Для вкусных пельменей вам понадобится
Приготовление индюшачьего шашлыка: Филе промойте, обсушите, нарежьте поперёк волокон крупными кусками.Луковицу очистите,...
«Знаковые системы кодирование информации» - Вкусовые. Двоичная знаковая система. Каковы должны быть свойства информации, представленные в форме знаний? Звонок на урок. Каковы должны быть свойства информации, представленные средствами массовой информации? Каковы должны быть свойства информации, представленной в форме сообщений? Тема урока. Повторение.
Количество нейронов было довольно неоднородным, для некоторых нейронов - временная кодированная информация пренебрежимо мала, тогда как для других она была почти равна таковой, которая содержалась в подсчете импульсов. Фактически, количество импульсов в этом одиночном разряде содержит большую часть информации, доступной во всех 320 мс ответа, однако временно закодированная информация, как внутри этого окна, так и в остальной части ответа, является статистически значимой. мы преобразуем информацию в это временное окно в скорость передачи, деля ее по ширине окна, получаем максимальные частоты до 30 бит в секунду.
«Научно-техническая информация» - Консультационно-внедренческая фирма в области международной стандартизации и сертификации «ИНТЕРСТАНДАРТ» - http://www.interstandard.ru/. Государственная система научной и технической информации (ГСНТИ). На английском языке выходят сборники рефератов по 10 тематическим сериям. ИНИОН РАН издает: АНАЛИТИЧЕСКИЕ ОБЗОРЫ.
Выполняя вычисления для информации, с ответом, представленным в первый раз, путем подсчета импульсов в окне, центрированном на первом пике, и во второй раз счетчиками в паре окна, ориентированные на два пика, вы можете определить, передал ли второй пик новую информацию или просто повторил сообщение имо. Кьяр и соавторы сосредоточили внимание на проблеме содержания этих нейронных сообщений. Эти авторы выполнили расчеты, которые мы описали для подмножества стимулов в наборе Уолша. способ передачи информации с пространственными характеристиками различных наборов, они могли бы дать систематическое описание пространственных характеристик, по которым эти нейроны передают информацию.
«Число и кодирование информации» - Азбука Морзе. Компьютер Клавиатура Таблица График. Графический. - С помощью рисунков или значков. Команды 1 2. Также существует память отдельного человека и память человечества. Подготовительный этап. Дсбхйл. Текст. (С указанием кода населённого пункта). Цифра. Убвмйчб. Как человек хранит информацию?
Нижеследующие наборы были выбраны следующим образом. В полном наборе стимулов Уолша рассмотрим тот, который состоит из четырех смежных квадратов плюс перевернутых корреспондентов, такого набора, который обладает структурными пространственными характеристиками в обоих направлениях по характерному масштабу длины.
Если обнаружены нейронные ответы, чтобы передать значимую информацию на этом множестве можно думать о нейроне как детекторе признаков в этом масштабе. У конкретного нейрона может не быть достаточного разрешения, чтобы реагировать по-разному на образцы, которые смежны с пространством Уолша. Однако это может произойти, если подмножество паттернов, для которых была рассчитана первая передача, имеет пространственные характеристики на более дифференцированных ступенях, поэтому Кьяр и коллеги выполнили те же вычисления для наборов стимулов, для которых разность индексов Уолша также было 2 или 3 в горизонтальном или вертикальном направлении или в обоих.
«Кодирование звуковой информации» - Опорные термины по теме «Двоичное кодирование звука». Звуковая карта. Некоторые значения уровней шума. Измеряется в Па (Паскалях). Из-за широкого диапазона амплитуд чаще используется логарифмическая шкала децибелов (дБ): Измеряется в Гц. 1Гц = 1 колебание/сек Человек воспринимает звуки в диапазоне от 16 Гц до 20 кГц.
Найденные кривые уровня были неоднородными и демонстрировали различные типы структур. В интерпретации в терминах характеристик детектора, как правило, эти клетки показывают различные пространственные характеристики при различной аппроксимации лестницы. Наиболее распространенные типами структур, наблюдаемых были гребнями и плато, которые вытянуты вдоль направления в пространстве Уолша. Для сравнения, Чувствительность информации, передаваемой относительно перпендикулярных смещений к гребню, указывает, согласно найденному Рубелем и Визелем, что эти нейроны имеют тенденцию избирательно относиться к ориентации объектов в поле зрения. С другой стороны, относительная «сладость»хребта указывает на «нечувствительность к пространственной модуляции в этом направлении».
«Кодирование информации» - Азбука Морзе. Длина кода всех символов одинаковая и равна пяти. Методами шифрования занимается наука под названием криптография. Декодирование – преобразование данных из двоичного кода в форму, понятную человеку. Закодируйте сообщение «информатика» с помощью кода Морзе. Используя же алфавит арабской десятичной системы счисления, пишем «35».
Во многих из описанных нами результатов ясно, что в представлениях, в которых информация была отфильтрована из ответов, и в тех, которые содержат, в принципе, всю информацию, было предоставлено больше информации. Это было бы не так, если бы ответы были бесшумными, но при наличии шума процедура перекрестной проверки фактически разрушала компоненты ответа, для которых сигнал преобладает в шуме. Поэтому мы не можем сказать, что в этих компонентах отсутствует передача информации; мы можем только сказать, что у нас недостаточно данных, чтобы определить, есть ли это.
С появлением технических средств хранения и передачи информации возникли новые идеи и приемы кодирования. Первым техническим средством передачи информации на расстояние стал телеграф, изобретенный в 1837 году американцем Сэмюэлем Морзе. Телеграфное сообщение - это последовательность электрических сигналов, передаваемая от одного телеграфного аппарата по проводам к другому телеграфному аппарату. Эти технические обстоятельства привели С.Морзе к идее использования всего двух видов сигналов - короткого и длинного - для кодирования сообщения, передаваемого по линиям телеграфной связи.
Къер и соавторы провели исследование проблемы, ограниченное несколькими нейронами, для которых они имели наибольшее количество тестов, выполняли вычисления по подсистемам своих данных. Для меньших подмножеств трудно извлечь сигнал из шума, и информация, передаваемая, следовательно, меньше. Информация, извлеченная из основного компонента ответа, достигает предельного значения для размеров набора данных, превышающего примерно 10 повторных тестов на стимуляция, но с 5 компонентами насыщение не проявляется даже при 32 повторных тестах на стимул.
Сэмюэль Финли Бриз Морзе (1791–1872), США
Такой способ кодирования получил название азбуки Морзе. В ней каждая буква алфавита кодируется последовательностью коротких сигналов (точек) и длинных сигналов (тире). Буквы отделяются друг от друга паузами - отсутствием сигналов.
Самым знаменитым телеграфным сообщением является сигнал бедствия “SOS” (S aveO ur S ouls - спасите наши души). Вот как он выглядит в коде азбуки Морзе, применяемом к английскому алфавиту:
Более систематический анализ был недавно проведен Голомбом и сотрудниками по искусственным, но реалистичным данным. Используемые последовательности импульсов были получены из шаблона на основе пространственно-временных рекомпрессированных полей, измеренных для бокового гениального ядра. Можно было генерировать множества произвольно больших данных и вычислять переданную информацию для основных компонентов ответа до третьего основного компонента с точностью более 0, 01 бит, используя простое подразделение с интервалом 106 тестов.
Расчет на основе использования сети, как и для реальных данных, и сравнение результата с «почти» точным. Результаты показали, что количество тестов стимуляции, необходимых для оценки хорошей передаваемой информации, с использованием расчета на основе нейронной сети, примерно равно размеру набора стимулов. Когда метод ошибочен, это неизбежно связано с недооценкой информации. Это является следствием консервативного характера стратегии перекрестной проверки: эта стратегия гарантирует, что шум не может быть обменен с систематической структурой. полученных с помощью процедуры разбиения на более сложные классы, с использованием одинаково заполненных классов и соответствующей коррекции для конечного размера выборки.
–––
Три точки (буква S), три тире (буква О), три точки (буква S). Две паузы отделяют буквы друг от друга.
На рисунке показана азбука Морзе применительно к русскому алфавиту. Специальных знаков препинания не было. Их записывали словами: “тчк” - точка, “зпт” - запятая и т.п.
Характерной особенностью азбуки Морзе является переменная длина кода разных букв , поэтому код Морзе называют неравномерным кодом . Буквы, которые встречаются в тексте чаще, имеют более короткий код, чем редкие буквы. Например, код буквы “Е” - одна точка, а код твердого знака состоит из шести знаков. Это сделано для того, чтобы сократить длину всего сообщения. Но из-за переменной длины кода букв возникает проблема отделения букв друг от друга в тексте. Поэтому приходится для разделения использовать паузу (пропуск). Следовательно, телеграфный алфавит Морзе является троичным, т.к. в нем используется три знака: точка, тире, пропуск.
Этот метод не использует декодирование; это следует за уравнением, вычисляя безусловную энтропию и ответ условного ответа и вычитая второе из первого. Измерения на одиночных нейронах - это только начало изучения системы, которая, в конце концов, представляет собой сеть из миллиардов взаимодействующих единиц. В этом поле мы определяем смежные две ячейки, которые регистрируются одним и тем же электродом; два типа импульсов различаются по различным формам, которые имеют временные масштабы ниже миллисекунды.
Используемые шаблоны стимуляции включали в себя некоторые аналогичные бар-ориентированным, в дополнение к набору Уолша. В качественном отношении существует три типа кода, которые мы могли бы наблюдать в паре нейронов. Первый - избыточный код, в котором два нейрона отправляют одно и то же сообщение; только их шумы различны. Это код, который естественно ожидать, если вы начнете с гипотезы о том, что нейроны подвержены внутреннему воздействию шума, мультиплексирование сигнала используется для преодоления шума, вторая возможность - независимого кода, если два нейрона отправляют существенно разные сообщения.

Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце XIX века. В нем использовалось всего два разных вида сигналов. Не важно, как их назвать: точка и тире, плюс и минус, ноль и единица. Это два отличающихся друг от друга электрических сигнала. Длина кода всех символов одинаковая и равна пяти. В таком случае не возникает проблемы отделения букв друг от друга: каждая пятерка сигналов - это знак текста. Поэтому пропуск не нужен.
Это то, чего мы ожидаем от принципа эффективного представления, если внутренний шум низкий. Наконец, два нейрона могут передавать сообщение, которое невозможно извлечь из любого из них отдельно, то есть другой код может быть описан с точки зрения теории информации, учитывая информацию, переданную каждым нейроном отдельно, и информацию, переданную нейронами. два вместе. Что касается сети декодирования, которую мы описали, это означает, что расчет выполнен к использованию сети, где некоторые входы представляют собой ответ нейрона, в то время как другие входы представляют собой ответ другого.

Жан Морис Эмиль Бодо (1845–1903), Франция
Код Бодо - это первый в истории техники способ двоичного кодирования информации . Благодаря этой идее удалось создать буквопечатающий телеграфный аппарат, имеющий вид пишущей машинки. Нажатие на клавишу с определенной буквой вырабатывает соответствующий пятиимпульсный сигнал, который передается по линии связи. Принимающий аппарат под воздействием этого сигнала печатает ту же букву на бумажной ленте.
Конечно, возможны и промежуточные случаи. Основной результат состоит в том, что код находится в хорошем приближении к независимому коду. Среднее по клеточной популяции отношения. Другими слова, 20% от общей совместной информации совместно. Исследования в других частях зрительной системы, а также другие животные, по крайней мере, качественно согласуются с гипотезой, что этот уровень независимости характерен корой. Эти результаты свидетельствуют о том, что кратковременные нейроны не являются источником чрезмерного шума, и, следовательно, система использует широкую полосу, которая обеспечивается наличием многих из них.
В современных компьютерах для кодирования текстов также применяется равномерный двоичный код (см. “Системы кодирования текста” 2).
Тема кодирования информации может быть представлена в учебной программе на всех этапах изучения информатики в школе.
В пропедевтическом курсе ученикам чаще предлагаются задачи, не связанные с компьютерным кодированием данных и носящие, в некотором смысле, игровую форму. Например, на основании кодовой таблицы азбуки Морзе можно предлагать как задачи кодирования (закодировать русский текст с помощью азбуки Морзе), так и декодирования (расшифровать текст, закодированный с помощью азбуки Морзе).
Изучение простейших животных, как быть в одном уровне нейронов, может обеспечить возможность для более полного описания и систематических специальных примеров кодирования для более нейронов. Эти авторы обнаружили, что положения и амплитуды нейронных восприимчивых полей в зависимости от угла направления ветра являются почти оптимальными для максимизации передачи этой информации. Кроме того, в других контекстах приводятся ориентировочные результаты использования избыточного или совместного кода. В моторной коре хорошо известно, что взвешенные суммы частот излучения направленных нейронов предсказывают движение с точностью, то есть кодирование основанный на количестве импульсов.
Выполнение таких заданий можно интерпретировать как работу шифровальщика, предлагая различные несложные ключи шифрования. Например, буквенно-цифровой, заменяя каждую букву ее порядковым номером в алфавите. Кроме того, для полноценного кодирования текста в алфавит следует внести знаки препинания и другие символы. Предложите ученикам придумать способ для отличия строчных букв от прописных.
В визуальной системе есть доказательства такого кодирования особенностей фасада в коре 1Т. Примером совместного кодирования является синхронизация колебательных реакций нейронов, когда их восприимчивые поля лежат внутри одного и того же объекта в поле зрения. Объектами в этих экспериментах являются области, которые содержат диаграммы интенсивности движения, модулированные синусоидально. Если они соответствующим образом скорректированы в ориентации, пространственной частоте и скорости перемещения, эти закономерности могут вызывать сильные колебательные реакции от зрительных кортикальных клеток, а фазы этих ответов не фиксируются с помощью модуляции стимуляции.
При выполнении таких заданий следует обратить внимание учеников на то, что необходим разделительный символ - пробел, поскольку код оказываетсянеравномерным : какие-то буквы шифруются одной цифрой, какие-то - двумя.
Предложите ученикам подумать о том, как можно обойтись без разделения букв в коде. Эти размышления должны привести к идее равномерного кода, в котором каждый символ кодируется двумя десятичными цифрами: А - 01, Б - 02 и т.д.
Обнаружено, что фазы колебаний различных нейронов то же самое, если их целевые поля попадают в один и тот же объект, но они не попадают на разные объекты. Ответ любой ячейки кодирует только тип объекта. Он не кодирует ничего о размере, форме и краях объекта. Можно представить себе, что есть другие ячейки, которые делают это, но комбинаторная задача огромна: должны быть нейроны для всех разных фигур и положений, но это не было нейрон не был идентифицирован этого типа. Кажется, что сегментация визуальной сцены в объектах закодирована так, как фиксируется фаза колебаний.
Подборки задач на кодирование и шифрование информации имеются в ряде учебных пособий для школы .
В базовом курсе информатики для основной школы тема кодирования в большей степени связывается с темой представления в компьютере различных типов данных: чисел, текстов, изображения, звука (см. “Информационные технологии ” 2).
Вы не знаете, насколько этот механизм кодирования является общим. В экспериментах со стационарными «вспышечными» раздражителями, такими как Ричмонд и Оптикан, мы описали, никаких колебаний не наблюдалось; вероятно, в этом случае этот конкретный механизм недоступен. Даже в тех случаях, когда возникают колебания, мы не знаем, являются ли они важными для механизма кодирования или являются лишь второстепенным фактором.
Случай синхронизации в отсутствие колебаний наблюдался недавно в слуховой коре обезьяны. Было обнаружено, что степень синхронизации в испускании различных нейронов сигнализирует о наличии стимула, даже когда их частоты излучения не передают никакой информации. Эффект слабый для одной пары нейронов, но он может получить значимую информацию из степени синхронизации более крупных популяций. Поэтому система использует кодирование на основе количества импульсов, но переменная, добавляемая к нейронам, представляет собой степень корреляции импульсов вместо частоты излучения.
В старших классах в содержании общеобразовательного или элективного курса могут быть подробнее затронуты вопросы, связанные с теорией кодирования, разработанной К.Шенноном в рамках теории информации. Здесь существует целый ряд интересных задач, понимание которых требует повышенного уровня математической и программистской подготовки учащихся. Это проблемы экономного кодирования, универсального алгоритма кодирования, кодирования с исправлением ошибок. Подробно многие из этих вопросов раскрываются в учебном пособии “Математические основы информатики” .
Обработка информации
Обработка информации - процесс планомерного изменения содержания или формы представления информации .
Обработка информации производится в соответствии с определенными правилами некоторым субъектом или объектом (например, человеком или автоматическим устройством). Будем его называть исполнителем обработки информации .
Исполнитель обработки, взаимодействуя с внешней средой, получает из нее входную информацию , которая подвергается обработке. Результатом обработки являетсявыходная информация , передаваемая внешней среде. Таким образом, внешняя среда выступает в качестве источника входной информации и потребителя выходной информации.
Обработка информации происходит по определенным правилам, известным исполнителю. Правила обработки, представляющие собой описание последовательности отдельных шагов обработки, называются алгоритмом обработки информации.
Исполнитель обработки должен иметь в своем составе обрабатывающий блок, который назовем процессором, и блок памяти, в котором сохраняются как обрабатываемая информация, так и правила обработки (алгоритм). Все сказанное схематически представлено на рисунке.
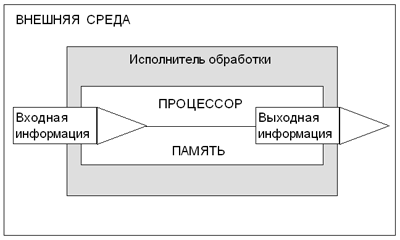
Схема обработки информации
Пример. Ученик, решая задачу на уроке, осуществляет обработку информации. Внешней средой для него является обстановка урока. Входной информацией - условие задачи, которое сообщает учитель, ведущий урок. Ученик запоминает условие задачи. Для облегчения запоминания он может использовать записи в тетрадь - внешнюю память. Из объяснения учителя он узнал (запомнил) способ решения задачи. Процессор - это мыслительный аппарат ученика, применяя который для решения задачи, он получает ответ - выходную информацию.
Схема, представленная на рисунке, - это общая схема обработки информации, не зависящая от того, кто (или что) является исполнителем обработки: живой организм или техническая система. Именно такая схема реализована техническими средствами в компьютере. Поэтому можно сказать, что компьютер является технической моделью “живой” системы обработки информации. В его состав входят все основные компоненты системы обработки: процессор, память, устройства ввода, устройства вывода (см. “Устройство компьютера” 2).
Входная информация, представленная в символьной форме (знаки, буквы, цифры, сигналы), называется входными данными . В результате обработки исполнителем получаются выходные данные . Входные и выходные данные могут представлять собой множество величин - отдельных элементов данных. Если обработка заключается в математических вычислениях, то входные и выходные данные - это множества чисел. На следующем рисунке X : {x 1, x 2, …, xn } обозначает множество входных данных, а Y : {y 1, y 2, …, ym } - множество выходных данных:

Схема обработки данных
Обработка заключается в преобразовании множества X в множество Y :
P (X ) Y
Здесь Р обозначает правила обработки, которыми пользуется исполнитель. Если исполнителем обработки информации является человек, то правила обработки, по которым он действует, не всегда формальны и однозначны. Человек часто действует творчески, не формально. Даже одинаковые математические задачи он может решать разными способами. Работа журналиста, ученого, переводчика и других специалистов - это творческая работа с информацией, которая выполняется ими не по формальным правилам.
Для обозначения формализованных правил, определяющих последовательность шагов обработки информации, в информатике используется понятие алгоритма (см. “Алгоритм” 2). С понятием алгоритма в математике ассоциируется известный способ вычисления наибольшего общего делителя (НОД) двух натуральных чисел, который называют алгоритм Евклида. В словесной форме его можно описать так:
1. Если два числа равны между собой, то за НОД принять их общее значение, иначе перейти к выполнению пункта 2.
2. Если числа разные, то большее из них заменить на разность большего и меньшего из чисел. Вернуться к выполнению пункта 1.
Здесь входными данными являются два натуральных числа - х 1 и х 2. Результат Y - их наибольший общий делитель. Правило (Р ) есть алгоритм Евклида:
Алгоритм Евклида (х 1, х 2) Y
Такой формализованный алгоритм легко запрограммировать для современного компьютера. Компьютер является универсальным исполнителем обработки данных. Формализованный алгоритм обработки представляется в виде программы, размещаемой в памяти компьютера. Для компьютера правила обработки (Р ) - это программа.
Объясняя тему “Обработка информации”, следует приводить примеры обработки, как связанные с получением новой информации, так и связанные с изменением формы представления информации.
Первый тип обработки : обработка, связанная с получением новой информации, нового содержания знаний. К этому типу обработки относится решение математических задач. К этому же типу обработки информации относится решение различных задач путем применения логических рассуждений. Например, следователь по некоторому набору улик находит преступника; человек, анализируя сложившиеся обстоятельства, принимает решение о своих дальнейших действиях; ученый разгадывает тайну древних рукописей и т.п.
Второй тип обработки : обработка, связанная с изменением формы, но не изменяющая содержания. К этому типу обработки информации относится, например, перевод текста с одного языка на другой: изменяется форма, но должно сохраниться содержание. Важным видом обработки для информатики является кодирование.Кодирование - это преобразование информации в символьную форму, удобную для ее хранения, передачи, обработки (см. “Кодирование ” 2).
Структурирование данных также может быть отнесено ко второму типу обработки. Структурирование связано с внесением определенного порядка, определенной организации в хранилище информации. Расположение данных в алфавитном порядке, группировка по некоторым признакам классификации, использование табличного или графового представления - все это примеры структурирования.
Особым видом обработки информации является поиск . Задача поиска обычно формулируется так: имеется некоторое хранилище информации - информационный массив (телефонный справочник, словарь, расписание поездов и пр.), требуется найти в нем нужную информацию, удовлетворяющую определенным условиям поиска (телефон данной организации, перевод данного слова на английский язык, время отправления данного поезда). Алгоритм поиска зависит от способа организации информации. Если информация структурирована, то поиск осуществляется быстрее, его можно оптимизировать (см. “Поиск данных” 2).
В пропедевтическом курсе информатики популярны задачи “черного ящика”. Исполнитель обработки рассматривается как “черный ящик”, т.е. система, внутренняя организация и механизм работы которой нам не известен. Задача состоит в том, чтобы угадать правило обработки данных (Р), которое реализует исполнитель.
Пример 1.
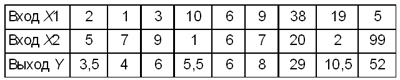
Исполнитель обработки вычисляет среднее значение входных величин: Y = (X 1 +X 2)/2
Пример 2.
На входе - слово на русском языке, на выходе - число гласных букв.
Наиболее глубокое освоение вопросов обработки информации происходит при изучении алгоритмов работы с величинами и программирования (в основной и старшей школе). Исполнителем обработки информации в таком случае является компьютер, а все возможности по обработке заложены в языке программирования.Программирование есть описание правил обработки входных данных с целью получения выходных данных .
Следует предлагать ученикам два типа задач:
Прямая задача: составить алгоритм (программу) для решения поставленной задачи;
Обратная задача: дан алгоритм, требуется определить результат его выполнения путем трассировки алгоритма.
При решении обратной задачи ученик ставит себя в положение исполнителя обработки, шаг за шагом выполняя алгоритм. Результаты выполнения на каждом шаге должны отражаться в трассировочной таблице.
Передача информации

Приготовление индюшачьего шашлыка: Филе промойте, обсушите, нарежьте поперёк волокон крупными кусками.Луковицу очистите,...

Домашняя выпечка - это нечто особенное, что придает дому особый аромат и атмосферу. Пожалуй, нет ничего вкуснее, чем...

Меланин является природным пигментом, придающим волосам, коже и радужной оболочке глаз человека их уникальный и...

Воинские звания в Иностранном легионе. Примечание: Галон - знак отличия во французской армии надеваемый на полевую...

Существуют интересные и необычные приметы про змей. Их стоит знать, ведь, кто знает, где можно столкнуться с этим...

Огромное влияние человека на природу и масштабные последствия его деятельности послужили основой для создания учения о...

Родился 11 мая 1946 г. В 1966 г. окончил Ярославское военное училище имени А.В. Хрулева и был назначен в СибВО...

Боевой путь 42-й гвардейской Евпаторийской Краснознаменной мотострелковой дивизии История 42-й гвардейской...

Человек как продукт биологической, социальной и культурной эволюции Появление человека Научное исследование...

§ 4. Где проходит граница города? Юридическая и фактическая граница города. Каждый город имеет юридическую...
Подпишись на канал Сонник! Подпишись на канал Сонник! Сонник - Зубы Видеть во сне собственные зубы, которые...

30 Дорогие читатели, свою кухню я не представляю без любимых приправ. Многое люблю, но самые для меня любимые...

Фото: Церковь Петра и Павла в Вырице Фото и описаниеЦерковь святых апостолов Петра и Павла в Вырице была...

Эта икона во время трагедии в 1995 году в г.Буденновске, когда чеченские боевики напали на беззащитный город,...

Домашняя выпечка - это нечто особенное, что придает дому особый аромат и атмосферу. Пожалуй, нет ничего...

Меланин является природным пигментом, придающим волосам, коже и радужной оболочке глаз человека их уникальный и...