गरमागरम लैंप के लिए डिमर्स को जोड़ने के उपकरण, प्रकार और आरेख
मानक स्विच का संचालन करते समय, आप केवल लैंप की अधिकतम चमक प्राप्त कर सकते हैं। लेकिन ऐसे हालात हैं ...
अब कई सूचना संपीड़न एल्गोरिदम हैं। उनमें से ज्यादातर व्यापक रूप से ज्ञात हैं, लेकिन कुछ बहुत प्रभावी हैं, लेकिन, कम-ज्ञात एल्गोरिदम। यह लेख अंकगणित कोडिंग विधि के बारे में बात करता है, जो कि एन्ट्रापी का सबसे अच्छा है, लेकिन फिर भी बहुत कम लोग इसके बारे में जानते हैं।
इससे पहले कि हम अंकगणित कोडिंग के बारे में बात करें, मुझे हफमैन एल्गोरिथ्म के बारे में कुछ शब्द कहना चाहिए। यह विधि तब प्रभावी होती है जब वर्णों की घटना की आवृत्ति 1/2 n (जहाँ n एक धनात्मक पूर्णांक होती है) के समानुपाती होती है। यह कथन स्पष्ट हो जाता है यदि हम याद करते हैं कि प्रत्येक वर्ण के लिए हफमैन कोड हमेशा बिट्स के पूर्णांक संख्या से मिलकर होते हैं। ऐसी स्थिति पर विचार करें जहां एक प्रतीक की उपस्थिति की आवृत्ति 0.2 है, फिर इस प्रतीक को एन्कोडिंग के लिए इष्टतम कोड होना चाहिए - 2 (0.2) = 2.3 बिट्स। यह स्पष्ट है कि हफमैन उपसर्ग कोड में इतनी लंबाई नहीं हो सकती है, अर्थात्। यह अंततः डेटा संपीड़न में गिरावट की ओर जाता है।
अंकगणित कोडिंग का उद्देश्य इस समस्या को हल करना है। मूल विचार कोड को अलग-अलग वर्णों को नहीं, बल्कि उनके अनुक्रमों को निर्दिष्ट करना है।
सबसे पहले, एल्गोरिथ्म में निहित विचार पर विचार करें, फिर एक छोटे व्यावहारिक उदाहरण पर विचार करें।
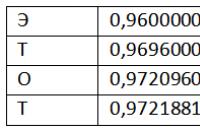
सभी एन्ट्रापी एल्गोरिदम के साथ, हमारे पास वर्णमाला के प्रत्येक वर्ण के उपयोग की आवृत्ति के बारे में जानकारी है। यह जानकारी प्रश्न में विधि के लिए स्रोत है। अब हम एक कार्य खंड की अवधारणा को पेश करते हैं। कार्यकर्ता को अर्ध-अंतराल * (hi-1 - li-1) कहा जाता है; );
ऊपर की आकृति में बड़ी ऊर्ध्वाधर पट्टी ऑपरेशन के दौरान प्राप्त अंतराल में एक मनमाना संख्या को इंगित करती है। अनुक्रम "कोव" के लिए, 4 वर्णों से मिलकर, ऐसी संख्या के लिए आप 0.341 ले सकते हैं। यदि मूल श्रेणी तालिका और श्रृंखला लंबाई ज्ञात हो, तो यह संख्या मूल श्रृंखला को पुनर्स्थापित करने के लिए पर्याप्त है।
चेन रिकवरी एल्गोरिदम के संचालन पर विचार करें। प्रत्येक अगले अंतराल पिछले एक में नेस्टेड है। इसका मतलब यह है कि यदि कोई संख्या 0.341 है, तो श्रृंखला में केवल "K" पहला वर्ण हो सकता है, क्योंकि केवल उसकी सीमा में यह संख्या शामिल है। अंतराल को "K" - * (hi-1 - li-1) के रूप में लिया जाता है; hi = hi-1 + b * (hi-1 - li-1); अगर (ली<= value) && (value < hi)) break; }; DataFile.WriteSymbol(cj); };
जहां मान स्ट्रीम से पढ़ी गई संख्या (अंश) है, और c आउटपुट स्ट्रीम के लिए लिखा गया अनपैक्ड वर्ण है। 256 वर्णों की वर्णमाला का उपयोग करते समय, आंतरिक लूप काफी लंबा चलता है, लेकिन इसे त्वरित किया जा सकता है। ध्यान दें कि कब से ![]() (श्रेणियों की उपरोक्त तालिका देखें), तब के लिए है, और जम्मू के साथ सख्ती से बढ़ने का क्रम है। यानी आंतरिक चक्र में संचालन की संख्या आधी हो सकती है, क्योंकि यह केवल एक अंतराल की सीमा की जांच करने के लिए पर्याप्त है। इसके अलावा, अगर हमारे पास कुछ प्रतीक हैं, तो, घटती संभावनाओं के क्रम में उन्हें सॉर्ट करते हुए, हम लूप पुनरावृत्तियों की संख्या को कम करते हैं और इस प्रकार, डिकम्प्रेसर के काम को गति देते हैं। उच्चतम संभावना वाले पात्रों को पहले जांचा जाएगा, उदाहरण के लिए, हमारे उदाहरण में, हम सबसे अधिक संभावना छह के दूसरे प्रतीक पर पहले से ही चक्र से बाहर निकलेंगे। यदि वर्णों की संख्या बड़ी है, तो वर्णों की खोज को गति देने के लिए अन्य प्रभावी तरीके हैं (उदाहरण के लिए, द्विआधारी खोज)।
(श्रेणियों की उपरोक्त तालिका देखें), तब के लिए है, और जम्मू के साथ सख्ती से बढ़ने का क्रम है। यानी आंतरिक चक्र में संचालन की संख्या आधी हो सकती है, क्योंकि यह केवल एक अंतराल की सीमा की जांच करने के लिए पर्याप्त है। इसके अलावा, अगर हमारे पास कुछ प्रतीक हैं, तो, घटती संभावनाओं के क्रम में उन्हें सॉर्ट करते हुए, हम लूप पुनरावृत्तियों की संख्या को कम करते हैं और इस प्रकार, डिकम्प्रेसर के काम को गति देते हैं। उच्चतम संभावना वाले पात्रों को पहले जांचा जाएगा, उदाहरण के लिए, हमारे उदाहरण में, हम सबसे अधिक संभावना छह के दूसरे प्रतीक पर पहले से ही चक्र से बाहर निकलेंगे। यदि वर्णों की संख्या बड़ी है, तो वर्णों की खोज को गति देने के लिए अन्य प्रभावी तरीके हैं (उदाहरण के लिए, द्विआधारी खोज)।
यद्यपि उपरोक्त एल्गोरिथ्म पूरी तरह कार्यात्मक है, बाइनरी अंशों के साथ काम करने वाले एल्गोरिदम की तुलना में यह धीरे-धीरे काम करेगा। बाइनरी अंश के रूप में दिया जाता है। इस प्रकार, संपीड़न के दौरान, हमें अंश तक अतिरिक्त वर्ण जोड़ने की आवश्यकता होती है जब तक कि परिणामी संख्या कोडित स्ट्रिंग के अनुरूप अंतराल में न गिर जाए। परिणामी संख्या पूरी तरह से कोडिंग स्ट्रिंग को एक समान डिकोडिंग एल्गोरिथ्म के साथ सेट करती है। रेखीय रूप से, एल्गोरिथ्म का एल्गोरिथ्म चित्र 1.4 में दिखाया गया है।
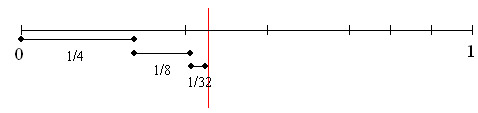
व्यायाम: "11" (संख्या) के बराबर एन्कोडेड श्रृंखला से 2 बिट्स के स्रोत कोड को पुनर्स्थापित करें ![]() ), उपरोक्त रेंज टेबल का उपयोग करते हुए, यदि आप जानते हैं कि पाठ की लंबाई 10 वर्ण है।
), उपरोक्त रेंज टेबल का उपयोग करते हुए, यदि आप जानते हैं कि पाठ की लंबाई 10 वर्ण है।
अंकगणित कोडिंग की एक दिलचस्प विशेषता व्यक्तिगत रूप से दृढ़ता से संपीड़ित करने की क्षमता है

मानक स्विच का संचालन करते समय, आप केवल लैंप की अधिकतम चमक प्राप्त कर सकते हैं। लेकिन ऐसे हालात हैं ...

एसी पावर सर्किट में धाराओं को मापने के लिए वर्तमान ट्रांसफार्मर का उपयोग किया जाता है। वे दोनों श्रृंखलाओं में लागू होते हैं ...

सबसे अच्छा ध्रुवीकृत धूप का चश्मा विभिन्न रूपों और कार्यों में उपलब्ध हैं, उच्च की सभी उपलब्धियों के साथ ...
वायरिंग की समस्याओं के दौरान, मरम्मत कार्य के दौरान और बाद में केबल को चालू करते समय - इन सभी मामलों में ...

ऐसी कई परिस्थितियां हैं जहां यह जानना उपयोगी होगा कि मल्टीमीटर के साथ प्रतिरोध को कैसे मापें और क्या कोई अंतर है कि कैसे ...
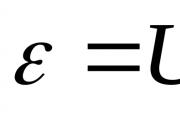
शिक्षा की स्थापना "स्मारक राज्य का संग्रह" विद्युत स्रोत विधि के इलेक्ट्रो-बढ़ते बिजली की निकासी ...

स्टेटर चरण घुमावदार में ओपन सर्किट। यदि दोनों चरण टूट गए हैं, तो जनरेटर बिल्कुल काम नहीं करेगा। यदि आप ...
व्लादिमीर Malafeev प्रमाणित व्यापार कोच। वह जानता है कि हर किसी के लिए इसे समझना बहुत मुश्किल है ...।
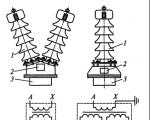
उद्देश्य के आधार पर, विभिन्न कनेक्शन आरेखों के साथ वोल्टेज ट्रांसफार्मर का उपयोग किया जा सकता है ...

हर कोई जानता है कि कारें जल्दी या बाद में टूट जाती हैं। लेकिन कभी-कभी एक मोटर चालक को इस तरह की समस्या का सामना करना पड़ता है ...
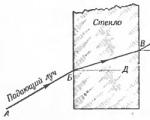
प्रकाश की एक किरण, एक पारदर्शी माध्यम से दूसरे में जा रही है, अपनी दिशा बदलती है, या, जैसा कि वे कहते हैं, ...

एक अतुल्यकालिक मोटर के प्रदर्शन को दक्षता की निर्भरता कहा जाता है yn, ...
संघीय शिक्षा के लिए एजेंसी GOU VPO "यूराल राज्य तकनीकी विश्वविद्यालय -...
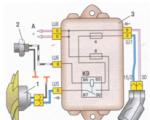
आज, प्रौद्योगिकी के इतनी तेजी से विकास के साथ, यह जानना बहुत महत्वपूर्ण है कि कार इलेक्ट्रिकल सर्किट कैसे पढ़ें। और नहीं ...
अब कई सूचना संपीड़न एल्गोरिदम हैं। उनमें से ज्यादातर व्यापक रूप से जाने जाते हैं, लेकिन वहाँ हैं ...
एक खाई में केबल बिछाने। बिछाने के प्रकार: भू-संबंधी सेवाएं। विद्युत उपकरण और नेटवर्क की स्थापना ...