प्रतिनिधित्व के एक रूप से दूसरे में संक्रमण, भंडारण, स्थानांतरण या प्रसंस्करण के लिए अधिक सुविधाजनक)।
प्रतिलोम परिवर्तन कहलाता है डिकोडिंग।
एक दूसरे के साथ संवाद करने के लिए, हम कोड का उपयोग करते हैं - रूसी भाषा।
एक बातचीत के दौरान, यह कोड ध्वनियों द्वारा, लेखन द्वारा - पत्रों द्वारा प्रेषित होता है।
चालक एक बीप या ब्लिंकिंग हेडलाइट्स के साथ एक संकेत प्रसारित करता है।
ट्रैफिक लाइट के रूप में सड़क पार करते समय आपको सूचना के कोडिंग का सामना करना पड़ता है।
इस प्रकार, कड़ाई से परिभाषित नियमों के अनुसार पात्रों के एक सेट के उपयोग के लिए कोडिंग कम हो जाती है।
कोडिंग विधि उस उद्देश्य पर निर्भर करती है जिसके लिए इसे किया जाता है:
इस तरह के एक वर्णमाला के उपयोग में आसानी के लिए, हम इसके किसी भी चरित्र को कॉल करने के लिए सहमत हुए। "बिट" (अंग्रेजी से "द्वि नैरी डिगीटी "- द्विआधारी संकेत).
एक बिट को दो अवधारणाओं द्वारा व्यक्त किया जा सकता है: 0 या 1 (हां या नहीं, काला या सफेद, सच्चा या गलत, आदि)।
बाइनरी नंबर इलेक्ट्रॉनिक उपकरणों का उपयोग करके स्टोर करने और संचारित करने के लिए बहुत सुविधाजनक हैं।
उदाहरण के लिए, 1 और 0 एक डिस्क के चुम्बकीय और अनमैग्नेटाइज्ड क्षेत्रों के अनुरूप हो सकते हैं; शून्य और गैर-शून्य वोल्टेज; सर्किट में करंट की मौजूदगी और अनुपस्थिति आदि।
इसलिये भौतिक स्तर पर कंप्यूटर में डेटा बाइनरी कोड में संग्रहीत, संसाधित और प्रेषित होता है।
बिट्स का एक क्रम पाठ, छवि, ध्वनि या किसी अन्य जानकारी को एन्कोड कर सकता है। जानकारी प्रस्तुत करने की इस विधि को कहा जाता है बाइनरी कोडिंग .
इस प्रकार, बाइनरी कोड एन्कोडिंग जानकारी का एक सार्वभौमिक साधन है।
यह देखते हुए कि प्रत्येक बिट मान 0 या 1 लेता है, बाइट में संभावित संयोजनों की संख्या होती है
तो, 1 बाइट की मदद से, आप 256 अलग-अलग बाइनरी कोड संयोजन प्राप्त कर सकते हैं और उनकी सहायता से 256 विभिन्न वर्ण प्रदर्शित कर सकते हैं।
इस तरह के कई अक्षर पाठ संबंधी जानकारी का प्रतिनिधित्व करने के लिए पर्याप्त हैं, जिसमें रूसी और लैटिन वर्णमाला के ऊपरी और निचले मामले पत्र, संख्याएं, संकेत, ग्राफिक प्रतीक आदि शामिल हैं।
एन्कोडिंग है कि प्रत्येक वर्ण को 0 से 255 तक एक अद्वितीय दशमलव कोड या इसके संबंधित बाइनरी कोड को 00000000 से 11111111 तक सौंपा गया है।
इस प्रकार, एक व्यक्ति अपने प्रकार से और एक कंप्यूटर द्वारा वर्णों को अलग करता है - उनके कोड द्वारा।
यह महत्वपूर्ण है कि किसी विशिष्ट कोड को प्रतीक के रूप में असाइन करना समझौते का विषय है, जो इसमें तय किया गया है कोड तालिका.
ASCII प्रणाली में दो कोडिंग टेबल तय की गई हैं - मूल और विस्तारित.
बेस टेबल 0 से 127 तक के कोड के मूल्यों को ठीक करता है, और विस्तारित तालिका 128 से 255 तक की संख्या वाले वर्णों को संदर्भित करती है।
पहले 33 कोड (0 से 32 तक) वर्णों के अनुरूप नहीं हैं, लेकिन संचालन (लाइन फीड, स्पेस एंट्री, आदि) के लिए।
कोड 33 से 127 अंतरराष्ट्रीय हैं और लैटिन वर्णमाला, संख्याओं, अंकगणितीय संकेतों और विराम चिह्नों के अनुरूप हैं।
कोड 128 से 255 राष्ट्रीय हैं, अर्थात् राष्ट्रीय कोडिंग में, विभिन्न प्रतीक एक ही कोड के अनुरूप होते हैं।
| सी |
हे |
एम |
पी |
यू |
टी |
ए |
आर |
| 67 |
79 |
77 |
80 |
85 |
84 |
69 |
82 |
| 01000011 |
01001111 |
01001101 |
01010000 |
01010101 |
01010100 |
01000101 |
01010010 |
दुनिया में आधुनिक सूचना प्रौद्योगिकी के प्रसार के साथ, अन्य भाषाओं के वर्णों के अक्षरों को सांकेतिक शब्दों में बदलना आवश्यक हो गया: जापानी, कोरियाई, अरबी, हिंदी, साथ ही साथ अन्य विशेष वर्ण।
पुरानी सार्वभौमिक प्रणाली ने नए की जगह ले ली है - यूनिकोडजिसमें एक वर्ण एक नहीं बल्कि दो बाइट्स में एन्कोड किया गया है।
वर्तमान में, कई अलग-अलग कोड टेबल (DOS, ISO, WINDOWS, KOI8-R, KOI8-U, UNICODE, आदि) हैं, इसलिए एक एन्कोडिंग में बनाए गए ग्रंथों को दूसरे में सही ढंग से प्रदर्शित नहीं किया जा सकता है।
आइए एक आवर्धक कांच के माध्यम से कंप्यूटर स्क्रीन को देखें।
तकनीक के मेक और मॉडल के आधार पर, हम या तो बहुरंगी आयतों की भीड़ या बहुरंगी हलकों की भीड़ देखेंगे।
और उन और दूसरों को तीन टुकड़ों में बांटा गया है, एक ही रंग के, लेकिन अलग-अलग रंगों के।
उन्हें PIXels (अंग्रेजी से) कहा जाता है पिक्चर का एलिमेंट).
पिक्सेल केवल तीन रंगों में आते हैं - हरा, नीला और लाल।
रंगों को मिलाकर अन्य रंग बनाए जाते हैं।
सबसे सरल मामले पर विचार करें - पिक्सेल का प्रत्येक टुकड़ा या तो जलाया जा सकता है (1) या नहीं जलाया जा सकता है (0)।
फिर हमें रंगों का निम्नलिखित सेट मिलता है:
तीन रंगों में से आप आठ संयोजन प्राप्त कर सकते हैं।
एक अमीर रंग पैलेट प्राप्त करने के लिए, विभिन्न तीव्रता को बेस रंगों में सेट किया जा सकता है, फिर विभिन्न रंगों और रंगों को देते हुए, उनके संयोजन के विभिन्न वेरिएंट की संख्या बढ़ जाती है।
16-रंग पैलेट को 4-बिट पिक्सेल कोडिंग का उपयोग करके प्राप्त किया जाता है: बेस रंगों के तीन बिट्स में एक बिट की तीव्रता को जोड़ा जाता है। यह बिट एक ही समय में सभी तीन रंगों की चमक को नियंत्रित करता है।
मॉनिटर स्क्रीन पर पुन: उत्पन्न रंगों की संख्या ( एन), और प्रत्येक पिक्सेल के लिए वीडियो मेमोरी में आवंटित बिट्स की संख्या ( मैं) सूत्र द्वारा संबंधित हैं:
मूल्य मैं बिट गहराई या रंग गहराई कहा जाता है।
जितने अधिक बिट्स का उपयोग किया जाता है, उतने अधिक रंग के शेड मिल सकते हैं।
तो, स्क्रीन पर किसी भी ग्राफिक छवि को संख्याओं का उपयोग करके एन्कोड किया जा सकता है, जिसमें बताया गया है कि प्रत्येक पिक्सेल में कितने पिक्सेल लाल हैं, कितने हरे हैं, और कितने नीले हैं।
भी ग्राफिक जानकारी एक वेक्टर छवि के रूप में प्रतिनिधित्व किया जा सकता है।
वेक्टर छवि एक ग्राफिक ऑब्जेक्ट है जिसमें प्रारंभिक लाइनें और आर्क शामिल हैं।
इन प्राथमिक वस्तुओं की स्थिति बिंदुओं और त्रिज्या की लंबाई के निर्देशांक द्वारा निर्धारित की जाती है।
प्रत्येक पंक्ति के लिए, इसके प्रकार (ठोस, बिंदीदार, डैश-बिंदीदार), मोटाई और रंग का संकेत दिया जाता है।
वेक्टर छवि के बारे में जानकारी सामान्य अल्फ़ान्यूमेरिक के रूप में एन्कोड की गई है और विशेष कार्यक्रमों द्वारा संसाधित की गई है।
छवि की गुणवत्ता मॉनिटर के रिज़ॉल्यूशन द्वारा निर्धारित की जाती है, अर्थात। अंकों की संख्या जिसमें से इसे जोड़ा जाता है।
अधिक से अधिक संकल्प, अर्थात्। अधिक रेखापुंज रेखाएँ और एक रेखा में बिंदु, छवि की गुणवत्ता जितनी अधिक होगी।
10. कोडिंग जानकारी के प्रकार।
कोड - कुछ नियमों के अनुसार किसी चिह्न या वर्णों के समूह वाली वस्तु का प्रतीक। कोड असाइन करने के बाद, एक क्लासिफायरियर बनाया जाता है - सजातीय नामों और उनके कोड पदनामों का एक व्यवस्थित सेट। क्लासिफायर के दो उपयोग हैं। पहला दस्तावेज़ों में कोडों के मैनुअल affixing के लिए है। दूसरे मामले में, कोड का उपयोग मशीन कैरियर्स पर मशीन की मेमोरी में सभी क्लासीफायर के भंडारण के लिए प्रदान करता है। कोड संख्यात्मक, अल्फ़ाबेटिक, अल्फ़ान्यूमेरिक हो सकते हैं और एक या कई वर्णों से मिलकर बन सकते हैं।
कोडिंग की जानकारी - मानक रूप में सूचना का प्रस्तुतीकरण। एक ही जानकारी को कई अलग-अलग रूपों में प्रस्तुत किया जा सकता है, और इसके विपरीत, अलग-अलग जानकारी को समान रूप में प्रस्तुत किया जा सकता है। उदाहरण के लिए, आप एक नए कार ब्रांड के मौखिक विवरण का उपयोग कर सकते हैं, या आप कई विस्तृत तस्वीरों में इसकी उपस्थिति प्रस्तुत कर सकते हैं। एक और उदाहरण - एक ही रूप के मेडिकल प्रमाणपत्र में एक ही उपस्थिति होती है, लेकिन विभिन्न रोगों का वर्णन करते हैं, क्योंकि वे अलग-अलग लोगों को जारी किए जाते हैं।
कंप्यूटर के आगमन के साथ, सभी प्रकार की सूचनाओं को कोड करने के लिए आवश्यकता उत्पन्न हुई, जिसके साथ एक व्यक्ति और समग्र रूप से मानवता के सभी दोनों को निपटना होगा। लेकिन कोडिंग जानकारी की समस्या को हल करने के लिए, कंप्यूटर के आगमन से पहले मानव जाति की शुरुआत हुई: मानवता की भव्य उपलब्धियां - लेखन और अंकगणित - भाषण और संख्यात्मक जानकारी के लिए कोडिंग सिस्टम से ज्यादा कुछ नहीं हैं।
कोडिंग नंबर
संख्याओं का उपयोग करने के लिए, आपको उन्हें कॉल करने और किसी भी तरह उन्हें लिखने की आवश्यकता है, आपको एक नंबरिंग सिस्टम की आवश्यकता है। विभिन्न गणना प्रणालियों और संख्या रिकॉर्डिंग ने हजारों वर्षों तक एक दूसरे के साथ मिलकर काम किया और एक दूसरे के साथ प्रतिस्पर्धा की, लेकिन "पूर्व युग" के अंत तक "संख्या" संख्या "दस" गणना में एक विशेष भूमिका निभाने लगी, और सबसे लोकप्रिय कोडिंग प्रणाली थी स्थिति दशमलव प्रणाली। इस प्रणाली में, एक संख्या में एक अंक का मूल्य एक संख्या के भीतर उसके स्थान (स्थिति) पर निर्भर करता है। दशमलव संख्या प्रणाली भारत से आई थी (6 वीं शताब्दी ईस्वी से बाद में नहीं)। इस प्रणाली की वर्णमाला: (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) केवल 10 अंक है, इसलिए संख्या प्रणाली का आधार 10. है। संख्या इकाइयों, दसियों, सैकड़ों, हजारों के संयोजन के रूप में लिखी गई है। और इसी तरह। उदाहरण: 1998 = 8 * 10 0 + 9 * 10 1 + 9 * 10 2 + 1 * 10 3।
बाबुल में, उदाहरण के लिए, 60-संख्या प्रणाली का उपयोग किया गया था, वर्णमाला में 1 से 59 तक संख्याएं थीं, संख्या 0 नहीं थी, गुणन सारणी बहुत बोझिल थीं, इसलिए बहुत जल्द ही इसे भुला दिया गया था, लेकिन इसकी व्यापकता की गूँज अब भी देखी जा सकती है - घंटे को विभाजित करना 60 मिनट तक, सर्कल को 360 डिग्री में विभाजित किया गया है।
बाइनरी नंबर सिस्टम
बाइनरी नंबर सिस्टम का आविष्कार गणितज्ञों और दार्शनिकों ने कंप्यूटर के आगमन से पहले किया था (XVII - XIX सदियों)। बाद में, बाइनरी सिस्टम को भुला दिया गया, और केवल 1 9 36 - 1938 में, अमेरिकी इंजीनियर और गणितज्ञ क्लाउड शैनन ने इलेक्ट्रॉनिक सर्किट के डिजाइन में बाइनरी सिस्टम के उल्लेखनीय अनुप्रयोग पाए।
बाइनरी से संबंधित नंबर सिस्टम हैं। कंप्यूटर के साथ काम करते समय, कभी-कभी आपको द्विआधारी संख्या से निपटना पड़ता है, क्योंकि बाइनरी नंबर कंप्यूटर के डिजाइन में शामिल। बाइनरी सिस्टम कंप्यूटर के लिए सुविधाजनक है, लेकिन किसी व्यक्ति के लिए असुविधाजनक - बहुत लंबी संख्या रिकॉर्ड और याद रखने के लिए असुविधाजनक है। बाइनरी-संबंधित ऑक्टल और हेक्साडेसिमल नंबर सिस्टम बचाव के लिए आते हैं।
उदाहरण के लिए, हेक्साडेसिमल प्रणाली में 10 अरबी अंकों और लैटिन वर्णमाला के अक्षरों (ए, बी, सी, डी, ई, एफ) का उपयोग संख्या लिखने के लिए किया जाता है। इस संख्या प्रणाली में एक संख्या लिखने के लिए, किसी संख्या के द्विआधारी प्रतिनिधित्व का उपयोग करना सुविधाजनक है। उदाहरण के लिए एक ही नंबर लें - बाइनरी सिस्टम में 2000 या 11111010000। इसे चार वर्णों में विभाजित करें, दाएं से बाएं की ओर बढ़ते हुए, बाईं ओर अंतिम चार में, हम एक तुच्छ 0 जोड़ते हैं, ताकि तीनों वर्णों की संख्या चार हो: 0111 1101 0000। आइए अनुवाद शुरू करते हैं - बाइनरी सिस्टम में संख्या 0111 दशमलव में 7 (7 10 = 1 *) से मेल खाती है। 2 0 + 1 * 2 1 + 1 * 2 2), हेक्साडेसिमल संकेतन में 7 है; बाइनरी सिस्टम में संख्या 1101 दशमलव (13 = 1 * 2 0 + 2 * 2 1 + 1 * 2 2 + 1 * 2 3) में संख्या 13 से मेल खाती है, हेक्साडेसिमल प्रणाली में यह संख्या अंक डी से मेल खाती है, और अंत में संख्या 0000 - किसी भी संख्या प्रणाली में 0. अब परिणाम लिखें:
11111010000 2 = 7D0 16।
समन्वय कोडिंग
आप न केवल संख्या, बल्कि अन्य जानकारी भी सांकेतिक शब्दों में बदलना कर सकते हैं। उदाहरण के लिए, वस्तु कहाँ स्थित है, इसके बारे में जानकारी। अंतरिक्ष में किसी वस्तु की स्थिति निर्धारित करने वाले मानों को कहा जाता है समन्वय करता है। किसी में समन्वय प्रणाली मूल, माप की इकाई, पैमाना, संदर्भ दिशा, या समन्वय अक्ष है। निर्देशांक प्रणालियों के उदाहरण कार्टेशियन निर्देशांक, ध्रुवीय समन्वय प्रणाली, शतरंज, भौगोलिक निर्देशांक हैं।
पाठ एन्कोडिंग
पाठ कोड के लिए काफी सरल है। ऐसा करने के लिए, यह किसी भी तरह से सभी अक्षरों, संख्याओं, विराम चिह्नों और पत्र में उपयोग किए गए अन्य प्रतीकों को फिर से कायम करने के लिए पर्याप्त है। एक चरित्र को संचय करने के लिए, एक आठ-बिट सेल का सबसे अधिक बार उपयोग किया जाता है - एक बाइट, कभी-कभी दो बाइट्स (उदाहरण के लिए चित्रलिपि)। आप एक बाइट को 256 विभिन्न संख्याएँ लिख सकते हैं, जिसका अर्थ है कि यह आपको 256 विभिन्न वर्णों को एनकोड करने की अनुमति देगा। प्रतीकों और उनके कोड का पत्राचार एक विशेष तालिका में निर्दिष्ट है। कोड हेक्साडेसिमल में लिखे गए हैं, आठ अंकों की संख्या को रिकॉर्ड करने के लिए, आपको केवल दो हेक्साडेसिमल अंकों की आवश्यकता है।
छवि कोडिंग
डिजिटल व्यक्तिगत कंप्यूटर संख्या के साथ अच्छी तरह से काम करते हैं, लेकिन यह नहीं जानते कि निरंतर मूल्यों को कैसे संभालना है। लेकिन मानव आंख को धोखा दिया जा सकता है: बड़ी संख्या में व्यक्तिगत छोटे विवरणों से बनी एक छवि को निरंतर माना जाता है। यदि हम ऊर्ध्वाधर और क्षैतिज रेखाओं के साथ तस्वीर को छोटे मोज़ेक वर्गों में तोड़ते हैं, तो हमें तथाकथित मिलता है रेखापुंज - वर्गों के दो आयामी सरणी। वर्गों खुद - रेखापुंज तत्व या पिक्सेल (चित्र "s तत्व) - चित्र के तत्व। प्रत्येक पिक्सेल का रंग एक संख्या द्वारा एन्कोड किया गया है।
एन्कोडिंग और डिकोडिंग। अन्य लोगों के साथ जानकारी का आदान-प्रदान करने के लिए, लोग प्राकृतिक भाषाओं का उपयोग करते हैं। प्राकृतिक भाषाओं के साथ, किसी भी क्षेत्र में उनके पेशेवर उपयोग के लिए औपचारिक भाषाओं को विकसित किया गया था। किसी भी भाषा का उपयोग करने वाली जानकारी के प्रतिनिधित्व को अक्सर कोडिंग कहा जाता है। कोड - सूचना की प्रस्तुति के लिए वर्णों (प्रतीकों) का एक सेट। कोड - सूचना (संचार) के हस्तांतरण, प्रसंस्करण और भंडारण के लिए पारंपरिक प्रतीकों (प्रतीकों) की प्रणाली। एन्कोडिंग एक कोड के रूप में जानकारी (एक संदेश) प्रस्तुत करने की प्रक्रिया है। एन्कोडिंग के लिए उपयोग किए जाने वाले वर्णों के पूरे सेट को एन्कोडिंग वर्णमाला कहा जाता है। उदाहरण के लिए, कंप्यूटर की मेमोरी में, द्विआधारी वर्णमाला का उपयोग करके किसी भी जानकारी को एन्कोड किया जाता है जिसमें केवल दो वर्ण होते हैं: 0 और 1। डिकोडिंग प्रक्रिया मूल चरित्र प्रणाली के रूप में कोड का रिवर्स रूपांतरण, अर्थात्। मूल संदेश प्राप्त करना। उदाहरण के लिए: मोर्स कोड से रूसी में एक लिखित पाठ में अनुवाद। एक व्यापक अर्थ में, कोडिंग संदेश की सामग्री को पुनर्प्राप्त करने की प्रक्रिया है। इस दृष्टिकोण के साथ, रूसी वर्णमाला का उपयोग करके पाठ लिखने की प्रक्रिया को एन्कोडिंग के रूप में माना जा सकता है, और इसका पढ़ना डिकोडिंग है।

सबसे लोकप्रिय और मांग वाले कनेक्टर प्रकारों में से एक बीएनसी कनेक्टर है। यह विभिन्न वीडियो में प्रयोग किया जाता है और ...

हम रूस में किसी भी स्थान पर वितरित करते हैं! भुगतान की सभी विधियाँ और कीमतें जब आप देख सकते हैं ...
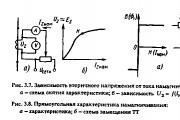
वर्तमान ट्रांसफॉर्मर और स्वीकार्य सचिव की पसंद, संरक्षित तत्व के लोड करंट को ध्यान में रखते हुए, इसका संचालन ...

"लगभग हर दिन, हमारे वैज्ञानिक, पृथ्वी की आंतों की खोज करते हैं, इसमें कोयले के सभी नए विशाल भंडार पाए जाते हैं, ...
Page 2 of 3 3. HV पर काम कर रहा है। 3.1.To दोषों की पहचान करें जो एक ओवरहेड ट्रांसमिशन लाइन और उनके समय पर होते हैं ...

प्रारंभिक क्षण: दो छात्र सामग्री पर रिपोर्ट तैयार करते हैं (3.4 (अतीत में उन्होंने कैसे जानकारी पारित की) और .53.5 ...

साधारण बिजली की लाइनें क्या हो सकती हैं? पावर ट्रांसमिशन टॉवर - सबसे आम इंजीनियरिंग में से एक ...
सोप - सोप, एन। 1. किसी भी तरल में डूबा हुआ या डूबा हुआ और नरम, कुछ भी; विशेष रूप से, कुछ डूबा हुआ ...

एक मल्टीफ़ेज़ रिसीवर और आमतौर पर मल्टीफ़ेज़ सर्किट को सममित कहा जाता है यदि उनके पास जटिल प्रतिरोध होते हैं ...

12/15/2015 Sberbank में बिजली के लिए भुगतान करना ऑनलाइन बैंकिंग का उपयोग करने का सबसे आसान तरीका है। शुरुआत के लिए ...
Microsoft Excel द्वारा प्रदान की जाने वाली कई विशेषताओं में से, रेखा ग्राफ़ सुविधा विशेष रूप से उपयोगी है ...।

ज्ञान आधार में अपना अच्छा काम भेजें सरल है। छात्रों के नीचे दिए गए फ़ॉर्म का उपयोग करें ...

एलईडी फाइटोलैम्प - अंकुरित पौधों को उजागर करने का सबसे अच्छा विकल्प। यहां आपको मिलेंगे टिप्स ...
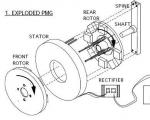
भेजा गया: भाग 1. स्थायी पर एक क्लासिक कम गति जनरेटर के निर्माण पर विस्तार से विचार किया ...

बिजली मीटर "मरकरी - 201" वर्तमान में हमारे देश में सबसे लोकप्रिय है ...

कोड टेबल book 13 एक दिलचस्प कहानी का हवाला हां "आई। पेरेलमैन" ने अपनी पुस्तक "मनोरंजक अंकगणित" में दिया। में ...