Коллекция заблуждений: входящий в атмосферу космический корабль нагревается от трения об воздух Частицы воздуха при нагревании схема
КОНСПЕКТ УРОКА ОКРУЖАЮЩЕГО МИРА ДЛЯ 3 КЛАССА. УМК «Школа России» Тема: Воздух и его охрана. Цель урока:...
Основная операция, производимая над отдельными символами текста - сравнение символов.
При сравнении символов наиболее важными аспектами являются уникальность кода для каждого символа и длина этого кода, а сам выбор принципа кодирования практически не имеет значения.
Для кодирования текстов используются различные таблицы перекодировки. Важно, чтобы при кодировании и декодировании одного и того же текста использовалась одна и та же таблица.
Поэтому на первом этапе расширение 8-битного кода близко. Существует ряд назначений, которые ориентированы на потребности конкретных языков. Опять же, существует ряд контрольных знаков, включая небьющееся пространство и мягкую дефис. Так как каждый символ теперь потребует три байта вместо обычно одного байта, символы Юникода искусно закодированы.
Ниже мы ограничимся объяснением этого кодирования. В этом случае происходят 1, 2 - и 3-байтовые значения. В общем случае возможно даже 4 байта. Таким образом, тексты, написанные на западном языке, можно читать в значительной степени независимо от фактического кодирования. Кроме того, большинство встречающихся символов кодируются для экономии места.
Таблица перекодировки - таблица, содержащая упорядоченный некоторым образом перечень кодируемых символов, в соответствии с которой происходит преобразование символа в его двоичный код и обратно.
Наиболее популярные таблицы перекодировки: ДКОИ-8, ASCII, CP1251, Unicode.
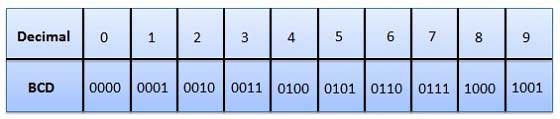
Исторически сложилось, что в качестве длины кода для кодирования символов было выбрано 8 бит или 1 байт. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Если ведущий бит равен 1, то это многобайтовый код. Одиннадцать релевантных байтов распределены по двум байтам, как показано в следующем примере. Примеры двухбайтовых кодов можно увидеть во второй и третьей таблицах кодов, изображенных ниже. Было изобретено множество других кодов, таких как Эмиль Бодо.
Телефонные линии способствовали развитию телепринтеров, устройств, которые могли кодировать и декодировать символы в коде Бодо. Символы были закодированы на 5 бит, поэтому было всего 32 символа. Он позволяет кодировать символы до 7 и продолжается до 8 бит, поэтому он имеет 256 возможных символов.
Различных комбинаций из 0 и 1 при длине кода 8 бит может быть 28 = 256, поэтому с помощью одной таблицы перекодировки можно закодировать не более 256 символов. При длине кода в 2 байта (16 бит) можно закодировать 65536 символов.
В настоящее время большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др.
Коды от 0 до 31 не являются символами. Они называются управляющими символами, потому что они позволяют им выполнять определенные действия, такие как возврат каретки для разрыва строки и аудиосигнала. Коды с 65 по 90 обозначают прописные буквы. Коды с 97 по 122 обозначают строчные буквы.
Для этого кода значения от 0 до 255 представляют собой прописные и строчные буквы, цифры, знаки препинания и другие символы. Его можно было бы обобщить как упрощение алфавитной и буквенно-цифровой систем. Эти коды входа и выхода позволяют нам переводить информацию или данные, которые мы понимаем с помощью устройств или компьютеров, на другой тип понимания, который машина может понять и обработать. С помощью этого кода очень легко преобразовать двоичный код в десятичный.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события):
Стандартный код США для обмена информацией. Этот более широкий набор кодов позволяет добавлять символы иностранных языков и различные графические символы. Ну, до сих пор недостаток этих буквенно-цифровых компьютерных систем, если у вас есть сомнения или идеи вообще, напишите комментарий.
При кодировании, когда числа, буквы или слова представлены определенной группой символов, говорят, что число, буква или слово кодируются. Группа символов называется кодом. Цифровые данные представляются, сохраняются и передаются как группа двоичных битов. Эта группа также называется двоичным кодом. Двоичный код представлен числом, а также буквенно-цифровой буквой.
К = 2I = 28 = 256,
т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой кодировке. Наглядно это можно представить в виде фрагмента объединенной таблицы кодировки символов.
Двоичные коды делают анализ и проектирование цифровых схем, если мы используем двоичные коды.
Табличные коды Невзвешенные коды Кодифицированный десятичный двоичный код Буквенно-цифровые коды Коды ошибок Коды ошибок. Табличные двоичные коды - это двоичные коды, подчиняющиеся принципу позиционного веса. Каждая позиция числа представляет определенный вес.
Одному и тому же двоичному коду ставится в соответствие различные символы.
Двоичный код Десятичный код КОИ8 СР1251 СР866 Мас ISO
11000010 194 б В - - Т
Впрочем, в большинстве случаев о перекодировке текстовых документов заботится на пользователь, а специальные программы - конверторы, которые встроены в приложения.
Начиная с 1997 г. последние версии Microsoft Windows&Office поддерживают новую кодировку Unicode, которая на каждый символ отводит по 2 байта, а, поэтому, можно закодировать не 256 символов, а 65536 различных символов.
В этом типе двоичных кодов вес позиции не присваивается им. Это невзвешенный код, используемый для выражения десятичных чисел. Коды избытка-3 получают следующим образом. 
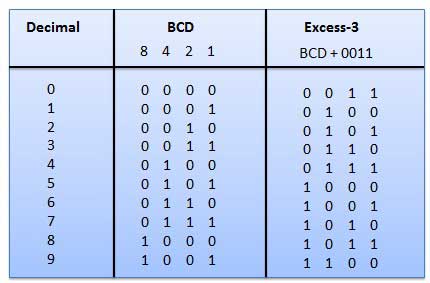
Это невзвешенный код, и это не арифметические коды. Это означает, что нет конкретных весов, назначенных для позиции бит. У этого есть очень особенная особенность, которая только немного изменится каждый раз, когда десятичное число увеличивается, как показано на рис. Поскольку изменяется только один бит за раз, серый код цвета называется кодом единицы расстояния.
Чтобы определить числовой код символа можно или воспользоваться кодовой таблицей, или, работая в текстовом редакторе Word 6.0 / 95. Для этого в меню нужно выбрать пункт "Вставка" - "Символ", после чего на экране появляется диалоговая панель Символ. В диалоговом окне появляется таблица символов для выбранного шрифта. Символы в этой таблице располагаются построчно, последовательно слева направо, начиная с символа Пробел (левый верхний угол) и, кончая, буквой "я" (правый нижний угол).
Серийный код не может использоваться для арифметической операции. 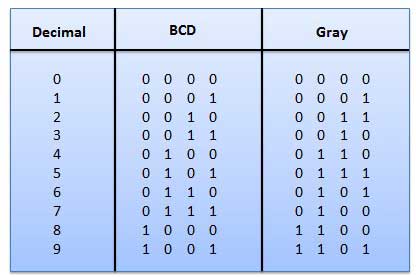
Кодер положения оси создает кодовое слово, которое представляет угловое положение оси. Серый код широко используется в системах измерения осей.
. В этом коде каждая десятичная цифра представлена двоичным числом из 4 бит.
Двоичная цифра или бит могут представлять только два символа, так как он имеет только два состояния 0 или 1. Но этого недостаточно для связи между двумя компьютерами, потому что нам не нужно больше символов для связи. Эти символы должны представлять 26 алфавитов с прописными и малыми буквами, цифры от 0 до 9, знаки препинания и другие символы.
Для определения числового кода символа в кодировке Windows (СР1251) нужно при помощи мыши или клавиш управления курсором выбрать нужный символ, затем щелкнуть по кнопке Клавиша. После этого на экране появляется диалоговая панель Настройка, в которой в нижнем левом углу содержится десятичный числовой код выбранного символа.
Три подхода к определению понятия "Количество информации"
Буквенно-цифровые коды - это коды, которые представляют числа и буквенные символы. В основном эти коды также представляют другие символы в качестве символа и различные инструкции, необходимые для передачи информации. Буквенно-цифровой код, который должен содержать не менее 10 цифр и 26 букв алфавита, всего 36 статей. Следующие три алфавитно-цифровых кода широко используются для представления данных.
Расширение кодированного десятичного двоичного кода. . Существуют методы двоичного кода для обнаружения и исправления данных во время передачи данных. Прежде чем начать изучение декодеров, что очень похоже на то, что мы видели ранее, необходимо вспомнить некоторые понятия о двоичных кодах.
А.П.Колмогоров
1 Комбинаторный подход
Пусть переменное x способно принимать значения, принадлежащие конечному множеству X, которое состоит из N элементов. Говорят, что энтропия переменного равна
Указывая определенное значение x=a переменного x, мы «снимаем» эту энтропию, сообщая инфомацию
Если переменные x1,x2,...,xk способны независимо пробегать множества, которые состоят соответственно из N1,N2,...,Nk элементов, то
Это последовательности двоичных чисел, упорядоченные каким-то образом. В цифровой электронике существует несколько кодов, есть ситуации, когда использование одного из них имеет преимущества перед другим. Он состоит из семи битов для кодирования различной различной информации, такой как число, буквы символов, сигналы управления передачей и т.д.
Кодеры и декодеры. Обычно нам нужно перейти от одного кода к другому. Он называется кодер комбинационной схемой, которая позволяет перейти от известного кода к неизвестному и декодировать схему, которая делает обратную. В отличие от того, что было видно до сих пор, обычно для ввода необходимо выполнить логический уровень 0. Таким образом, таблица истинности кодера будет даваться.
Для передачи количества информации I приходится употреблять
двоичных знаков. Например, число различных «слов», состоящих из k нулей и единиц и одной двойки, равно 2k(k + 1),
Поэтому количество информации в такого рода собщении равно
т.е. для «кодирования» такого рода слов в чистой двоичной системе требуется (всюду далее f≈g обозначает, что разность f-g ограничена, а f~g, что отношение f:g стремится к единице)
Он выполняет обратный процесс десятичного двоичного кодировщика, то есть выбирает один из выходов из двоичного числа. Таблица истинности двоично-десятичного дешифратора является инверсией приведенной выше. На карте Карно это будут неактуальные ситуации.
Следуя упрощениям с использованием карт Карно, получены следующие выражения; и из упрощенных выражений схема декодера. Действуя аналогично процессу, наблюдаемому в декодере с двоичным децималом, можно построить декодеры, которые переходят из любого кода в любой другой.
7-элементный дисплей позволяет записывать десятичные числа от 0 до 9 и некоторые символы, которые могут быть буквами или сигналами. На рисунке ниже представлен общий дисплейный блок с обычной номенклатурой идентификации сегмента в практических руководствах.
нулей и единиц. При изложении теории информации обычно не задерживаются надолго на таком комбинаторном подходе к делу. Но мне кажется существенным подчеркнуть его логическую независимость от каких бы то ни было вероятностных допущений. Пусть, например, нас занимает задача кодирования сообщений, записанных в алфавите, состоящем из s букв, причем известно, что частоты
Существует два основных типа светодиодных дисплеев: - Общий катод: сегменты светятся с 1. Общий анод: сегменты светятся с уровнем 0. На каждом номере светодиоды должны быть спроектированы так, чтобы принимать сформированный номер входа. Чтобы выполнить этот проект, необходимо проверить в каждом символе сегменты, которые должны быть освещены, и назначить уровень 1 в соответствии с соответствующей записью в двоичном коде.
На рисунке ниже показана строка, ее код ввода и уровни, применяемые к каждому сегменту. В упрощении мы будем использовать Карну Карно. В этом примере мы упростим только выходную переменную а, так как остальные придерживаются того же принципа. Помните, что для каждого выхода должна быть построена карта Карно.
появления отдельных букв в сообщении длины n удовлетворяют неравенству
Поэтому при передаче такого рода сообщений достаточно употребить примерно nh двоичных знаков.
Универсальный метод кодирования, который позволит передавать любое достаточно длинное сообщение в алфавите из s букв, употребляя не многим более чем nh двоичных знаков, не обязан быть чрезмерно сложным, в частности, не обязан начинаться с определения частот pr для всего сообщения. Чтобы понять это, достаточно заметить: разбивая сообщение S на m отрезков S1, S2,...,Sm, получим неравенство
Следует отметить, что схема может быть оптимизирована, поскольку выражения сегментов имеют несколько общих терминов, что приводит к использованию меньшего количества портов. 7-элементный дисплей также может записывать другие символы, которые часто используются в цифровых системах для представления других функций, а также для создания ключевых слов в программном обеспечении.
В телекоммуникациях и информатике кодированный набор символов представляет собой код, который связывает набор символов алфавита с численным представлением для каждого символа этой игры. Например, код Морзе является одним из первых кодированных наборов символов.
Впрочем, я не хочу входить здесь в детали этой специальной задачи. Мне важно лишь показать, что математическая проблематика, возникающая на почве чисто комбинаторного подхода к измерению количества информации, не ограничивается тривиальностями.
Вполне естественным является чисто комбинаторный подход к понятию «энтропии речи», если иметь в виду оценку «гибкости» речи - показателя разветвленности возможностей продолжения речи при данном словаре и данных правилах построения фраз. Для двоичного логарифма числа N русских печатных текстов, составленных из слов, включенных в «Словарь русского языка С. И. Ожегова и подчиненных лишь требованию «грамматической правильности» длины n, выраженной в «числе знаков» (включая пробелы), М. Ратнер и Н. Светлова получили оценку
Мы все когда-то получили странное электронное письмо или прочитали веб-страницу следующим образом. Хотя это все менее и менее распространено, иногда появляются фразы, в которых некоторые символы заменяются другими, которые не имеют ничего общего и которые препятствуют чтению и пониманию текста. Это проблема кодирования и декодирования. Человек, пишущий текст, использует другой стандарт, чем тот, который используется человеком, читающим его!
Глобализация культурных и экономических обменов подчеркнула, что европейские языки сосуществуют со многими другими языками со специфическими алфавитами или даже без алфавитов. Поэтому широкое использование Интернета в мире требует гораздо большего числа символов, которые необходимо учитывать. Каждому персонажу присваивается имя, нормативная позиция и краткое описание, которое будет одинаковым независимо от используемой компьютерной платформы или программного обеспечения. Активность - кодирование и Интернет.
Это значительно больше, чем оценки сверху для «энтропии литературных текстов», получаемые при помощи различных методов «угадывания продолжений». Такое расхождение вполне естественно, так как литературные тексты подчинены не только требованию «грамматической правильности.
Труднее оценить комбинаторную энтропию текстов, подчиненных определенным содержательным ограничениям. Представляло бы, напри- мер, интерес оценить энтропию русских текстов, могущих рассматриваться как достаточно точные по содержанию переводы заданного иноязычного текста. Только наличие такой «остаточной энтропии» делает возможным стихотворные переводы, где «затраты энтропии» на следование избранному метру и характеру рифмовки могут быть до- вольно точно подсчитаны. Можно показать, что классический четырехстопный рифмованный ямб с некоторыми естественными ограничениями на частоту «переносов» и т. п. требует допущения свободы обращения со словесным материалом, характеризуемой «остаточной энтропией» порядка 0,4 (при указанном выше условном способе измерения длины текста по «числу знаков, включая про- белы»). Если учесть, с другой стороны, что стилистические ограничения жанра, вероятно, снижа- ют приведенную выше оценку «полной» энтропии с 1,9 до не более чем 1,1-1,2, то ситуация становится примечательной как в случае перевода, так и в случае оригинального поэтического творчества.
Откройте интернет-браузер. Давайте изменим это и выберите Центральную Европу. Появляются маленькие, неприятные символы. Как только вы измените параметр привода, появится несовместимость. Используя веб-браузер и перейдя в «Вид», «Источник», мы получим следующее.
Маяк Давайте рассмотрим типичный пример света, испускаемого морским маяком: он является первым неделимым, его производственная стоимость не зависит от количества пользователей, обладает свойством неконкурентоспособности, она также не исключается, поскольку невозможно исключить пользователя из использования, даже если последнее не способствует его финансированию.
Да простят мне утилитарно настроенные читатели этот пример. В оправдание замечу, что более широкая проблема оценки количеств информации, с которыми имеет дело творческая человеческая деятельность, имеет очень большое значение.
Посмотрим теперь, в какой мере чисто комбинаторный подход позволяет оценить «количество информации», содержащееся в переменном x относительно связанного с ним переменного y. Связь между переменными x и y, пробегающими соответсвенно множества X и Y , заключается в том, что не все пары x, y, принадлежащие прямому произведению X.Y , являются «возможными». По множеству возможных пар U определяются при любом aX множества Ya тех y, для которых
Естественно определить условную энтропию равенством
(где N(Yx) - число элементов в множестве Yx), а информацию в x относительно y−формулой
Например, в случае, изображенном в таблице имеем
Понятно, что H(y|x) и I(x:y) являются функциями от x (в то время как y входит в их обозначение в виде «связанного переменного»).
Без труда вводится в чисто комбинаторной концепции представление о «количестве информации, необходимом для указания объекта x при заданных требованиях к точности указания». (См. по этому поводу обширную литературу об «ε-энтропии» множеств в метрических пространствах.)
Очевидно,
2 Вероятностный подход
Возможности дальнейшего развития теории информации на основе определений (5) и (6) остались в тени ввиду того, что придание переменым x и y характера «случайных переменных», обладающих определенным совместным распределением вероятностей, позволяет получить значительно более богатую систему понятий и соотношений. В параллель к введенным в §1 величинам имеем здесь
По-прежнему HW(y|x) и IW(x:y) являются функциями от x. Имеют место неравенства
переходящие в равенства при равномерности соответсвующих распределений (на X и Yx). Величины IW(x:y) и I(x:y) не связаны неравенством определенного знака. Как и в §1,
Но отличие заключается в том, что можно образовать математические ожидания MHW(y|x), MIW(x:y), а величина
характеризует «тесноту связи» между x и y симметричным образом.
Стоит, однако, отметить и возникновение в вероятностной концепции одного парадокса: величина I(x:y) при комбинаторном подходе всегда неотрицательна, как это и естественно при наивном представлении о «количестве информации», величина же IW(x:y) может быть и отрицательной. Подлинной мерой «количества информации» теперь становится лишь осредненная величина IW(x,y).
Вероятностный подход естествен в теории передачи по каналам связи «массовой» информации, состоящей из большого числа не связанных или слабо связанных между собой сообщений, подчиненных определенным вероятностным закономер- ностям. В такого рода вопросах практически безвредно и укоренившееся в прикладных работах смешение вероятностей и частот в пределах одного достаточно длинного временн.ого ряда (получающее строгое оправдание при гипотезе достаточно быстрого «перемешивания»). Практически можно считать, например, вопрос об «энтропии» потока поздравительных телеграмм и «пропускной способности» канала связи, требующегося для своевременной и неискаженной передачи, корректно поставленным в его вероятностной трактовке и при обычной замене вероятностей эмпирическими частотами. Если здесь и остается некоторая неудовлетворенность, то она связана с известной расплывчатостью наших концепций, относящихся к связям между математической теорией вероятностей и реальными «случайными явлениями вообще.
Но какой реальный смысл имеет, например, говорить о «количестве информации», содержащемся в тексте «Войны и мира»? Можно ли включить разумным образом этот роман в совокупность «возможных романов» да еще постулировать наличие в этой совокупности некоторого распределения вероятностей? Или следует считать отдельные сцены «Войны и мира» образующими случайную последовательность с достаточно быстро затухающими на расстоянии нескольких страниц «стохастическими связями?
По существу, не менее темным является и модное выражение «количество наследственной информации, необходимой, скажем, для воспроизведения особи вида кукушка. Опять в пределах принятой вероятностной концепции возможны два варианта. В первом варианте рассматривается совокупность «возможных видов» с неизвестно откуда берущимся распределением вероятностей на этой совокупности2(2Обращение к множеству видов, существующих или существовавших на Земле, даже при чисто комбинаторном подсчете дало бы совершенно неприемлемо малые оценки сверху (что-либо вроде <100 бит!).).
Во втором варианте характеристические свойства вида считаются набором слабо связанных между собой случайных переменных. В пользу второго варианта можно привести соображения, основанные на реальном механизме мутационной изменчивости. Но соображения эти иллюзорны, если считать, что в результате естественного отбора возникает система согласованных между собой характеристических признаков вида.
3 Алгоритмический подход
По существу, наиболее содержательным является представление о количестве информации «в чем-либо (x) и «о чем-либо» (y). Не случайно именно оно в вероятностной концепции получило обобщение на случай непрерывных переменных, для которых энтропия бесконечна, но в широком круге случаев конечно.
Реальные объекты, подлежащие нашему изучению, очень (неограниченно?) сложны, но связи между двумя реально существующими объектами исчерпываются при более простом схематизированном их описании. Если географическая карта дает нам значительную информацию об участке земной поверхности, то все же микроструктура бумаги и краски, нанесенной на бумагу, никакого отношения не имеет к микроструктуре изображенного участка земной поверхности.
Практически нас интересует чаще всего количество информации в индивидуальном объекте x относительно индивидуального объекта y. Правда, уже заранее ясно, что такая индивидуальная оценка количества информации может иметь разумное содержание лишь в случаях достаточно больших количеств информации. Не имеет, например, смысла спрашивать о количестве информации в последовательности цифр 0 1 1 0 относительно последовательности 1 1 0 0. Но если мы возьмем вполне конкретную таблицу случайных чисел обычного в статистической практике объема и выпишем для каждой ее цифры цифру единиц ее квадрата по схеме
то новая таблица будет содержать примерно
информации о первоначальной (n - число цифр в столбцах).
В соответсвии с только что сказанным предлагаемое далее определение величины IA(x:y) будет сохранять некоторую неопределенность. Разные равноценные варианты этого определения будут приводить к значениям, эквивалентным лишь в смысле IA1≈IA2, т.е.
где константа CA1A2 зависит от положенных в основу двух вариантов определения универсальных методов программирования A1 и A2.
Будем рассматривать «нумерованную область объектов», т.е. счетное множество X={x}, каждому элементу которого поставлена в соответствие в качестве «номера» n(x) конечная последовательность нулей и единиц, начинающаяся с единицы. Обозначим через l(x) длину последовательности n(x). Будем предполагать, что
1) соответствие между X и множеством D двоичных последовательностей описанного вида взаимно однозначно;
2) DX, функция n(x) на D общерекурсивна , причем для xD
где C - некоторая константа;
3) вместе с x и y в X входит упорядоченная пара (x,y), номер этой пары есть общерекурсивная функция номеров x и y и
где Cx зависит только от x.
Не все эти требования существенны, но они облегчают изложение. Конечный результат построения инвариантен по отношению к переходу к новой нумерации n"(x), обладающей теми же свойствами и выражающейся общерекурсивно через старую, и по отношению к включению системы X в более обширную систему X" (в предположении, что номера n" в расширенной системе для элементов первоначальной системы общерекурсивно выражаются через первоначальные номера n). При всех этих преобразованиях новые «сложности» и количества информации остаются эквивалентными первоначальным в смысле ≈
«Относительной сложностью» объекта y при заданном x будем считать минимальную длину l(p) программы p получения y из x. Сформулированное так определение зависит от «метода программирования. Метод программирования есть не что иное, как функция φ(p,x)=y, ставящая в соответсвие программе p и объекту x объект y.
В соответсвии с универсально признанными в современной математической логике взглядами следует считать функцию φ частично рекурсивной. Для любой такой функции полагаем
При этом функция υ=φ(u) от uX со значениями υX называется частично рекурсивной, если она порождается частично рекурсивной функцией преобразования номеров
Для понимания определения важно заметить что частично рекурсивные функции, вообще говоря, не являются всюду определенными. Не существует регулярного процесса для выяснения того, приведет применение программы p к объекту x к какому-либо результату или нет. Поэтому функция Kφ(y|x) не обязана быть эффективно вы числимой (общерекурсивной) даже в случае, когда она заведомо конечна при любых x и y.
Двоичное кодирование текстовой информации. Различные кодировки кириллицыю
Начиная с конца 60-х годов компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. / = 1 байт = 8 бит.
Если рассматривать символы как возможные события, то можно вычислить, какое количество различных символов можно закодировать:
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т. д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа преобразуется в его двоичный код. Пользователь нажимает на клавиатуре клавишу с символом - и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает одну ячейку.
В процессе вывода символа на экран компьютера производится обратный процесс - декодирование, т. е. преобразование кода символа в его изображение.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) обозначают не символы, а операции (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 - интернациональные и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т. е. в национальных кодировках одному и тому же коду отвечают различные символы. К сожалению, в настоящее время существует пять различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Мае, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
Каждая кодировка задается своей собственной кодовой таблицей. Одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
В последнее время появился новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, и потому с его помощью можно закодировать не 256 символов, аразличных символов.

КОНСПЕКТ УРОКА ОКРУЖАЮЩЕГО МИРА ДЛЯ 3 КЛАССА. УМК «Школа России» Тема: Воздух и его охрана. Цель урока:...

Краткое описание карты: На рисунке мы видим, как шестеро атакуют одного, но у него есть явное преимущество: он находится...

Презентация «Безопасная дорога - детям» Актуальность Необходимость обучения детей ПДД, так как дети часто являются...

Рыбы, не сближайтесь с людьми, которые постоянно осыпают вас комплиментами — возможно, они втираются в доверие и хотят...

Отвечает Мария Бунеева, Эксперт Немецкого детского онлайн-университета В европейской католической традиции заяц,...

← 1132 - 1471 Столица Киев Язык(и) Древнерусский Религия Православное христианство Население восточные славяне...

Если во сне Вы просыпали на пол крупу, то Вас ждут потери. Для беременной женщины такой сон может быть...

Суп картофельный вегетарианскийПpодукты: 700 г каpтофеля, 1,4 л воды, 40 г сливочного масла, 2 яйца, 100 г...

Современные понятия о красоте требуют от девушек серьезных усилий для достижения идеальной фигуры. Еще недавно...

Думаете над тем, что приготовить на завтрак или ужин? Обратите внимание на гречку. Эта каша сытная и очень...

Приготовление индюшачьего шашлыка: Филе промойте, обсушите, нарежьте поперёк волокон крупными кусками.Луковицу...

Домашняя выпечка - это нечто особенное, что придает дому особый аромат и атмосферу. Пожалуй, нет ничего...

Меланин является природным пигментом, придающим волосам, коже и радужной оболочке глаз человека их уникальный и...

Воинские звания в Иностранном легионе. Примечание: Галон - знак отличия во французской армии надеваемый на...

Краткое описание карты: На рисунке мы видим, как шестеро атакуют одного, но у него есть явное преимущество: он...

Презентация «Безопасная дорога - детям» Актуальность Необходимость обучения детей ПДД, так как дети часто...