Áramerősség és feszültség számítása
Mint tudják, az elektromos feszültségnek meg kell felelnie a saját mércéjének, amely kezdetben megegyezik azzal a ...
A szöveg egyes karakterein végzett fő művelet - a karakterek összehasonlítása.
A karakterek összehasonlításakor a legfontosabb szempontok a kód egyediségét minden egyes karakterre és ennek a kódnak a hossza, és maga a kódolási elv megválasztása kevéssé értékes.
A szövegek kódolásához különböző konverziós táblázatokat használva. Fontos, hogy ugyanazt a táblázatot használjuk ugyanazon szöveg kódolásánál és dekódolásánál.
Ezért az első szakaszban a 8 bites kód kiterjesztése közel van. Számos olyan feladat létezik, amely egyes nyelvek igényeihez igazodik. Ismét több ellenőrzőjel is létezik, beleértve az áttörhetetlen helyet és egy puha kötőjelet. Mivel minden karakter most három byte-ot igényel, általában egy byte helyett, a Unicode karakterek művészettel kódoltak.
Az alábbiakban csak a kódolás magyarázatára korlátozzuk magunkat. Ebben az esetben 1, 2 és 3 bájtos érték fordul elő. Általában 4 bájt is lehetséges. Így a nyugati nyelven írt szövegek nagymértékben elolvashatók a tényleges kódolástól függetlenül. Ezenkívül a leggyakoribb karakterek kódolása helytakarékos.
A transzkódolási táblázat egy olyan táblázat, amely bizonyos formájú kódolt karakterek listáját tartalmazza, amely szerint a karakter átalakul bináris kódjává és fordítva.
A legnépszerűbb konverziós táblák: DKOI-8, ASCII, CP1251, Unicode.
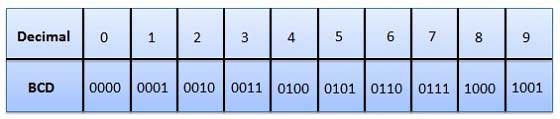
Történelmileg 8 bitet vagy 1 bájtot választottak a kódolási hosszúságnak a karakterek kódolásához. Ezért a számítógépen tárolt szöveg egy karaktere leggyakrabban egy memória bájtnak felel meg.
Ha a vezető bit 1, akkor ez egy több bájtos kód. A tizenegy megfelelő bájtot két bájt adja ki, amint az a következő példában látható. A kétbájtos kódok példái az alábbiakban látható második és harmadik kódtáblázatban láthatók. Sok más kódot találtak fel, például Emile Bodo.
A telefonvonalak segítettek olyan telepkulcsok fejlesztésében, amelyek képesek kódolni és dekódolni a Bodo kódban szereplő karaktereket. A karaktereket 5 bitben kódolták, tehát csak 32 karakter volt. Lehetővé teszi, hogy legfeljebb 7 karaktert kódoljon, és legfeljebb 8 bitig tartson, tehát 256 lehetséges karaktert tartalmaz.
Különböző 0 és 1 kombinációk kombinációi 8 bites kódhosszal lehetnek 28 = 256, ezért egy konverziós táblázat segítségével legfeljebb 256 karaktert kódolhat. Kód hosszúsága 2 byte (16 bites), 65 536 karakter kódolható.
Jelenleg a legtöbb felhasználó számítógépet használ szöveges információk feldolgozására, amely szimbólumokat tartalmaz: betűk, számok, írásjelek stb.
A 0 és 31 közötti kódok nem karakterek. Ezeket ellenőrző karaktereknek nevezzük, mivel lehetővé teszik számukra bizonyos műveletek végrehajtását, például a vonalszakaszok és az audió visszajátszását. A 65-90. Kódok nagybetűket tartalmaznak. A 97 és 122 kódok kisbetűk.
Ehhez a kódhoz 0 és 255 közötti értékek nagybetűk, kisbetűk, számok, írásjelek és más szimbólumok. Leírható az alfanumerikus és alfanumerikus rendszerek egyszerűsítésére. Ezek a belépési és kilépési kódok lehetővé teszik számunkra, hogy lefordítsuk azokat az információkat vagy adatokat, amelyeket az eszközök vagy számítógépek használatával értünk egy másikfajta megértéshez, amelyet a gép meg tudja érteni és feldolgozni. Ezzel a kóddal nagyon könnyen átalakítható bináris tizedesre.
Hagyományosan, egyetlen karakter kódolásához használja az 1 bájtnak megfelelő információ mennyiségét, azaz I = 1 bájt = 8 bit. Ha olyan képletet használunk, amely összekapcsolja az esetleges K események számát és az I információ mennyiségét, kiszámíthatjuk, hogy hány különböző karakter kódolható (feltételezve, hogy a karakterek lehetséges események):
Az Egyesült Államok kódja az információcserére. Ez a szélesebb kódkészlet lehetővé teszi idegen nyelvű szimbólumok és különböző grafikus szimbólumok hozzáadását. Nos, még mindig hiányzik ezek az alfanumerikus számítógépes rendszerek, ha kétségei vagy ötletei egyáltalán, írj egy megjegyzést.
Kódoláskor, amikor számokat, betűket vagy szavakat egy bizonyos karaktercsoport képvisel, azt mondják, hogy egy szám, egy betű vagy egy szó kódolt. A karaktercsoportot kódnak nevezik. A digitális adatokat a bináris bitek csoportjaként ábrázolják, tárolják és továbbítják. Ezt a csoportot bináris kódnak is nevezik. A bináris kódot egy szám, valamint egy alfanumerikus betű képviseli.
K = 2I = 28 = 256,
vagyis 256 karakteres ábécé segítségével jelenítheti meg a szöveges információkat.
A kódolás lényege, hogy minden szimbólum bináris kódot kap 00000000-tól 11111111-ig vagy a megfelelő decimális kódot 0-tól 255-ig.
Nem szabad megfeledkezni arról, hogy jelenleg öt különböző kódtáblázatot (KOI-8, CP1251, CP866, Mac, ISO) használnak orosz betűk kódolására, és az egyik táblázattal kódolt szövegek nem jelennek meg helyesen más kódolásban. A kombinált karakterkódolási táblázat töredéként jeleníthető meg.
A bináris kódok digitális áramkörök elemzését és tervezését végzik, ha bináris kódokat használunk.
Táblázatkódok Nem súlyozott kódok Kodifikált Decimális bináris kód Alfanumerikus kódok Hibakódok Hibakódok. Tabuláris bináris kódok bináris kódok, amelyek követik a pozíció súlyát. Minden szám pozíció egy adott súlyt képvisel.
Különböző bináris szimbólumok vannak ugyanarra a bináris kódra.
Bináris kód Decimális kód KOI8 CP1251 CP866 Mac ISO
11000010 194 bV - - T
Azonban a legtöbb esetben a szöveges dokumentumok átalakítása gondoskodik a felhasználóról és az alkalmazásba beépített speciális programokról - átalakítókról.
1997 óta a Microsoft Windows és Office legújabb verziói támogatják az új Unicode kódolást, amely 2 bájtot rendel minden egyes karakterhez, ezért nem 256 karakter, de 65536 különböző karakter kódolása lehetséges.
Ebben a bináris kódban a pozíció súlya nincs hozzárendelve. Ez a számozás nélküli kód, amelyet a decimális számok kifejezésére használnak. A túl-3 kódokat az alábbiak szerint állítjuk be. 
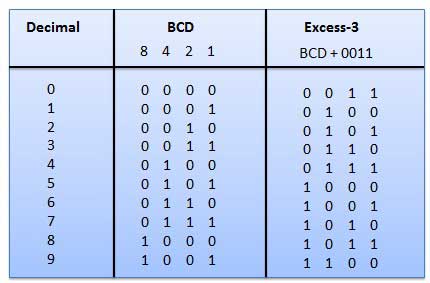
Ez egy súlyozatlan kód, és ezek nem aritmetikai kódok. Ez azt jelenti, hogy nincsenek meghatározott súlyok a bitpozícióhoz. Nagyon különleges jellemzője, hogy csak akkor változik meg, amikor a decimális érték növekszik, ahogy az az ábrán látható. Mivel egyszerre csak egy bit változik, a szürke színkódot a távolságegység kódnak nevezik.
A numerikus karakterkód meghatározásához használhatja a kódtáblát, vagy a Word 6.0 / 95 szövegszerkesztőben. Ehhez válassza a "Insert" - "Character" menüpontot, majd a Symbol párbeszédpanel megjelenik a képernyőn. A kijelölt betűtípus szimbólum táblázata megjelenik a párbeszédpanelen. A táblázatban szereplő karakterek egymás után balról jobbra, egymás után sorba rendezve, a "Space" karakterrel kezdődnek (bal felső sarok) és a "I" betűvel (jobb alsó sarokban).
A soros kódot nem lehet számtani műveletekhez használni. 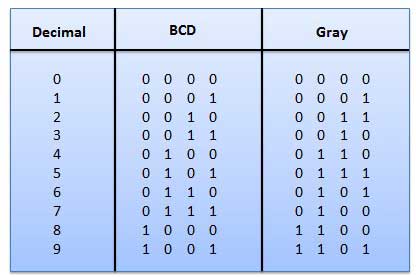
A tengely pozíció kódolója olyan kódszót hoz létre, amely a tengely szöghelyzetét mutatja. A szürke kódot széles körben használják a tengelymérési rendszerekben. . Ebben a kódban minden tizedesjegyet 4 bites bináris szám képvisel.
A bináris szám vagy bit csak két karaktert képviselhet, mivel csak két állapotban van, 0 vagy 1. De ez nem elég két számítógép közötti kommunikációhoz, mivel nem szükséges több karakter a kommunikációhoz. Ezeknek a karaktereknek 26 betűtípust kell megadni nagybetűvel és kis betűkkel, 0-tól 9-ig terjedő számokkal, írásjelekkel és más karakterekkel.
A Windows-ban kódolt karakter számának meghatározásához (СР1251) az egérrel vagy a kurzor gombokkal válassza ki a kívánt karaktert, majd kattintson a Kulcs gombra. Ezt követően megjelenik a Beállítások párbeszédpanel, amely a bal alsó sarokban tartalmazza a kiválasztott karakter decimális számkódját.
Az "információmennyiség" meghatározásának három megközelítése
Az alfanumerikus kódok kódok, amelyek számokat és betűket jeleznek. Alapvetően ezek a kódok más karaktereket is ábrázolnak szimbólumként és az információ továbbításához szükséges különféle utasítások. Az alfanumerikus kódot, amely legalább 10 számot és 26 betűt tartalmaz, összesen 36 cikket tartalmaz. A következő három alfanumerikus kódot széles körben használják az adatok ábrázolásához.
Kiterjesztett kódolt tizedesbináris kód. . Az adatátvitel során bináris kódolási módok vannak az adatok észlelésére és kijavítására. Mielőtt elkezdi a dekódolók elsajátítását, ami nagyon hasonló ahhoz, amit korábban láttunk, emlékeznünk kell néhány fogalomra a bináris kódokról.
A.P.Kolmogorov
1 Kombinációs megközelítés
Hagyja, hogy az x változó képes legyen olyan X véges halmazhoz tartozó értékeket venni, amelyek N elemekből állnak. Azt mondják, hogy egy változó entrópiája
Az x változó x = a bizonyos értékének meghatározásával "eltávolítjuk" ezt az entrópiát, és információt szolgáltatunk
Ha az x1, x2, ..., xk változók képesek függetlenül áthaladni az N1, N2, ..., Nk elemekből álló készleteken, akkor
Ezek olyan bináris számok sorozatai, amelyeket valamilyen módon rendeltek el. A digitális elektronikában számos kód létezik, vannak olyan helyzetek, ahol egyikük előnye a másik fölött. Ez hét bitből áll, amelyek számos különböző információt kódolnak, például számot, karakter betűt, átviteli vezérlőjeleket stb.
Jeladók és dekóderek. Általában kódról a másikra kell mennünk. Ezt kódoló kombinációs áramkörnek nevezik, amely lehetővé teszi, hogy egy ismert kódról ismeretlenre mutasson és dekódolja az ellenkező irányú áramkört. Az eddig megfigyeltekkel ellentétben általában szükség van a bemeneti logikai 0 szint végrehajtására, így a kódoló igazságtábláját adják meg.
A rendelkezésre álló információk mennyiségének közvetítése
bináris karakterek. Például a k nullákból és azokból kettőből álló különböző "szavak" száma 2k (k + 1),
Ezért az ilyen típusú üzenetekben lévő információk mennyisége
azaz (mindenhol, f≈g azt jelenti, hogy az f-g különbség korlátozott, és f ~ g, hogy az f: g arány az egységig)
Végrehajtja a decimális bináris kódoló fordított folyamatát, vagyis kiválasztja az egyik kimenetet egy bináris számból. A bináris-tizedes dekódoló tényleges táblája a fenti inverze. A Carnot térképen irreleváns helyzetek lesznek.
A Karnaugh térképek egyszerűsítése után a következő kifejezéseket kapjuk; és az egyszerűsített kifejezések dekódoló áramköréből. A dekódolóban bináris tizedessel megfigyelt folyamathoz hasonlóan eljárhat olyan dekódereket is, amelyek bármilyen kódból bármi máshoz jutnak.
A 7 elemes kijelző lehetővé teszi, hogy decimális számokat írjon 0 és 9 között, és néhány karaktert, amelyek betűk vagy jelek lehetnek. Az alábbi ábrán a szokásos nómenklatúrát mutatjuk be a gyakorlati kézikönyvekben.
nullák és nullák. Az információelmélet bemutatásakor általában nem marad sokáig az ilyen kombinatorikus megközelítés az üzleti. De számomra létfontosságúnak tartom, hogy logikai függetlenségét bármilyen valószínűségi feltételezéssel hangsúlyozzam. Például elfoglaljuk az olyan betűkkel írt üzenetek kódolását, amelyek s betűből állnak, és ismert, hogy a frekvenciák
A LED-kijelzők két fő típusa létezik: - Közös katód: a szegmensek világítanak 1. Közös anód: a szegmensek 0. szinttel világítanak. Minden egyes számnál a LED-eket úgy kell kialakítani, hogy elfogadják a bemenet számát. A projekt befejezéséhez minden egyes szimbólumban ellenőrizni kell azokat a szegmenseket, amelyeknek világítaniuk kell, és az 1. szintet a bináris kód megfelelő bejegyzésének megfelelően kell megadniuk.
Az alábbi ábra mutatja a vonalat, bemeneti kódját és az egyes szegmensekre alkalmazott szinteket. Az egyszerűsítésben Karna Carnot-t fogjuk használni. Ebben a példában csak a kimeneti változót egyszerűsítjük, mivel a többiek ugyanazt az elvet követték. Ne felejtsük el, hogy minden kijáratnak Carnot térképet kell készítenie.
az egyes betűk megjelenése az n hosszúságú üzenetben kielégíti az egyenlőtlenséget
Ezért ilyen üzenetek továbbítása esetén elegendő körülbelül nh bináris karaktereket használni.
Az univerzális kódolási módszer, amely lehetővé teszi a kellően hosszú üzenet ábécéinek ábécéit, nem sokkal több, mint nh bináris karaktereket használva, nem kell túlságosan bonyolultnak lennie, és nem kell kezdenie az egész üzenet frekvenciájának meghatározására. Ennek megértéséhez elegendő megjegyezni: az S üzenet szétválasztása S1, S2, ..., Sm szegmensekbe, megkapjuk az egyenlőtlenséget
Meg kell jegyeznünk, hogy a rendszer optimalizálható, mivel a szegmensek kifejezéseinek számos közös feltétele van, ami kevesebb port használatát eredményezi. A 7 elemes kijelző más olyan karaktereket is rögzíthet, amelyeket gyakran használnak a digitális rendszerekben más funkciók megjelenítésére, valamint kulcsszavak létrehozására a szoftverben.
A távközlésben és a számítástechnikában a kódolt karakterkészlet olyan kód, amely az ábécé karakterkészletét egy numerikus reprezentációval köti össze a játék minden egyes karakterével. Például a Morse kód az egyik első kódolt karakterkészlet.
Azonban nem akarok beleavatkozni a különleges feladat részleteibe. Csak számomra fontos megmutatni, hogy az információ mennyiségének tisztán kombinatorikus megközelítéséből származó matematikai problémák nem korlátozódnak a trivialitásokra.
Természetes, hogy a "beszéd entrópia" fogalmát tisztán kombinatorikus megközelítésnek tekintjük, ha figyelembe vesszük a beszéd "rugalmasságának" felmérését - amely egy adott szókincsben a beszéd folytatásának lehetőségeinek szétválasztását és a kifejezések létrehozására vonatkozó szabályokat tartalmaz. Az orosz nyelvű "Ozhegov" Szójegyzékben szereplő szavakból álló orosz nyelvű nyomtatott szövegek számának bináris logaritmusa, és csak az "n" hosszúságú "grammatikai korrektúra" követelményének alárendelt, "karakterek száma" (beleértve a szóközöket is) M. Ratner és N. Svetlova értékelést kapott
Mindannyian furcsa e-mailt kaptunk, vagy egy ilyen weblapot olvastunk. Bár ez kevésbé gyakoribb, néha megjelennek olyan kifejezések is, amelyekben egyes karaktereket helyettesítenek mások, amelyeknek nincs semmi közük, és amelyek zavarják a szöveg olvasását és megértését. Ez egy kódolási és dekódolási probléma. A szövegíró személy eltérő szabványt használ, mint az olvasó által használt személy.
A kulturális és gazdasági cserék globalizálódása hangsúlyozta, hogy az európai nyelvek sok más nyelvvel együtt élnek, speciális betűkkel vagy akár ábécék nélkül. Ezért az internet széles körű használata a világon sokkal több szimbólumot igényel. Minden karakterhez nevet, szabályozási pozíciót és rövid leírást adunk, amely azonos a számítógépes platformtól vagy a használt szoftverektől függetlenül. Tevékenység - kódolás és az internet.
Ez lényegesen több, mint az "irodalmi szövegek entrópiájára" vonatkozó felső becslések, amelyeket a "folytatások kitalálása" különböző módszereivel nyertek. Ez az ellentmondás teljesen természetes, hiszen az irodalmi szövegek nem csak a "nyelvtani helyesség" követelményének vannak kitéve.
Nehéz megítélni a szövegek kombinatorikus entrópiáját bizonyos tartalomhatárok mellett. Érdekes lenne például az orosz szövegek entrópiájának értékelése, amely egy adott idegen nyelvű szöveg kellően pontos fordításának tekinthető. Csak az ilyen "maradék entrópia" jelenléte tesz lehetővé versváltozatokat, ahol pontosan kiszámítható a kiválasztott mérő követése "entrópiai költsége" és a rímző jellege. Megmutatható, hogy a klasszikus négyszögű rímszerű iambikus, az "átadások" gyakoriságával kapcsolatos természetes korlátozásokkal stb. Megköveteli, hogy a "maradék entrópiával" jellemzett verbális anyaggal való kezelés szabadságát feltételezzük, körülbelül 0,4 (a fenti feltételes módszerrel a szöveg hosszának mérésére a karakterek száma, beleértve az üres képeket is). Ha viszont figyelembe vesszük, hogy a műfaj stilisztikai korlátai valószínűleg csökkentik a fenti "teljes" entrópia értékelését 1,9-ről 1,1-1,2-re, akkor a helyzet mind a fordítás, mind a és eredeti költői kreativitás esetén.
Nyisson meg egy internetes böngészőt. Változtassuk meg ezt és válasszuk a Közép-Európát. Kis, kellemetlen karakterek jelennek meg. Amint megváltoztatja a hajtásparamétert, megjelenik az inkompatibilitás. Egy webböngészővel, és a "View", a "Source" menüpontban a következőket kapjuk.
Világítótorony Tegyünk egy tipikus példát a tengeri világítótorony által kibocsátott fényre: először oszthatatlan, termelési költsége nem függ a felhasználók számától, nem versenyképes tulajdonsággal rendelkezik, de nincs kizárva is, hiszen lehetetlen kizárni a felhasználót, még akkor is, ha az utóbbi nem járul hozzá finanszírozásához.
Engedje meg, hogy a haszonelvű olvasók megbocsátanak nekem erre a példára. Indokolásként megjegyzem, hogy nagy jelentőséggel bír a kreatív emberi tevékenységgel kapcsolatos információ mennyiségének felmérése.
Most nézzük meg, hogy a tisztán kombinatorikus megközelítés lehetővé teszi-e az x változóban található "információ mennyiségét" a hozzá tartozó y változóval kapcsolatban. Az X és Y változók és az X és Y halmazok közötti kapcsolódás abban a tényben rejlik, hogy nem minden X.Y közvetlen termékhez tartozó x, y páros "lehetséges". Az U lehetséges párokkal, bármilyen aX-re van definiálva, a Ya halmaza az y, amelyhez
Természetes, hogy a feltételes entrópia az egyenlőségen alapul
(ahol N (Yx) az Yx-ben lévő elemek száma, és az x-ben lévő információ az y-képletre vonatkoztatva
Például a táblázatban feltüntetett esetben
Nyilvánvaló, hogy H (y | x) és I (x: y) az x függvények (míg y szerepel a "kapcsolt változó" formájában).
A pusztán kombinatorikus koncepcióban könnyen beilleszthető az "információs mennyiség, ami szükséges ahhoz, hogy az objektumot x meghatározott pontossági követelményekkel" határozza meg. (Lásd erről a témáról a metrikus terekben lévő készletek "ε-entrópiájáról" szóló széleskörű irodalmat.)
nyilván,
2 Probabilisztikus megközelítés
Az (5) és (6) definíciókon alapuló információelmélet további továbbfejlesztésének lehetőségei az árnyékban maradtak, mivel az x és y változóknak a "valószínűségi változók" karaktere egy bizonyos közös valószínűségeloszlással lehetővé teszi számunkra, hogy sokkal gazdagabb fogalmi és kapcsolati rendszert kapjunk. Az 1. §-ban bevezetett mennyiségekkel párhuzamosan itt van
Mégis, a HW (y | x) és az IW (x: y) az x függvényei. Vannak egyenlőtlenségek
az egyenlõséggel a megfelelõ eloszlás egyenletességével halad (X és Yx esetén). Az IW (x: y) és I (x: y) mennyiségek nem kapcsolódnak bizonyos jelegyenlőtlenséghez. Mint az 1. §,
De a különbség az, hogy meg lehet alkotni az MHW (y | x), az MIW (x: y) és a matematikai elvárásokat
jellemzi a x és y közötti "kapcsolat szorosságát" szimmetrikusan.
Azonban érdemes megemlíteni egy paradoxon probabilista koncepciójának megjelenését: az I (x: y) értéke a kombinatorikus megközelítésben mindig nem negatív, ahogy az az "információmennyiség" naiv fogalmánál természetes, az IW (x: y) negatív. Az "információmennyiség" valós mérete ma már csak az átlagérték IW (x, y).
A valószínűségi megközelítés természetes a "tömeg" információs kommunikációs csatornákon keresztül történő továbbítás elméletében, amely nagyszámú nem kapcsolódó vagy gyengén összekapcsolt üzenetből áll, bizonyos probabilisztikus minták alapján. Ilyen esetekben a valószínűségek és a frekvenciák egy elég hosszú idősoron belüli összekapcsolása (amely eléggé indokolt a kellően gyors "keverés" hipotézise alapján) gyakorlatilag ártalmatlan és az alkalmazott kutatásban gyökerezik. Gyakorlatilag például megfontolhatjuk a gratuláló telegramok áramának "entrópiáját" és az időben és torzítás nélküli átvitelhez szükséges kommunikációs csatorna "kapacitását", amelyet probabilisztikus értelmezésben és a valószínűségek szokásos helyettesítési empirikus frekvenciái alapján fogalmaznak meg. Ha van némi elégedetlenség, akkor a matematikai valószínűségi elmélet és a valódi "véletlenszerű jelenségek" közötti összefüggésekhez kapcsolódó fogalmaink bizonyos bizonytalanságával jár.
De mi a valódi jelentése, például az "információ mennyiségéről" beszélve a "Háború és béke" szövegében? Elfogadhatjuk-e ezt a regényt a "lehetséges regények" összességében, és feltételezhető-e egy bizonyos valószínűségi eloszlás jelenléte ebben a sorozatban? Vagy a "Háború és béke" egyéni jeleneteinek véletlenszerű sorozatot kell képeznie, amely "sztochasztikus összeköttetésekkel" inkább gyorsan eltűnik több oldalról?
Lényegében nem kevésbé sötét a divatos kifejezés: "az örökletes információ mennyisége, mondjuk egy kakukk faj egyének reprodukálása". Ismét az elfogadott valószínűségi koncepción belül két lehetőség lehetséges. Az első változatban a lehetséges típusok aggregátumát tekintjük az ismeretlen aggregátum2 valószínűségeloszlásának hollandjával.2 (2A Földön létező vagy létező fajok sokasága, még a tisztán kombinatorikus számítással is, teljesen felülmúlhatatlanul kis becsléseket eredményezne<100 бит!).).
A második változatban a forma jellemző tulajdonságai gyengén egymással összekapcsolt véletlen változók csoportjának tekintendők. A második lehetőség mellett a mutációs variabilitás valódi mechanizmusán alapuló megfontolásokra lehet hivatkozni. De ezek a megfontolások illuzórikusak, ha azt feltételezzük, hogy a természetes szelekció eredményeképpen létrejön a fajok következetes jellegzetességeinek rendszere.
3 Algoritmikus megközelítés
Lényegében a legfontosabb az információ mennyiségének eszméje "valamiben (x) és" valamiben "(y). Nem véletlen, hogy a valószínűségi koncepcióban általános volt a folyamatos változók esetében, amelyek esetében az entrópia végtelen, de természetesen számos esetben.
A valódi tárgyak, amelyeket tanulmányozni kell, nagyon (korlátlan?) Komplexek, de a két valóban létező objektum közötti kapcsolatok kimerültek, egyszerűbb, sematikus leírással. Ha egy földrajzi térkép jelentős információt ad a Föld felszínének egy részéről, akkor a papírra és a papírra alkalmazott mikroszerkezet semmi köze a földfelszín ábrázolt területének mikrostruktúrájához.
Gyakorlatilag leginkább az egyéni objektum x információinak mennyiségét érdekeljük egy adott objektumhoz viszonyítva. Azonban már előre világos, hogy az információ mennyiségének ilyen egyedi becslése ésszerű tartalma csak a kellően nagy mennyiségű információ esetében lehetséges. Nincs értelme például kérdezni az információ mennyiségét a 0 1 1 0 számjegyek sorrendjében az 1 1 0 0 sorozatra vonatkozólag. De ha a statisztikai gyakorlatban a szokásos térfogatú véletlenszerű számok nagyon konkrét táblázatot készítünk, és mindegyik számjegyére írunk egy négyzet alakú egységet a program szerint
akkor az új tábla kb
az eredeti információ (n - az oszlopok számjegyeinek száma).
Az eddigiekhez hasonlóan az IA (x: y) értékének további meghatározása bizonyos bizonytalanságot megtart. E meghatározás különböző egyenértékű változatai csak az IA1≈IA2 értelemben vett értékekhez vezetnek, azaz.
ahol az állandó CA1A2 az A1 és az A2 univerzális programozási módszerek meghatározásától függ.
Figyelembe vesszük a "tárgyak számozott területét", azaz egy megszámlálható sorozatot X = (x), amelynek minden egyes elemét "n" számhoz hozzárendeljük n (x) egy véges nulla és egy zérus sorozathoz, kezdve egy. Jelölje l (x) az n (x) sor hosszát. Ezt feltételezzük
1) a leírt típusú bináris szekvenciák X és D halmaza közötti egyezés egy-egy;
2) DX, a D funkció n (x) a D általános rekurzív, és az xD esetében
ahol C egy bizonyos állandó;
3) x-vel és y-val együtt X-ben, van egy rendezett páros (x, y), ennek a párnak az száma az x és y számok általános rekurzív függvénye
ahol a Cx csak x-től függ.
Ezeknek a követelményeknek nem mindegyike jelentős, de elősegítik a prezentációt. Az építés végeredménye az új "n" (x) számozásra való áttérés tekintetében invariáns, amely ugyanazokkal a tulajdonságokkal rendelkezik, és általában rekurzív módon fejeződik ki a régien keresztül, és az X rendszer kiterjesztése a kiterjedtebb X-rendszerbe (feltételezve, hogy az "n" az eredeti rendszer elemeinek rendszere el van fedve az eredeti n számmal.) Mindezen átalakításoknál az új "nehézségek" és az információmennyiségek az eredetiekhez hasonlóan ≈
Az y objektum "relatív bonyolultsága" egy adott x számára a p program minimális hossza (p), hogy megkapjuk y-t x-ből. Az így megfogalmazott definíció a "programozási módtól" függ. A programozási módszer nem más, mint a φ (p, x) = y függvény, az y objektum hozzárendelése a p programhoz és az x objektumhoz.
A modern matematikai logikában általánosan elfogadott nézetekkel összhangban a φ függvényt részleges rekurzívnak kell tekinteni. Bármelyik ilyen funkciót feltételezzük
Ebben az esetben az uX υ = φ (u) függvényt υX értékekkel részlegesen rekurzívnak nevezzük, ha azt egy részleges rekurzív számkonverziós függvény
A definíció megértése érdekében fontos megjegyezni, hogy a részleges rekurzív funkciók általában nem mindenhol definiáltak. Nincs rendszeres folyamat annak megállapítására, hogy a p program alkalmazása az x objektumra bármely eredményre, vagy sem. Ezért a Kφ (y | x) függvénynek nem kell hatékonyan kiszámítható (általános rekurzív) akkor is, ha minden x és y esetén véges.
A szöveges információ bináris kódolása. Különböző cirill kódolások
Az 1960-as évek vége óta a számítógépek egyre inkább felhasználásra kerültek a szöveges információk feldolgozására, és most a világ (és az idő nagy részében) a személyi számítógépek többsége el van foglalva a szöveges információk feldolgozását.
Hagyományosan egy karakter kódolásához az 1 bájtnak megfelelő információ mennyiségét használjuk, azaz / = 1 bájt = 8 bit.
Ha a karaktereket lehetséges eseményeknek tekintjük, akkor kiszámíthatjuk, hogy hány különböző karakter kódolható:
Olyan számú karakter elég ahhoz, hogy szöveges információkat jelenítsen meg, beleértve az orosz és a latin ábécé nagybetűket és kisbetűket, számokat, jeleket, grafikus szimbólumokat stb.
A kódolás az, hogy minden egyes karakter egy egyedi tizedes kód 0-tól 255-ig vagy annak megfelelő bináris kódja 00000000-tól 11111111-ig kerül hozzárendelésre. Így egy személy a stílusuk és a számítógépük szerinti karaktereket különbözteti meg - kódjuk szerint.
Amikor szöveges adatokat ad meg a számítógépbe, bináris kódolású, a karakter képe átalakul bináris kódjává. A felhasználó megnyom egy billentyűt a billentyűzeten lévő szimbólummal - és nyolc elektronikus impulzus (bináris karakterkód) meghatározott sorrendje lép be a számítógépbe. A karakterkód a számítógép RAM memóriájában tárolódik, ahol egyetlen cellát foglal el.
A számítógép képernyőjén lévő karakterek megjelenítésének folyamata során fordított eljárást hajtanak végre - dekódolás, vagyis egy karakterkód átalakítása a képbe.
Fontos, hogy egy adott kód hozzárendelése egy szimbólumhoz megállapodás tárgya, amelyet a kódtáblázatban rögzítenek. Az első 33 kód (0-tól 32-ig) nem karaktereket, hanem műveleteket (vonalátvitel, helybevitel stb.) Jelöl.
A 33-tól 127-ig terjedő kódok nemzetköziek, és megfelelnek a latin betűnek, a számoknak, a számtani műveleteknek és az írásjeleknek.
A 128-tól 255-ig terjedő kódok országosak, vagyis a nemzeti kódolásban a különböző szimbólumok ugyanazt a kódot jelölik. Sajnos jelenleg 5 különböző kódtáblázat található az orosz betűkhöz (KOI-8, CP1251, CP866, május, ISO), így az egyik kódolással létrehozott szövegek nem fognak megfelelően megjelenni a másikban.
Minden kódolást saját kódtáblája határoz meg. Különböző szimbólumokat rendelnek ugyanarra a bináris kódra különböző kódolásokban.
A közelmúltban megjelent egy új nemzetközi szabvány Unicode, amely nem egyetlen bájtot ad ki, hanem két karaktert minden egyes karakterhez, ezért nem 256 karakter, de különböző karakterek kódolására használható.

Mint tudják, az elektromos feszültségnek meg kell felelnie a saját mércéjének, amely kezdetben megegyezik azzal a ...

A szén az első fosszilis üzemanyag, amelyet az ember elkezdett használni. Jelenleg energiahordozóként ...

A termikus relék olyan elektromos eszközök, amelyek fő célja a motor túlzott védelme ...

Munkaterv: Bevezetés A szén szerkezete, a disszemináció a természetben, a széntermelés, a fizikai és kémiai ...
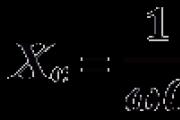
Elektromos mennyiség, amely az anyag tulajdonságát jellemzi az elektromos áram áramlását. In ...

Amper törvénye az egyik legfontosabb és leghasznosabb villamosmérnöki törvény, amely nélkül tudományos és műszaki ...
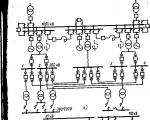
Az atomerőmű technológiai rendszere a reaktor típusától, a hűtőfolyadék típusától és a moderátor típusától, valamint számos egyéb ...
Általában a negatív decimális számok automatikusan átalakulnak fordított vagy ...
Informatika és IKT 8. fokozatú munkafüzet Bosova LL 2012 Válaszok, Informatika és IKT 8. fokozatú munkafüzet ...

Fény / Elektromosságmérők és mérésSeptember 1. A Mosenergosbyt minden hónapban adatátvitelt igényel ...

Az információk tárolásával és továbbításával kapcsolatos technikai eszközök megjelenésével új ötletek és kódolási technikák jöttek létre ....
C (karboneum), az időszakos rendszer IVA (C, Si, Ge, Sn, Pb) nem fémes kémiai eleme

A szénhidrogén-üzemanyagok kimerülése, a környezeti romlás és számos egyéb ok előbb-utóbb ...
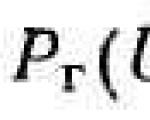
Először is, fontoljuk meg az alapvető és általános kérdést a vizsgált problémákra: megtudjuk, mi függ attól ...
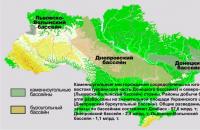
Antracit (görög Ανθραξ - szén), Szilárd, nagy sűrűségű, fényes szén, amely több mint 90% szén-dioxidot tartalmaz ...
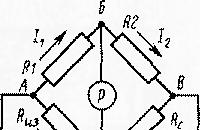
Az elektromos berendezéseket rendszeresen olyan vizsgálatoknak vetik alá, amelyek a megfelelés ellenőrzésének célkitűzéseit követik ...