Výpočet výkonu pre prúd a napätie
Ako viete, elektrické napätie by malo mať svoje vlastné opatrenie, ktoré na začiatku zodpovedá hodnote, ktorá ...
Hlavná operácia vykonaná na jednotlivých znakoch textu - porovnanie znakov.
Pri porovnávaní znakov sú najdôležitejšie aspekty jedinečnosť kódu pre každý znak a dĺžku tohto kódu a výber kódu je takmer irelevantný.
Na kódovanie textov pomocou rôznych prevodových tabuliek. Je dôležité, aby sa rovnaká tabuľka používala pri kódovaní a dekódovaní rovnakého textu.
Preto je v prvej fáze rozšírenie 8-bitového kódu blízko. Existuje množstvo úloh, ktoré sú prispôsobené potrebám špecifických jazykov. Opäť existuje niekoľko kontrolných značiek, vrátane nerozbitného miesta a mäkkého pomlčka. Pretože každá postava teraz vyžaduje tri bajty namiesto zvyčajne jedného bajtu, znaky Unicode sú umelecky zakódované.
Nižšie sa obmedzujeme na vysvetlenie tohto kódovania. V tomto prípade sa vyskytujú hodnoty 1, 2 a 3 bajty. Vo všeobecnosti je možné dokonca aj 4 bajty. Takže texty napísané v západnom jazyku možno čítať prevažne bez ohľadu na skutočné kódovanie. Navyše väčšina bežných znakov je zakódovaná, aby šetrila miesto.
Prekladová tabuľka je tabuľka obsahujúca nejakým spôsobom usporiadaný zoznam kódovaných znakov, podľa ktorého sa znak prevádza na binárny kód a naopak.
Najobľúbenejšie prevodové tabuľky: DKOI-8, ASCII, CP1251, Unicode.
Historicky bolo ako dĺžka kódu pre kódovanie znakov vybratá 8 bitov alebo 1 bajt. Preto najčastejšie jeden znak uložený v počítači zodpovedá jednému bajtu pamäte.
Ak je predný bit 1, potom je to viacbitový kód. Jedenásť relevantných bajtov je rozdelených dvoma bajtami, ako je uvedené v nasledujúcom príklade. Príklady dvojbajtových kódov možno vidieť v druhej a tretej kódovej tabuľke uvedenej nižšie. Mnohé ďalšie kódy boli vynájdené, ako napríklad Emile Bodo.
Telefónne linky prispeli k rozvoju teleprinterov, zariadení, ktoré by mohli zakódovať a dekódovať znaky v Bodovom kóde. Postavy boli zakódované v 5 bitoch, takže ich bolo iba 32 znakov. Umožňuje kódovať znaky až 7 a trvá až 8 bitov, takže má 256 možných znakov.
Rôzne kombinácie 0 a 1 s dĺžkou kódu 8 bitov môžu byť 28 = 256, takže pomocou jednej konverznej tabuľky nemôžete zakódovať viac ako 256 znakov. Pri dĺžke kódu 2 bajty (16 bitov) je možné zakódovať 65 536 znakov.
V súčasnosti väčšina používateľov používa počítač na spracovanie textových informácií, ktoré sa skladajú zo symbolov: písmená, čísla, interpunkčné znamienka atď.
Kódy od 0 do 31 nie sú znaky. Oni sa nazývajú riadiace znaky, pretože im umožňujú vykonávať určité činnosti, ako sú napr. Kódy 65 až 90 predstavujú veľké písmená. Kódy 97 až 122 sú malé písmená.
Pre tento kód sú hodnoty od 0 do 255 veľké a malé písmená, čísla, interpunkčné znamienka a ďalšie symboly. Mohlo by sa zhrnúť ako zjednodušenie abecedných a alfanumerických systémov. Tieto vstupné a výstupné kódy nám umožňujú preložiť informácie alebo údaje, ktoré rozumieme, pomocou zariadení alebo počítačov inému typu pochopenia, ktoré stroj dokáže pochopiť a spracovať. S týmto kódom je veľmi ľahké previesť binárne na desatinné.
Tradične na kódovanie jedného znaku použite množstvo informácií rovnajúce sa 1 bajtu, t.j. I = 1 byte = 8 bitov. Pomocou vzorca, ktorý spája počet možných udalostí K a množstvo informácií I, môžeme vypočítať, koľko rôznych znakov možno zakódovať (za predpokladu, že znaky sú možné udalosti):
Štandardný kód Spojených štátov pre výmenu informácií. Táto širšia množina kódov vám umožňuje pridať symboly cudzích jazykov a rôzne grafické symboly. Ešte stále je nedostatok týchto alfanumerických počítačových systémov, ak máte pochybnosti alebo nápady vôbec, napíšte komentár.
Pri kódovaní, keď sú čísla, písmená alebo slová reprezentované určitou skupinou znakov, hovoria, že je zakódované číslo, písmeno alebo slovo. Skupina znakov sa nazýva kód. Digitálne dáta sú reprezentované, uložené a prenášané ako skupina binárnych bitov. Táto skupina sa tiež nazýva binárny kód. Binárny kód je reprezentovaný číslom, ako aj alfanumerickým písmom.
K = 21 = 28 = 256,
to znamená, že môžete použiť abecedu s kapacitou 256 znakov na zobrazenie textových informácií.
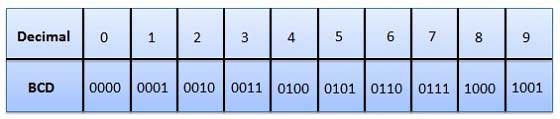
Podstatou kódovania je, že každému symbolu je priradený binárny kód od 00000000 do 11111111 alebo zodpovedajúci desatinný kód od 0 do 255.
Je potrebné pamätať na to, že v súčasnosti sa na kódovanie ruských písmen používa päť rôznych kódových tabuliek (KOI-8, CP1251, CP866, Mac, ISO) a texty zakódované jednou tabuľkou nebudú správne zobrazené v inom kódovaní. Môže sa vizualizovať ako fragment tabuľky kódovania kombinovaných znakov.
Binárne kódy robia analýzu a návrh digitálnych obvodov, ak používame binárne kódy.
Tabuľkové kódy Nevážené kódy Kodifikované desatinné binárne kódy Alfanumerické kódy Chybové kódy Chybové kódy. Tabuľkové binárne kódy sú binárne kódy, ktoré sa riadia zásadou pozičnej hmotnosti. Každá pozícia čísla predstavuje špecifickú hmotnosť.
Rôzne binárne symboly sú priradené k rovnakému binárnemu kódu.
Binárny kód Desiatkový kód KOI8 CP1251 CP866 Mac ISO
11000010 194 bV - - T
Vo väčšine prípadov sa však konverzia textových dokumentov stará o používateľa a špeciálne programy - konvertory, ktoré sú zabudované do aplikácie.
Od roku 1997 podporujú najnovšie verzie Microsoft Windows a Office nové kódovanie Unicode, ktoré každému znaku priraďuje 2 bajty, a preto nie je možné zakódovať 256 znakov, ale 65536 rôznych znakov.
V tomto type binárneho kódu nie je priradená váha polohy. Toto je nepresahujúci kód, ktorý sa používa na vyjadrenie desatinných čísel. Nadbytočné kódy sa získajú nasledovne. 
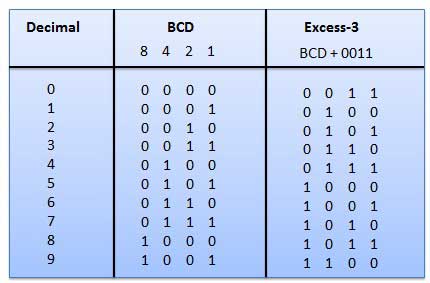
Toto je nevážený kód, a to nie sú aritmetické kódy. To znamená, že na bitovú pozíciu nie sú priradené žiadne špecifické závažia. Má veľmi špeciálnu vlastnosť, ktorá sa mení len pri každom zvýšení desatinnej čiary, ako je znázornené na obrázku. Keďže sa naraz mení iba jeden bit, kód šedej farby sa nazýva kód jednotky vzdialenosti.
Ak chcete zistiť kód číselných znakov, môžete buď použiť kódovú tabuľku, alebo pracovať v textovom editore Word 6.0 / 95. Za týmto účelom zvoľte položku ponuky "Vložiť" - "Znak", po ktorom sa na obrazovke zobrazí symbolový dialógový panel. V dialógovom okne sa zobrazí tabuľka symbolov pre vybraté písmo. Postavy v tejto tabuľke sú usporiadané riadkovo po riadku, postupne zľava doprava, začínajúc znakom Space (ľavý horný roh) a končiac s písmenom "I" (pravý dolný roh).
Sériový kód nemožno použiť na aritmetickú prevádzku. 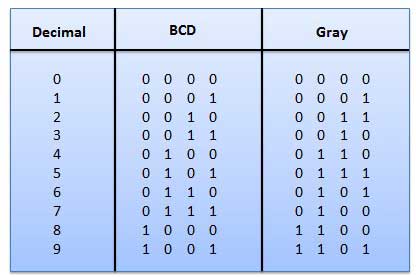
Kodér polohy polohy osi vytvára kódové slovo, ktoré predstavuje uhlové pozície osi. Šedý kód sa široko používa v systémoch merania náprav. , V tomto kóde je každé desatinné číslo reprezentované binárnym číslom 4 bitmi.
Binárne číslo alebo bit môže reprezentovať len dva znaky, pretože má iba dva stavy, 0 alebo 1. Ale to nestačí na komunikáciu medzi dvoma počítačmi, pretože nepotrebujeme viac znakov na komunikáciu. Tieto znaky musia obsahovať 26 abecedov s veľkými a malými písmenami, číslami od 0 do 9, interpunkčnými a inými znakmi.
Ak chcete zistiť číselný kód znaku zakódovaného v systéme Windows (СР1251), pomocou kurzorových kláves alebo myši vyberte požadovaný znak a potom kliknite na tlačidlo Kľúč. Potom sa na obrazovke zobrazí dialógové okno Nastavenia, v ktorom sa v ľavom dolnom rohu nachádza desatinný číselný kód vybratého znaku.
Tri prístupy k vymedzeniu pojmu "množstvo informácií"
Alfanumerické kódy sú kódy, ktoré reprezentujú čísla a abecedné znaky. V podstate tieto kódy predstavujú aj iné znaky ako symbol a rôzne pokyny potrebné na prenos informácií. Alfanumerický kód, ktorý musí obsahovať aspoň 10 číslic a 26 písmen abecedy, celkovo obsahuje 36 článkov. Nasledujúce tri alfanumerické kódy sa široko používajú na reprezentáciu údajov.
Rozšírený kódovaný desatinný binárny kód. , Existujú metódy binárneho kódu na detekciu a opravu údajov počas prenosu údajov. Než začnete učiť dekodéry, čo je veľmi podobné tomu, čo sme videli skôr, musíte si spomenúť na niektoré pojmy o binárnych kódoch.
A.P.Kolmogorov
Kombinatorický prístup
Nech je premenná x schopná brať hodnoty patriace do konečnej množiny X, ktorá pozostáva z prvkov N. Hovorí sa, že entropia premennej je
Určením určitej hodnoty x = a premennej x, túto "entropiu" odstránime a poskytneme informácie
Ak sú premenné x1, x2, ..., xk schopné nezávisle prechádzať cez súpravy, ktoré pozostávajú z prvkov N1, N2, ..., Nk, potom
Sú to sekvencie binárnych čísel, ktoré sú nejakým spôsobom usporiadané. V digitálnej elektronike existuje niekoľko kódov, existujú situácie, keď použitie jedného z nich má prednosť pred druhým. Skladá sa zo siedmich bitov, ktoré zakódujú rôzne informácie, napríklad číslo, znakové písmená, riadiace signály prenosu atď.
Kodéry a dekodéry. Zvyčajne musíme prejsť z jedného kódu do druhého. Nazýva sa to kombinačný obvod kodéra, ktorý vám umožní prejsť zo známeho kódu na neznáme a dekódovať obvod, ktorý robí opak. Na rozdiel od toho, čo bolo doteraz vidieť, je zvyčajne potrebné vykonať logickú úroveň 0 pre vstup, a tak sa uvedie pravdivostná tabuľka kodéra.
Odovzdať množstvo informácií, ktoré musím použiť
binárne znaky. Napríklad počet rôznych "slov" pozostávajúcich z k nú a jedného a dvoch je 2k (k + 1),
Preto je množstvo informácií v tomto type správy
tj aby sa "zakódovalo" takéto slová v čistom binárnom systéme je potrebné (všade, fg znamená, že rozdiel f-g je obmedzený a f ~ g, že pomer f: g má tendenciu k jednotnosti)
Vykonáva opačný proces desatinného binárneho kódovača, to znamená, že vyberie jeden z výstupov z binárneho čísla. Pravdivá tabuľka desatinnej jednotky s desatinnou čiarkou je inverzná. Na Carnotovej mape to budú irelevantné situácie.
Po zjednodušeniach s použitím Karnaughových máp sú získané nasledujúce výrazy: a zo zjednodušeného dekódovacieho obvodu výrazov. Podobne ako pri procese pozorovanom v dekodéri s binárnym desiatkovým bodom, môžete vytvoriť dekodéry, ktoré idú z ľubovoľného kódu na iný.
7-elementový displej umožňuje písať desiatkové čísla od 0 do 9 a niektoré znaky, ktoré môžu byť písmenami alebo signálmi. Nasledujúci obrázok zobrazuje všeobecnú zobrazovaciu jednotku s bežnou nomenklatúrou identifikácie segmentov v praktických príručkách.
nuly a tie. Pri prezentácii teórie informácií zvyčajne nezostávajú dlho na takom kombinatorickom prístupe k podnikaniu. Zdá sa mi však nevyhnutné zdôrazniť jeho logickú nezávislosť od akýchkoľvek pravdepodobnostných predpokladov akéhokoľvek druhu. Nechme napríklad obsadené úlohou kódovať správy napísané v abecede pozostávajúcej z písmen s a je známe, že frekvencie
Existujú dva hlavné typy LED displejov: - Spoločná katóda: segmenty svietia od 1. Spoločná anóda: segmenty svietia na úrovni 0. Pri každom čísle musia byť LED diódy navrhnuté tak, aby prijímali číslo vstupného signálu. Ak chcete tento projekt dokončiť, musíte každý symbol skontrolovať segmenty, ktoré je potrebné zapnúť, a priradiť úroveň 1 podľa príslušnej položky v binárnom kóde.
Nasledujúci obrázok znázorňuje riadok, jeho vstupný kód a úrovne použité pre každý segment. Pri zjednodušení použijeme Karnu Carnot. V tomto príklade zjednodušíme len výstupnú premennú a, pretože ostatné pristupujú k rovnakému princípu. Pamätajte, že pre každý výjazd musí byť postavená mapa Carnot.
vzhľady jednotlivých písmen v správe o dĺžke n spĺňajú nerovnosť
Preto pri prenose takýchto správ stačí použiť približne nh binárne znaky.
Univerzálna metóda kódovania, ktorá umožňuje prenášať každú dostatočne dlhú správu v abecede písmen s použitím nie viac ako nh binárnych znakov, nemusí byť príliš zložitá, najmä nemusí začínať určovaním frekvencie pr pre celú správu. Aby sme to pochopili, postačí poznamenať: prelomenie správy S do m segmentov S1, S2, ..., Sm, dostaneme nerovnosť
Treba poznamenať, že schéma môže byť optimalizovaná, pretože výrazy segmentov majú niekoľko bežných výrazov, čo vedie k používaniu menej portov. 7-elementový displej môže tiež zaznamenávať ďalšie znaky, ktoré sa často používajú v digitálnych systémoch na zastupovanie iných funkcií, ako aj na vytváranie kľúčových slov v softvéri.
V oblasti telekomunikácií a informatiky je kódovaná znaková sada kód, ktorý spája znakovú sadu abecedy s číselným vyjadrením pre každý znak tejto hry. Napríklad kód Morse je jedným z prvých kódovaných znakových sád.
Nechcem však prejsť do detailov tejto špeciálnej úlohy. Pre mňa je dôležité preukázať, že matematické problémy vyplývajúce z čisto kombinatorického prístupu k meraniu množstva informácií sa neobmedzujú na triviality.
Je úplne prirodzené mať čisto kombinačný prístup k pojmu "entropia reči", ak budeme mať na pamäti hodnotenie "flexibility" reči - ukazovateľ rozvetvenia možností pre pokračovanie prejavu v danej slovnej zásobe a daných pravidiel pre vytváranie fráz. Pre binárny logaritmus čísla N ruských tlačených textov zložených zo slov obsiahnutých v "Slovníku ruského jazyka S. I. Ozhegov a podriadených len požiadavke" gramatickej správnosti "dĺžky n, vyjadrenej v" počte znakov "(vrátane priestorov), M. Ratner a N. Svetlová dostala hodnotenie
Všetci sme dostali podivný e-mail alebo si prečítali webovú stránku ako je táto. Aj keď je to menej časté, často sa objavujú frázy, v ktorých niektoré znaky nahrádzajú iné, ktoré nemajú nič spoločné a ktoré zasahujú do čítania a pochopenia textu. Toto je problém kódovania a dekódovania. Osoba, ktorá píše text, používa iný štandard ako ten, ktorý používa osoba, ktorá ju číta!
Globalizácia kultúrnych a hospodárskych výmen zdôraznila, že európske jazyky koexistujú s mnohými inými jazykmi s konkrétnymi abecedami alebo dokonca bez abecedy. Rozsiahle používanie internetu vo svete preto vyžaduje oveľa väčší počet symbolov, ktoré treba brať do úvahy. Každému znaku sa priradí názov, regulačná pozícia a stručný popis, ktorý bude rovnaký bez ohľadu na použitú počítačovú platformu alebo softvér. Aktivita - kódovanie a internet.
Je to výrazne viac ako horné odhady "entropie literárnych textov" získané pomocou rôznych metód "hádania pokračovania". Tento rozpor je úplne prirodzený, keďže literárne texty podliehajú nielen požiadavke "gramatickej správnosti.
Je ťažšie odhadnúť kombinatorickú entropiu textov podliehajúcich určitým obmedzeniam obsahu. Bolo by zaujímavé napríklad vyhodnotiť entropiu ruských textov, ktoré možno považovať za dostatočne presné preklady daného textu v cudzom jazyku. Iba prítomnosť takejto "reziduálnej entropie" umožňuje uskutočniť veršové preklady, kde je možné presne vypočítať "náklady na entropiu" po zvolenom merači a charakter rýmovania. Možno preukázať, že klasická štyri-pitch rhymed iambic s niektorými prirodzenými obmedzeniami frekvencie "prenosov" atď. Vyžaduje predpoklad slobody liečby slovným materiálom charakterizovaným "zostatkovou entropiou" približne 0,4 (s vyššie uvedenou podmienenou metódou merania dĺžky textu počet znakov vrátane prázdnych polí "). Ak na druhej strane vezmeme do úvahy, že štylistické obmedzenia žánru pravdepodobne znížia vyššie uvedené hodnotenie "plnej" entropie z 1,9 na nie viac ako 1,1-1,2, potom sa situácia stáva pozoruhodnou tak v prípade prekladu, tak a v prípade pôvodnej básnickej tvorivosti.
Otvorte internetový prehliadač. Zmeňme to a zvoľte Strednú Európu. Zobrazia sa malé, nepríjemné znaky. Akonáhle zmeníte parameter pohonu, zobrazí sa nekompatibilita. Pomocou webového prehliadača a prechodu na "Zobraziť", "Zdroj" získame nasledujúce.
Maják Zoberme do úvahy typický príklad svetla vyžarovaného námorným majákom: je to prvý nedeliteľný, jeho výrobné náklady nezávisia od počtu užívateľov, majú nekonkurenčný majetok, ale nie je vylúčené, pretože nie je možné vylúčiť používateľa z používania, aj keď tento neprispieva k jeho financovaniu.
Nech môj čitateľov s utilitárskou mysľou odpúšťa tento príklad. V odôvodnení poznamenávam, že širší problém hodnotenia množstva informácií, ktoré sa zaoberá tvorivou ľudskou činnosťou, má veľký význam.
Teraz uvidíme, do akej miery umožňuje čisto kombinačný prístup odhadnúť "množstvo informácií" obsiahnutých v premennej x vzhľadom na premennú y, ktorá je s ňou spojená. Spojenie medzi premennými x a y, ktoré prebiehajú v súbore X a Y, spočíva v tom, že nie všetky páry x, y, ktoré patria k priamemu produktu X.Y, sú "možné". Súbor možných dvojíc U je definovaný pre akýkoľvek aX, súbor Ya je ten y, pre ktorý
Je prirodzené definovať podmienenú entropiu rovnosťou
(kde N (Yx) je počet prvkov v množine Yx) a informácie v x vzhľadom na y-vzorec
Napríklad v prípade, ktorý je uvedený v tabuľke, máme
Je zrejmé, že H (y | x) a I (x: y) sú funkcie x (zatiaľ čo y je zahrnuté do ich označenia vo forme "pripojenej premennej").
V čisto kombinačnom koncepte je ľahko predstaviť myšlienku "množstva informácií potrebných na špecifikáciu objektu x so špecifikovanými požiadavkami na presnosť". (Pozri v tejto súvislosti rozsiahlu literatúru o "e-entropii" súborov v metrických priestoroch.)
samozrejme,
2 Pravdepodobnostný prístup
Príležitosti pre ďalší rozvoj teórie informácií založené na definíciách 5 a 6 zostali v tieni, pretože dané premenné x a y charakter "náhodných premenných" s určitým spoločným rozdelením pravdepodobnosti nám umožňujú získať oveľa bohatší systém konceptov a vzťahov. Súčasne s množstvami uvedenými v § 1 máme tu
Napriek tomu sú HW (y | x) a IW (x: y) funkcie x. Existujú nerovnosti
rovnocenné s rovnomernosťou zodpovedajúcich rozdelení (na X a Yx). Množstvá IW (x: y) a I (x: y) nie sú spojené s určitou nerovnosťou znakov. Rovnako ako v § 1,
Ale rozdiel je v tom, že je možné vytvoriť matematické očakávania MHW (y | x), MIW (x: y) a
charakterizuje "tesnosť spojenia" medzi x a y symetricky.
Treba však poznamenať, že v pravdepodobnostnom koncepte vzniká jediný paradox: hodnota I (x: y) v kombinatorickom prístupe je vždy negatívna, čo je prirodzené v naivnom pojme "množstvo informácií", hodnota IW (x: y) negatívne. Skutočnou mierou "množstva informácií" je teraz len priemerná hodnota IW (x, y).
Pravdepodobnostný prístup je prirodzený v teórii prenosu prostredníctvom komunikačných kanálov "masových" informácií pozostávajúcich z veľkého množstva nesúvisiacich alebo slabo prepojených správ, ktoré podliehajú určitým pravdepodobnostným vzorom. V takýchto veciach je miešanie pravdepodobností a frekvencií v rámci jednej dostatočne dlhej časovej série (čo je prísne odôvodnené hypotézou o dostatočne rýchlom "miešaní") prakticky neškodné a zakorenené v aplikovanom výskume. Možno prakticky zvážiť napríklad otázku "entropie" prúdu gratulačných telegramov a "kapacity" komunikačného kanála potrebného pre včasný a nenarušený prenos, správne nastavený vo svojej pravdepodobnej interpretácii a bežnou náhradou pravdepodobností empirickými frekvenciami. Ak je tu nejaká nespokojnosť, potom je spojená s určitou nejasnosťou našich pojmov týkajúcich sa vzťahov medzi teóriou matematickej pravdepodobnosti a skutočnými "náhodnými javmi vo všeobecnosti.
Ale aký je skutočný význam, napríklad hovoriť o "množstve informácií" obsiahnutom v texte "vojny a mieru"? Môžeme rozumne zahrnúť tento román do všetkých "možných románov" a dokonca predpokladať prítomnosť určitého rozdelenia pravdepodobnosti v tomto súbore? Alebo by sa mali považovať jednotlivé scény "vojny a mieru" za náhodnú sekvenciu s "stochastickými väzbami", ktoré skôr rýchlo vyblednú vo vzdialenosti niekoľkých stránok?
V podstate módny výraz "množstvo dedičných informácií potrebných, napríklad povedať, na reprodukciu jedinca kukučky" nie je menej temné. Opäť v rámci prijatej pravdepodobnostnej koncepcie sú možné dve možnosti. V prvej variante sa zvažuje súhrn "možných typov" s neznámym miestom rozdelenia pravdepodobnosti na tomto agregáte 2<100 бит!).).
V druhom variante sa charakteristické vlastnosti formulára považujú za súbor slabo prepojených náhodných premenných. V prospech druhej možnosti je možné citovať úvahy založené na skutočnom mechanizme mutačnej variability. Tieto úvahy sú však iluzórne, ak predpokladáme, že v dôsledku prirodzeného výberu vzniká systém konzistentných charakteristických vlastností druhu.
3 Algoritmický prístup
V podstate je najvýznamnejšia myšlienka množstva informácií "v niečom (x) a" niečom "(y). Nie je to náhoda, že v pravdepodobnostnom koncepte sa zovšeobecňovala na kontinuálne premenné, pre ktoré je entropia nekonečná, ale v mnohých prípadoch samozrejme.
Skutočné predmety, ktoré sa majú študovať, sú veľmi komplexné, ale spojenia medzi dvoma skutočne existujúcimi objektmi sú vyčerpané jednoduchším, schematizovaným opisom. Ak nám geografická mapa poskytne významné informácie o časti zemského povrchu, potom mikroštruktúra papiera a farby nanášanej na papier nemá nič spoločné s mikroštruktúrou znázornenej plochy zemského povrchu.
Prakticky nás zaujíma najmä množstvo informácií v individuálnom objekte x vo vzťahu k jednotlivému objektu y. Je však vopred jasné, že takýto individuálny odhad množstva informácií môže mať primeraný obsah iba v prípade dostatočne veľkého množstva informácií. Nemá žiaden zmysel napríklad spýtať sa na množstvo informácií v poradí číslic 0 1 1 0 týkajúcich sa poradia 1 1 0 0. Ak však vezmeme veľmi špecifickú tabuľku náhodných čísel zvyčajného objemu v štatistickej praxi a zapíšeme pre každú z jej číslic číslicu svojich štvorcových jednotiek podľa schémy
potom nová tabuľka bude obsahovať približne
informácie o origináli (n - počet číslic v stĺpcoch).
V súlade s tým, čo bolo práve povedané, navrhovaná ďalšia definícia hodnoty IA (x: y) si zachová určitú neistotu. Rôzne ekvivalentné varianty tejto definície povedú k hodnotám ekvivalentným len v zmysle IA1-AIA2, t.j.
kde konštantný CA1A2 závisí od dvoch základných možností definovania univerzálnych programovacích metód A1 a A2.
Budeme uvažovať o "očíslovanej oblasti objektov", t.j. počítateľná množina X = (x), ktorej každý prvok je priradený ako "číslo" n (x) konečnú sekvenciu núl a tie, počnúc jedným. Označme l (x) dĺžku sekvencie n (x). Budeme to predpokladať
1) zhoda medzi X a množinou D binárnych sekvencií opísaného typu je jedna k druhej;
2) DX, funkcia n (x) na D je všeobecná rekurzívna a pre xD
kde C je určitá konštanta;
3) spolu s x a y v X, existuje usporiadaná dvojica (x, y), číslo tejto dvojice je všeobecná rekurzívna funkcia čísel x a y a
kde Cx závisí len od x.
Nie všetky tieto požiadavky sú významné, ale uľahčujú prezentáciu. Konečný výsledok konštrukcie je invariantný vzhľadom na prechod na nové číslovanie n "(x), ktoré má rovnaké vlastnosti a je vyjadrené všeobecne rekurzívne cez starú a s ohľadom na zahrnutie systému X do rozsiahlejšieho systému X" (za predpokladu, že čísla n " systém prvkov pôvodného systému je zakrytý pôvodnými číslami n.) Pri všetkých týchto transformáciách zostávajú nové "ťažkosti" a množstvá informácií rovnocenné s pôvodnými číslami v zmysle ≈
"Relatívna zložitosť" objektu y pre dané x je minimálna dĺžka l (p) programu p na získanie y od x. Takto definovaná definícia závisí od "metódy programovania. Programovacia metóda nie je nič viac ako funkcia φ (p, x) = y, priradením objektu y programu p a objektu x.
V súlade s názormi všeobecne uznávanými v modernej matematickej logike by sa funkcia φ mala považovať za čiastočne rekurzívnu. Pre každú takúto funkciu predpokladáme
V tomto prípade sa funkcia υ = φ (u) uX s hodnotami υX nazýva čiastočne rekurzívna, ak je generovaná čiastočne rekurzívnou konverznou číselnou funkciou
Aby sme pochopili definíciu, je dôležité poznamenať, že čiastočne rekurzívne funkcie vo všeobecnosti nie sú všade definované. Neexistuje žiadny pravidelný proces na zistenie, či sa program p ponechá na objekt x na akýkoľvek výsledok alebo nie. Preto funkcia Kφ (y | x) nemusí byť efektívne vypočítaná (všeobecne rekurzívna) aj vtedy, keď je určite konečná pre všetky x a y.
Binárne kódovanie textových informácií. Rôzne cyrilické kódovanie
Od konca šesťdesiatych rokov sa počítače čoraz viac používajú na spracovávanie textových informácií a väčšina osobných počítačov na svete (a väčšinu času) je zaneprázdnená spracovaním textových informácií.
Tradične sa na kódovanie jedného znaku používa množstvo informácií rovnajúce sa 1 bajt, t.j. / = 1 byte = 8 bitov.
Ak vezmeme do úvahy znaky ako možné udalosti, potom môžeme vypočítať, koľko rôznych znakov možno zakódovať:
Takýto počet znakov je dostatočný na to, aby reprezentoval textové informácie vrátane veľkých a malých písmen ruskej a latinskej abecedy, čísel, znakov, grafických symbolov atď.
Kódovanie znamená, že každému znaku je priradený jedinečný desatinný kód od 0 do 255 alebo jeho zodpovedajúci binárny kód od 00000000 do 11111111. Osoba teda rozlišuje medzi znakmi podľa ich štýlu a počítačom - podľa ich kódu.
Keď zadáte textové informácie do počítača, je kódovaný binárne, obraz znaku sa prevádza na binárny kód. Užívateľ stlačí kláves s symbolom na klávesnici - a zadá špecifický sled ôsmich elektrických impulzov (binárny znakový kód) do počítača. Kód znaku je uložený v pamäti RAM počítača, kde sa nachádza jedna bunka.
Pri procese zobrazovania znaku na obrazovke počítača sa vykoná opačný proces - dekódovanie, to znamená konverzia znakového kódu na jeho obraz.
Je dôležité, aby priradenie špecifického kódu k symbolu bolo záležitosťou dohody, ktorá je pevne stanovená v tabuľke kódov. Prvých 33 kódov (od 0 do 32) označuje nie znaky, ale operácie (line feed, vstup medzery atď.).
Kódy 33 až 127 sú medzinárodné a zodpovedajú latinskej abecede, číslam, znakom aritmetických operácií a interpunkčným znamienkam.
Kódy od 128 do 255 sú národné, to znamená, že v národných kódovaniach rôzne symboly zodpovedajú rovnakému kódu. Bohužiaľ v súčasnosti existuje päť rôznych kódových tabuliek pre ruské písmená (KOI-8, CP1251, CP866, May, ISO), takže texty vytvorené v jednom kódovaní sa nebudú správne zobrazovať v inom kódovaní.
Každé kódovanie je definované vlastnou kódovou tabuľkou. Rôzne symboly sú priradené k rovnakému binárnemu kódu v rôznych kódoch.
Nedávno sa objavil nový medzinárodný štandard Unicode, ktorý prideľuje nie jeden bajt, ale dva znaky pre každý znak, a preto ho možno použiť na zakódovanie nie 256 znakov, ale rôznych znakov.

Ako viete, elektrické napätie by malo mať svoje vlastné opatrenie, ktoré na začiatku zodpovedá hodnote, ktorá ...

Uhlie je prvé fosílne palivo, ktoré človek začal používať. V súčasnosti ako nosič energie ...

Tepelné relé sú elektrické zariadenia, ktorých hlavným účelom je chrániť motor pred nadmerným ...

Pracovný plán: Úvod Štruktúra atómu uhlíka, šírenie v prírode, výroba uhlíka, fyzikálne a chemické ...
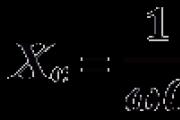
Elektrické množstvo, ktoré charakterizuje vlastnosť materiálu na zabránenie toku elektrického prúdu. V ...

Ampere zákon je jedným z najdôležitejších a najužitočnejších zákonov v elektrotechnike, bez ktorého vedecké a technické ...
Technologická schéma jadrovej elektrárne závisí od typu reaktora, typu chladiva a moderátora, ako aj od množstva ďalších ...
Zvyčajne sa záporné desatinné čísla automaticky konvertujú na obrátené alebo ...
Informatics and ICT Grade 8 Workbook Bosova LL 2012 Odpovede, Informatics a ICT Grade 8 Workbook ...

Light / Elektromery a meranieSeptember 1 Mosenergosbyt vyžaduje prenos dát každý mesiac ...

S príchodom technických prostriedkov na ukladanie a prenos informácií sa objavili nové myšlienky a techniky kódovania ...
C (karbón), nekovový chemický prvok skupiny IVA (C, Si, Ge, Sn, Pb) periodického systému ...

Vyčerpanie uhľovodíkových palív, degradácia životného prostredia a rad ďalších dôvodov skôr alebo neskôr ...
Najprv sa zamyslite nad základnou a všeobecnou otázkou pre skúmané problémy: zistite, na čom závisí ...
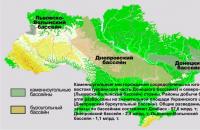
Antracit (grécka anthrax - uhlie), tuhé, vysokohustotné, lesklé uhlie obsahujúce viac ako 90% uhlíkových ...
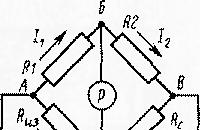
Elektrické zariadenia sa pravidelne podrobujú skúškam, ktoré sledujú ciele kontroly súladu ...